关于js渲染网页时爬取数据的思路和全过程(附源码)
于js渲染网页时爬取数据的思路
首先可以先去用requests库访问url来测试一下能不能拿到数据,如果能拿到那么就是一个普通的网页,如果出现403类的错误代码可以在requests.get()方法里加上headers.

如果还是没有一个你想要的结果,打印出来 的只是一个框架,那么就可以排除这方面了。就只可能是ajax或者是javascript来渲染的。
就可以按照下图去看一下里面有没有
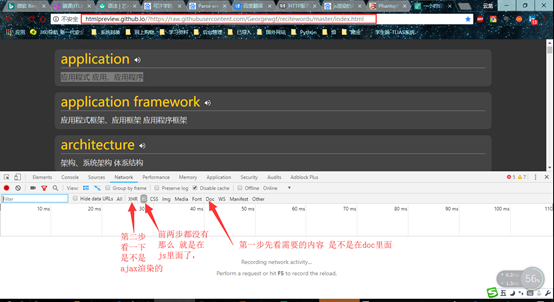
本次先重点去讲一下关于js来渲染网页的数据爬取,这下面的数据是随机找的,只要是里面想要爬取的数据就行 了。
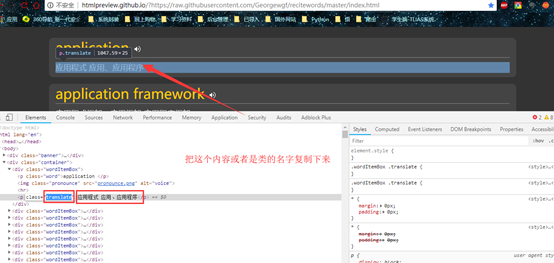
这里ctrl+f就可以搜索到了说明就是在这个js的文件里面
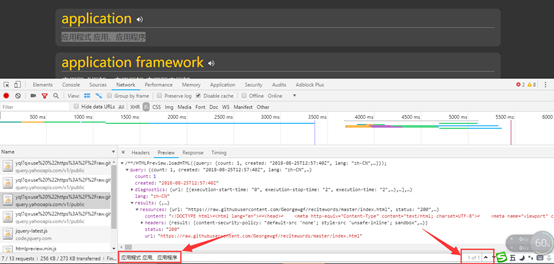
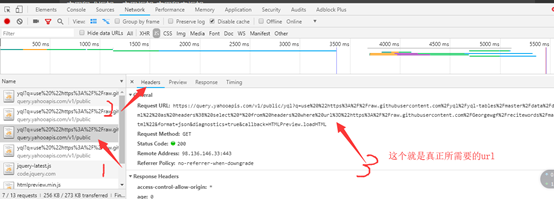

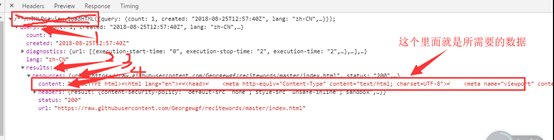
这个就是真正的数据。
剩下的就是可以利用xpath,beautifulsoup或者pyquery来解析得到的网页源码就可以了。
这里我个人推荐此处用pyquery比较方便简单一些。
另附上源码给大家:
import json
from pyquery import
PyQuery as pq
import requests
requests.get()
# 利用爬虫来获取关于程序员的600个单词
def get_web_page():
'''
分析网页,得到结果是一个js渲染的网页,利用requests来把js中的真正的url传递
过来,利用字符串的操作来得到一个真正的json数据
:return: html源码
'''
# 从网上找的一个url地址
url = 'https://query.yahooapis.com/v1/public/yql?q=use%20%22https%3A%2F%2Fraw.githubusercontent.com%2Fyql%2Fyql-tables%2Fmaster%2Fdata%2Fdata.headers.xml%22%20as%20headers%3B%20select%20*%20from%20headers%20where%20url%3D%22https%3A%2F%2Fraw.githubusercontent.com%2FGeorgewgf%2Frecitewords%2Fmaster%2Findex.html%22&format=json&diagnostics=true&callback=HTMLPreview.loadHTML'
# 页面分析得到源码
res = requests.get(url)
json_loads = json.loads(res.text.lstrip('/**/HTMLPreview.loadHTML(').rstrip(');'))
html = json_loads['query']['results']['resources']['content']
# print(html)
return html
def parse_web_page(html):
'''
根据传递过来的网页源码来通过pyquery模块来得到需要的数据
:param html: 网页的源码
:return: 所需要的内容,单词和翻译
'''
# 把网页源码放到pyquery解析器中
doc = pq(html)
# 根据class为wordItemBox的来筛选需要的内容块并得到一个生成器来为了方便下面数据的遍历
contents = doc('.wordItemBox').items()
# 把需要的数据遍历并得到真正的内容
for temp
in contents:
word = temp('.word').text()
translate = temp('.translate').text()
# 返回数据
return word, translate
def main():
'''利用爬虫来获取关于程序员的600个单词'''
# 得到的网页源码
html = get_web_page()
# 解析网页得到需要的数据
content = parse_web_page(html)
# 打印需要的数据
print(content)
if __name__ == '__main__':
main()
关于js渲染网页时爬取数据的思路和全过程(附源码)的更多相关文章
- Python实训day07pm【Selenium操作网页、爬取数据-下载歌曲】
练习1-爬取歌曲列表 任务:通过两个案例,练习使用Selenium操作网页.爬取数据.使用无头模式,爬取网易云的内容. ''' 任务:通过两个案例,练习使用Selenium操作网页.爬取数据. 使用无 ...
- 【Android初级】利用startActivityForResult返回数据到前一个Activity(附源码+解析)
在Android里面,从一个Activity跳转到另一个Activity.再返回,前一个Activity默认是能够保存数据和状态的.但这次我想通过利用startActivityForResult达到相 ...
- AJAX载入外部JS文件到页面并让其执行的方法(附源码)
一. 向HTML页面中动态添加JS文件(从外部载入)并让其执行的两种方法 1.只适用于IE浏览器的简单方法: 先在文档中放置一张JS"空床"并添加ID:<script id= ...
- 如何用JS/HTML将时间戳转换为“xx天前”的形式【附源码,转
如果我们有一份过去时间戳,如何使用JS/HTML将时间戳转换为"xx天前"的形式呢,以下是完整代码 <!DOCTYPE html> <html> <h ...
- arcgis api 3.x for js 入门开发系列十四最近设施点路径分析(附源码下载)
前言 关于本篇功能实现用到的 api 涉及类看不懂的,请参照 esri 官网的 arcgis api 3.x for js:esri 官网 api,里面详细的介绍 arcgis api 3.x 各个类 ...
- arcgis api 4.x for js 自定义叠加图片图层实现地图叠加图片展示(附源码下载)
前言 关于本篇功能实现用到的 api 涉及类看不懂的,请参照 esri 官网的 arcgis api 4.x for js:esri 官网 api,里面详细的介绍 arcgis api 4.x 各个类 ...
- Java基于POI实现excel任意多级联动下拉列表——支持从数据库查询出多级数据后直接生成【附源码】
Excel相关知识点 (1)名称管理器--Name Manager [CoderBaby]首先需要创建多个名称(包含key及value),作为下拉列表的数据源,后续通过名称引用.可通过菜单:&quo ...
- Java爬取同花顺股票数据(附源码)
最近有小伙伴问我能不能抓取同花顺的数据,最近股票行情还不错,想把数据抓下来自己分析分析.我大A股,大家都知道的,一个概念火了,相应的股票就都大涨. 如果能及时获取股票涨跌信息,那就能在刚开始火起来的时 ...
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
随机推荐
- Django中模板语音变量forloop
forloop.counter 从1开始 forloop.counter0 从0开始 forloop.revcounter 倒序(表示循环中剩余项的整型变量.) forloop.revcount ...
- 【Math for ML】线性代数之——向量空间
I. Groups 在介绍向量空间之前有必要介绍一下什么Group,其定义如下: 注意定义中的\(\bigotimes\)不是乘法,而是一种运算符号的统一标识,可以是乘法也可以是加法等. 此外,如果\ ...
- [转] ElasticSearch 常用的查询过滤语句
备忘remark https://www.cnblogs.com/ghj1976/p/5293250.html query 和 filter 的区别请看: http://www.cnblogs.co ...
- iframe教程
有关iframe的最强大的强大的教程 $(window.parent.document).contents().find("#tab_release"+taskId2+" ...
- 虚拟机CentOS7下NAT模式的网络配置
NAT模式 就是让Guest OS借助NAT(网络地址交换)功能,通过Host OS所在的网络来访问公网.也就是说,使用NAT模式可以实现Guest OS轻松访问互联网,可以访问宿主计算机所在网络的其 ...
- Python 编程核心知识体系(REF)
Python 编程核心知识体系: https://woaielf.github.io/2017/06/13/python3-all/ https://woaielf.github.io/page2/
- js垃圾回收(转
和C#.Java一样JavaScript有自动垃圾回收机制,也就是说执行环境会负责管理代码执行过程中使用的内存,在开发过程中就无需考虑内存分配及无用内存的回收问题了.JavaScript垃圾回收的机制 ...
- 使用Fiddler进行手机端抓包
1.手机和电脑在同一局域网 2.在电脑上查看ip地址 3.如果是需要抓取https,则需要在浏览器中输入http://xxx.xxx.x.xxx:8888(第二部查到的ip地址 + Fiddler 的 ...
- Ubuntu18系统qt生成程序无法双击运行问题
1.Ubuntu18 安装qt编译生成的程序文件类型为application/x-sharedlib,无法双击直接运行.文件类型应该为x-executable. 2.解决方法 在.pro文件中添加下面 ...
- ROM、PROM、EPROM、EEPROM、FLASH ROM简介
ROM指的是"只读存储器",即Read-Only Memory.这是一种线路最简单半导体电路,通过掩模工艺, 一次性制造,其中的代码与数据将永久保存(除非坏掉),不能进行修改.这玩 ...