一脸懵逼学习Hdfs---动态增加节点和副本数量管理(Hdfs动态扩容)
1:按照上篇博客写的,将各个进程都启动起来:
集群规划:
主机名 IP 安装的软件 运行的进程
master 192.168.3.129 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
slaver1 192.168.3.130 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
slaver2 192.168.3.131 jdk、hadoop ResourceManager
slaver3 192.168.3.132 jdk、hadoop ResourceManager
slaver4 192.168.3.133 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
slaver5 192.168.3.134 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
slaver6 192.168.3.135 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
2:开始测试动态增加节点和副本数量管理:
首先将master节点的datanode挂掉(即少了一个保存文件的副本):
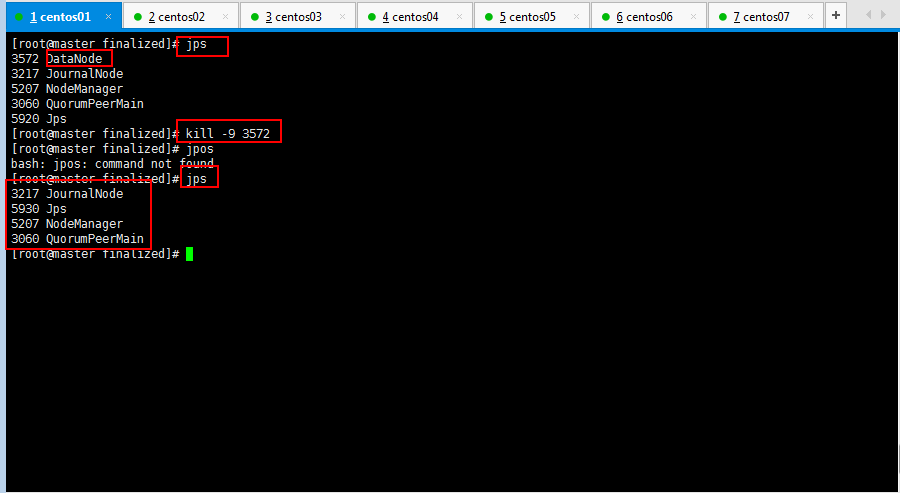
注意:hadoop datanode节点超时时间设置:
datanode进程死亡或者网络故障造成datanode无法与namenode通信,
namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。
HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的:
heartbeat.recheck.interval的单位为毫秒,
dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
hdfs-site.xml中的参数设置格式:
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property>
注意:HDFS冗余数据块的自动删除:
在日常维护hadoop集群的过程中发现这样一种情况:
某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡,
HDFS马上自动开始数据块的容错拷贝;
当该节点重新添加到集群中时,由于该节点上的数据其实并没有损坏,
所以造成了HDFS上某些block的备份数超过了设定的备份数。
通过观察发现,这些多余的数据块经过很长的一段时间才会被完全删除掉,
那么这个时间取决于什么呢?
该时间的长短跟数据块报告的间隔时间有关。
Datanode会定期将当前该结点上所有的BLOCK信息报告给Namenode,
参数dfs.blockreport.intervalMsec就是控制这个报告间隔的参数。
hdfs-site.xml文件中有一个参数:
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>10000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
其中3600000为默认设置,3600000毫秒,即1个小时,也就是说,块报告的时间间隔为1个小时,所以经过了很长时间这些多余的块才被删除掉。通过实际测试发现,当把该参数调整的稍小一点的时候(60秒),多余的数据块确实很快就被删除了。
3:停止一下集群,配置一下hadoop datanode节点超时时间设置和HDFS冗余数据块的自动删除,停止集群如下所示:
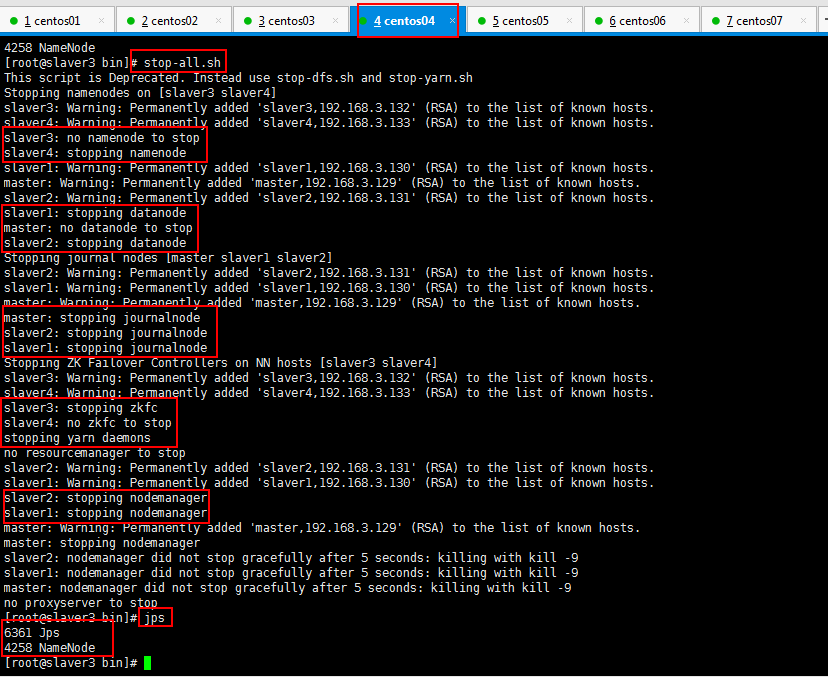
依次查看一下各个节点的进程启动情况:
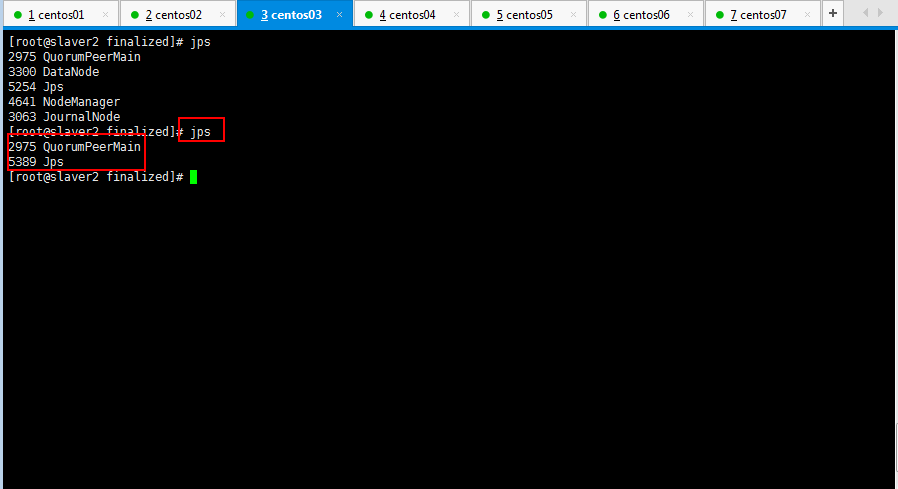

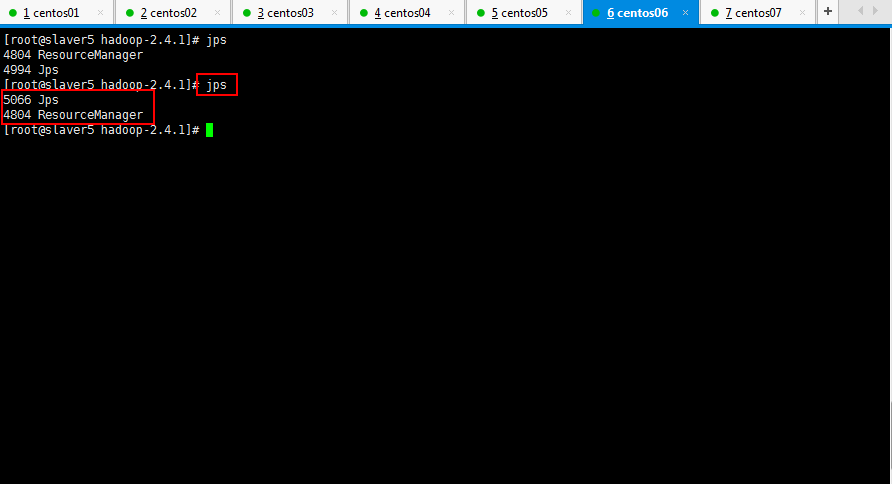
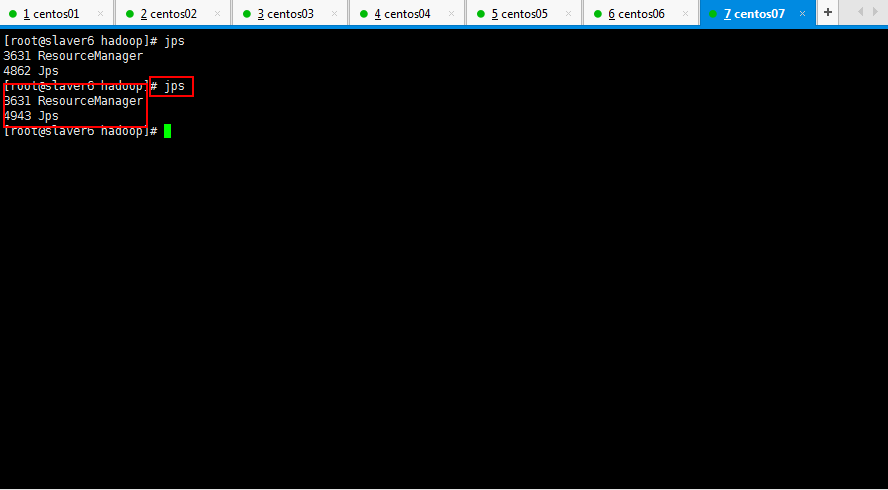
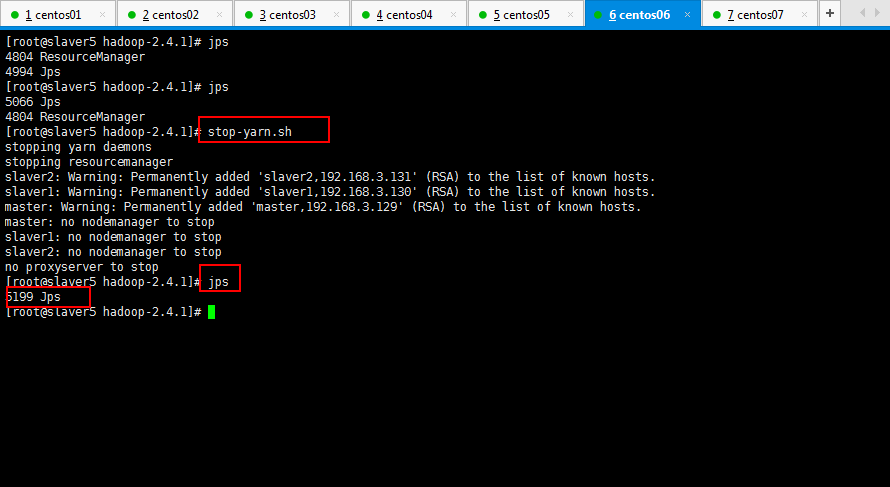
然后将slaver5和slaver6的yarn进程停掉:
然后依次关掉zookeeper的进程:如master,slaver1和slaver2都一样,这里不再重复了:
[root@master bin]# ./zkServer.sh stop
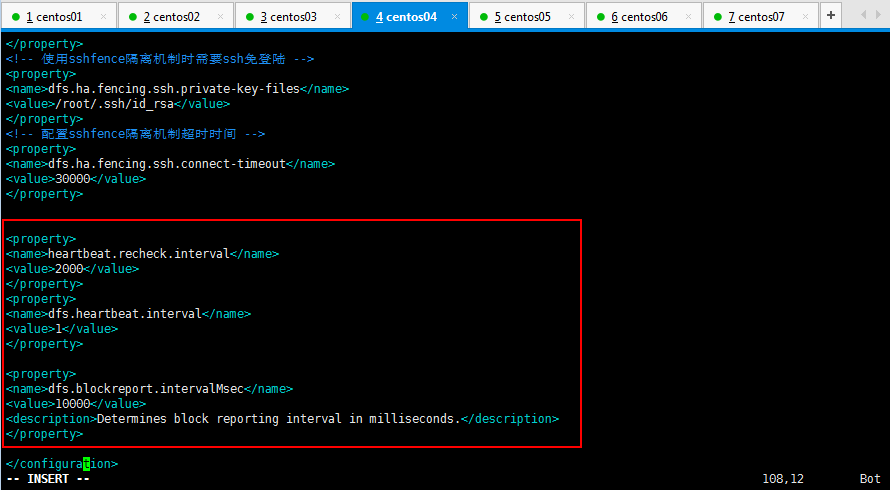
现在修改配置一下:hadoop datanode节点超时时间设置和HDFS冗余数据块的自动删除的配置文件hdfs-site.xml:
hadoop datanode节点超时时间设置
hdfs-site.xml中的参数设置格式: <property>
<name>heartbeat.recheck.interval</name>
<value></value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value></value>
</property>
HDFS冗余数据块的自动删除
hdfs-site.xml文件中有一个参数: <property>
<name>dfs.blockreport.intervalMsec</name>
<value>10000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
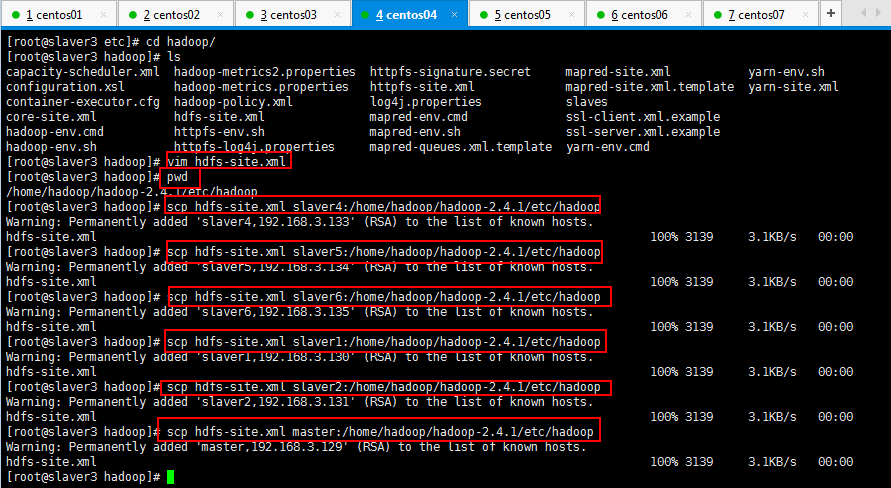
操作如下所示:
[root@slaver3 hadoop]# vim hdfs-site.xml
将修改的hdfs-site.xml复制到其他6个节点上面,如下所示:
4:将集群启动起来:
4.1:启动zookeeper集群(分别在master、slaver1、slaver2上启动zookeeper):
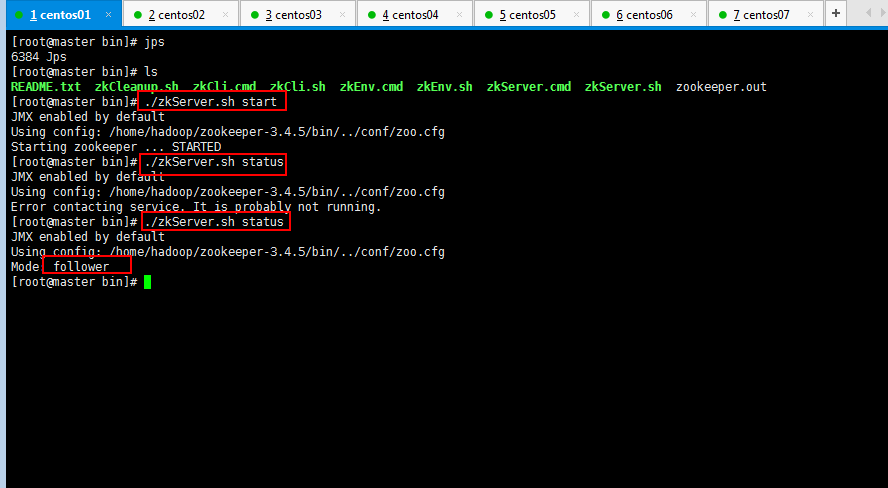
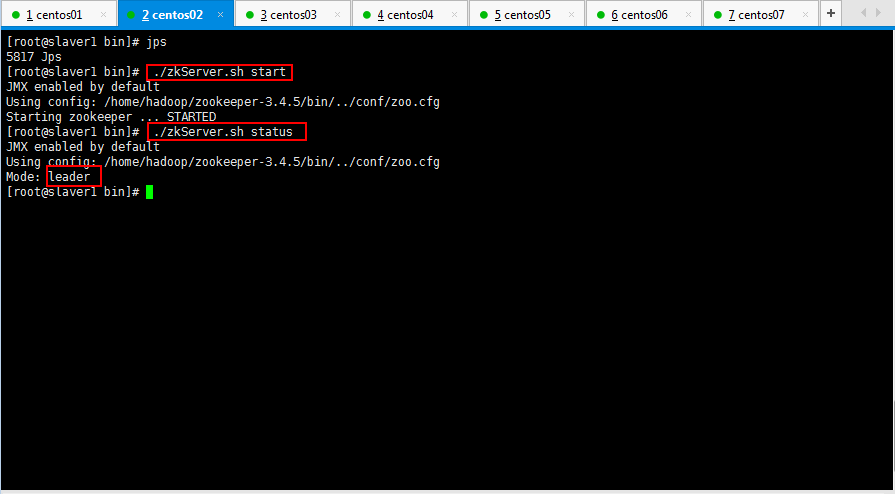

4.2:启动journalnode(分别在master、slaver1、slaver2上执行)
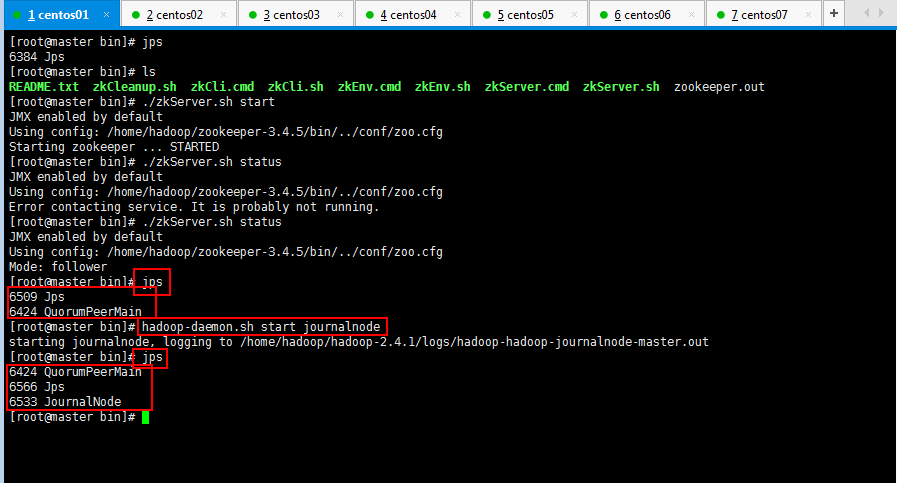
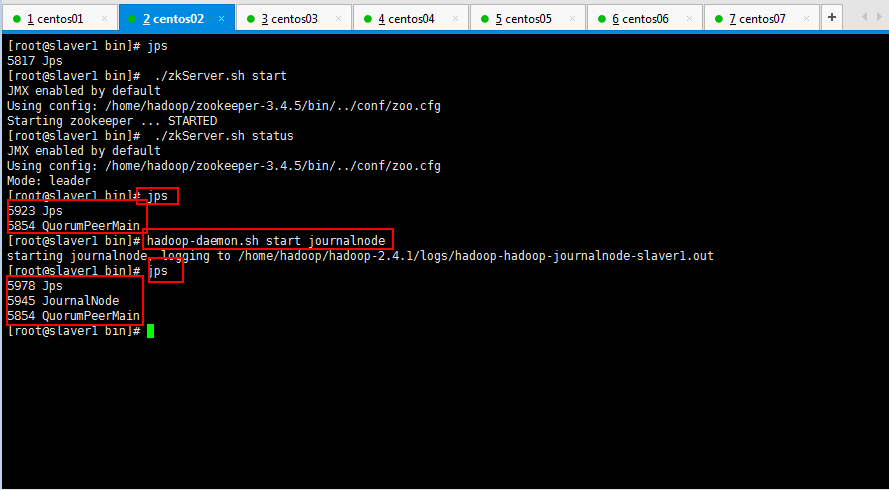

4.3:千万不要执行格式化HDFS,千万不要执行格式化ZKFC(在slaver3上执行即可),不然还是报很多错误;
4.4:然后在slaver3启动start-dfs.sh
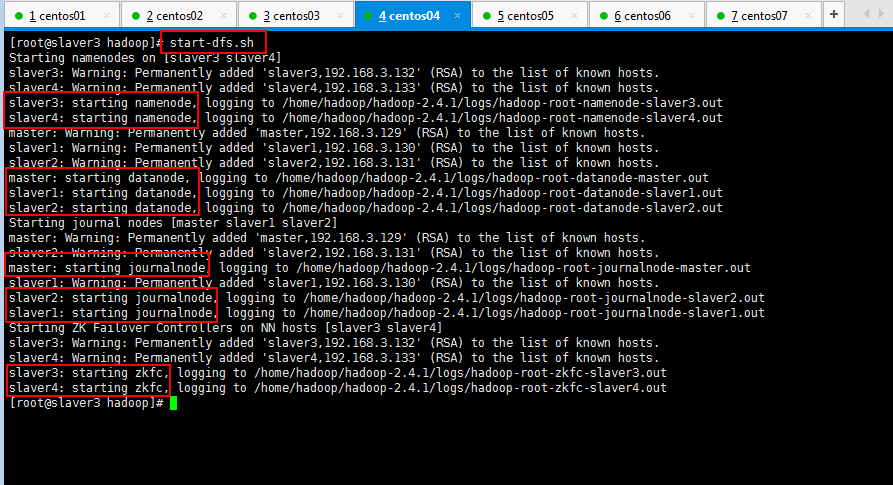
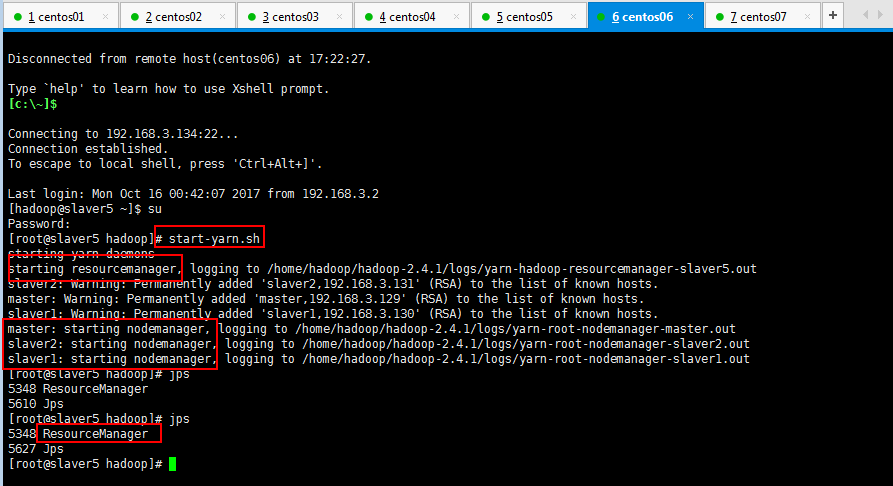
现在可以去其他节点看看,全部进程都可以正常启动,如果你想启动yarn进程,下面启动yarn进程,slaver5节点和slaver6节点操作一样,这里只贴slaver5即可:
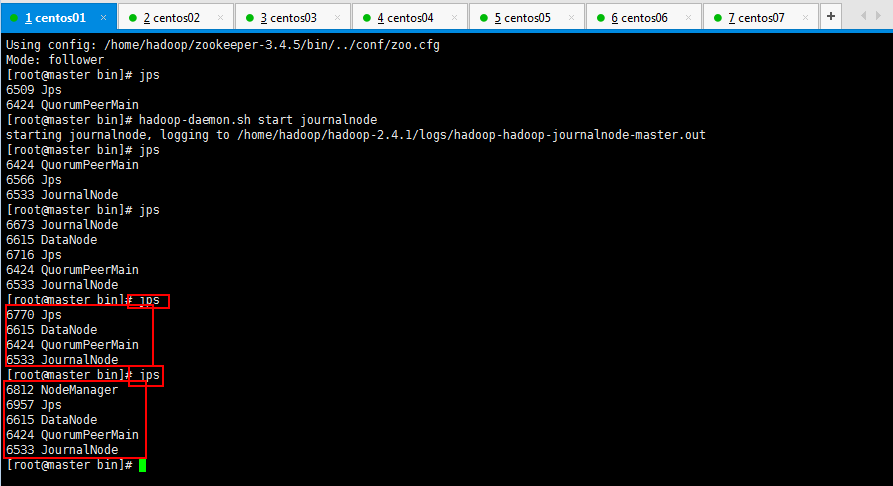
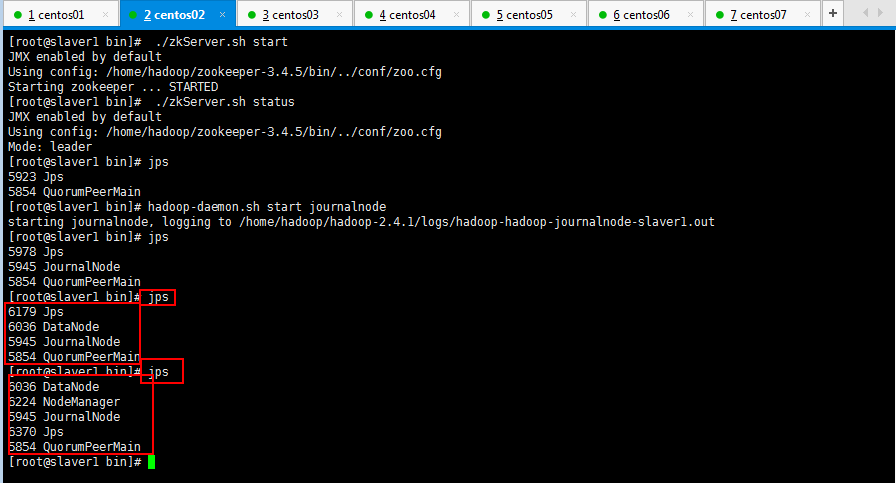
如果你耐心十足,搞了一天,想吐,这里还是再贴一下jps查看的进程情况吧:
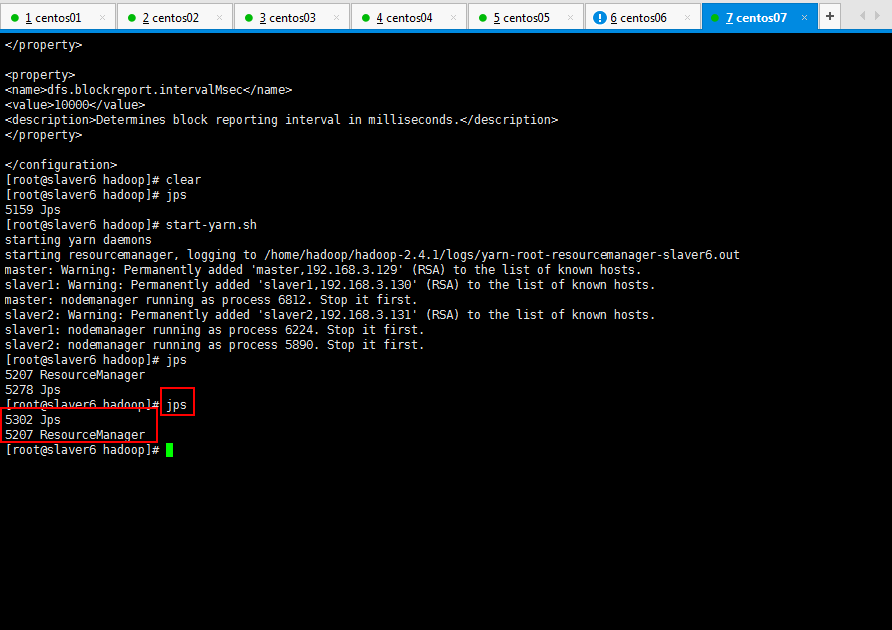
5:然后将master的namenode干掉,看看Live Nodes是否变化:

经过14s后,活着的node数目就由3变成了2:

如何新加一个datanode,再搞一个虚拟机(我再新建一个虚拟机,不知道我的电脑撑住撑不住,试试吧先),然后将hadoop的安装包复制过去,然后将datanode启动起来:好吧,最后没有弄出来,以后有机会好好补一下这点,动态增加节点和副本数量管理;
补充要点:
注意:hdfs动态扩容要点,将手动启动节点:
hadoop-daemon.sh start namenode 启动namenode
hadoop-daemon.sh start datanode 启动datanode.
即可以动态加入,只不过没写到slavers里面,下次重启以后,手动加入即可完成动态扩容了。
一脸懵逼学习Hdfs---动态增加节点和副本数量管理(Hdfs动态扩容)的更多相关文章
- 5 weekend01、02、03、04、05、06、07的分布式集群的HA测试 + hdfs--动态增加节点和副本数量管理 + HA的java api访问要点
weekend01.02.03.04.05.06.07的分布式集群的HA测试 1) weekend01.02的hdfs的HA测试 2) weekend03.04的yarn的HA测试 1) wee ...
- Hyperledger fablic 1.0 在centos7环境下的安装与部署和动态增加节点
Hyperledger fablic 1.0 在centos7环境下的安装与部署和动态增加节点 一.安装docker 执行代码如下: curl -sSL https://get.daocloud.io ...
- ZooKeeper动态增加Server(动态增加节点)的研究(待实践)
说明:是动态增加Server,不是动态增加连接到ZK Server的Client. 场景如下(转自外文): 1.在t=t_1->[peer-1(Leader),peer-2],peer-1是主节 ...
- (二)Kafka动态增加Topic的副本(Replication)
(二)Kafka动态增加Topic的副本(Replication) 1. 查看topic的原来的副本分布 [hadoop@sdf-nimbus-perf ~]$ le-kafka-topics.sh ...
- 一脸懵逼学习hadoop之HDFS的java客户端编写
1:eclipse创建一个项目,然后导入对应的jar包: 鼠标右击项目,点击properties或者alt+enter快捷键--->java build path--->libraries ...
- 一脸懵逼学习Hadoop中的序列化机制——流量求和统计MapReduce的程序开发案例——流量求和统计排序
一:序列化概念 序列化(Serialization)是指把结构化对象转化为字节流.反序列化(Deserialization)是序列化的逆过程.即把字节流转回结构化对象.Java序列化(java.io. ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- Hadoop2.6.0 动态增加节点
本文主要从基础准备,添加DataNode和添加NodeManager三个部分详细说明在Hadoop2.6.0环境下,如何动态新增节点到集群中. 基础准备 在基础准备部分,主要是设置hadoop运行的系 ...
- Hadoop动态增加节点与删除节点
Hadoop的全分布式安装网上也很多教程,踩过很多坑,整理不出来了……赶紧把增加删除节点留住. 均衡数据 (1)设置数据传输带宽为64M(默认值比较低) hdfs dfsadmin -setBalan ...
随机推荐
- 【转】python操作excel表格(xlrd/xlwt)
[转]python操作excel表格(xlrd/xlwt) 最近遇到一个情景,就是定期生成并发送服务器使用情况报表,按照不同维度统计,涉及python对excel的操作,上网搜罗了一番,大多大同小异, ...
- X86架构
在接触BIOS的时候,都需要对PC架构有一定的认知.目前的PC架构绝大多数都是Intel的X86架构,貌似也是因为INTEL的这个X86架构早就了目前INTEL如日中天的地位. 废话不多说,X86架构 ...
- ARMV7-M数据手册---Part A :Application Level Architecture---A1 Introduction
1.前言 本章主要介绍了ARMV7体系结构及其定义的属性,以及本手册定义的ARMV7M属性. 主要包括: ARMV7体系结构和属性 ARMV7M属性 ARMV7M扩展 2. ARMV7体系结构和属性 ...
- eMMC基础技术4:eMMC command
1.前言 本文主要对eMMC的command进行详细介绍,主要包含如下内容: (1)command类型 (2)command格式 2.command类型 command类型 说明 bc 不带respo ...
- 对比Dijakstra和优先队列式分支限界
Dijakstra和分支限界都是基于广度优先搜索,如果说两者都是生成一棵树,那Dijakstra总是找距离树根最近的(属于贪心算法),优先队列式分支限界是在层遍历整棵搜索树的同时剪去达不到最优的树枝. ...
- undefined reference to symbol '_ZNK11GenICam_3_016GenericException17GetSourceFileNameEv'
今天在编译DALSA二次开发的源码时,出现了如下错误: /usr/bin/ld: ./out/camera.o: undefined reference to symbol '_ZNK11GenICa ...
- 使用js下载文件
使用Echarts地图时,需要一些地图数据,到Echarts下载地图数据文件时,发现其下载是直接通过js下载,从其网站上扒下来的记录于此 FileSave.min.js网络地址:http://ecom ...
- 洛谷P3676 小清新数据结构题 [动态点分治]
传送门 思路 这思路好妙啊! 首先很多人都会想到推式子之后树链剖分+线段树,但这样不够优美,不喜欢. 脑洞大开想到这样一个式子: \[ \sum_{x} sum_x(All-sum_x) \] 其中\ ...
- Vue项目构建开发笔记(vue-lic3.0构建的)
1.router.js里面 { path: '/about', name: 'about', // route level code-splitting // this generates a sep ...
- C#实现向excel中插入行列,以及设置单元格合并居中效果
插入空行: Microsoft.Office.Interop.Excel.Workbook xlsWorkbook; Microsoft.Office.Interop.Excel.Worksheet ...