5 weekend01、02、03、04、05、06、07的分布式集群的HA测试 + hdfs--动态增加节点和副本数量管理 + HA的java api访问要点
weekend01、02、03、04、05、06、07的分布式集群的HA测试
1) weekend01、02的hdfs的HA测试
2) weekend03、04的yarn的HA测试
1) weekend01、02的hdfs的HA测试

首先,分布式集群都是正常的,且工作的



然后呢,
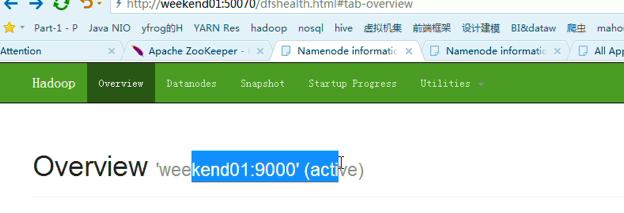


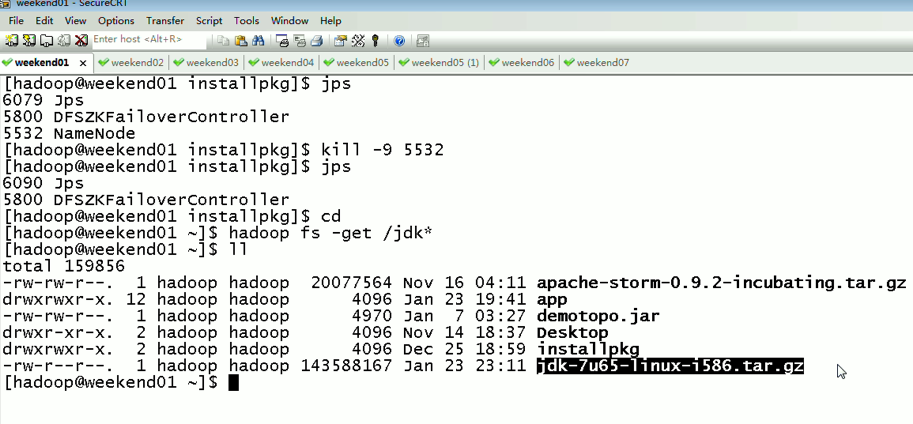
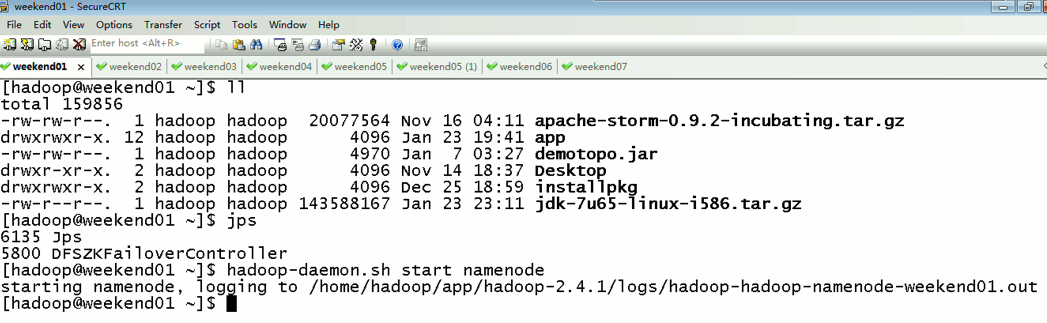
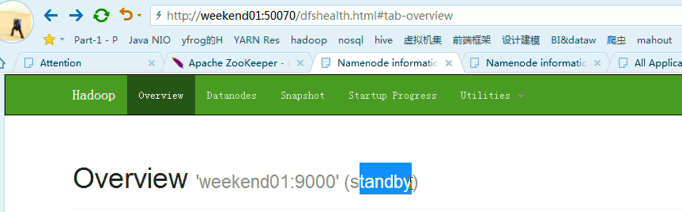
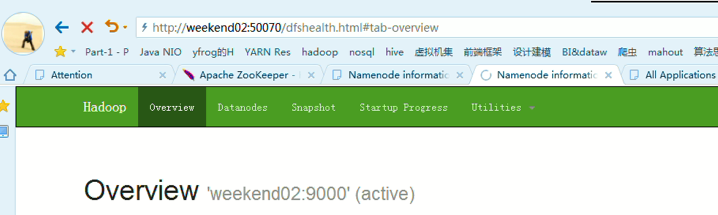
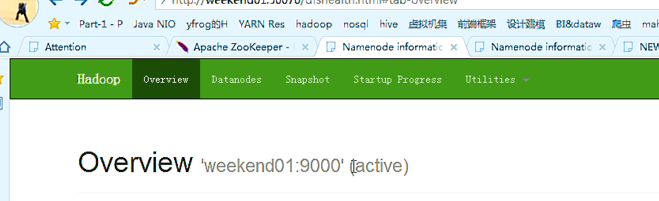
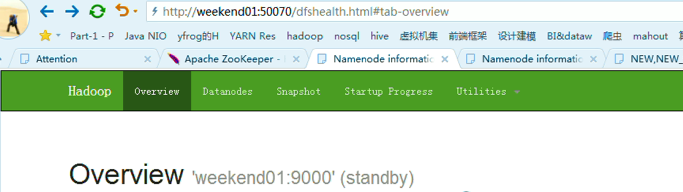
以上是,weekend01(active)、weekend02(standby)
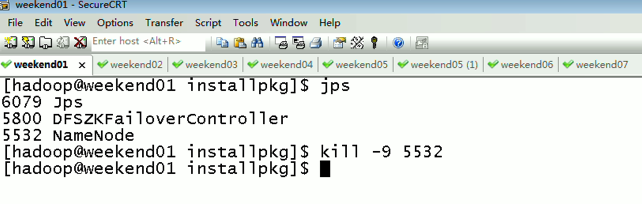
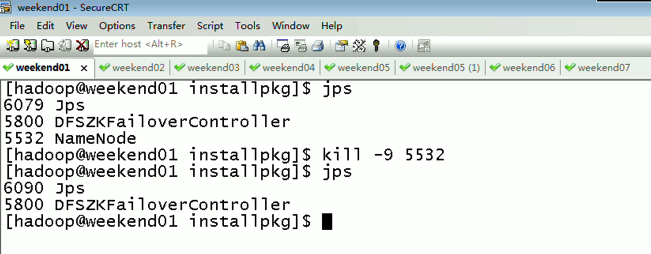
当weekend01给kill,
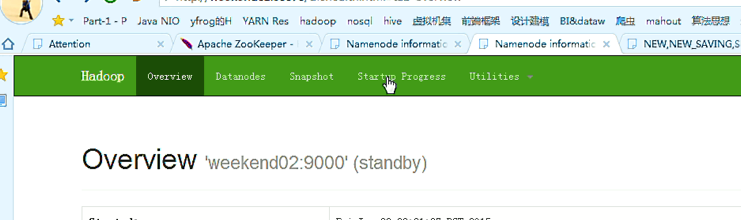
变成weekend01(standby)、weekend02(active)
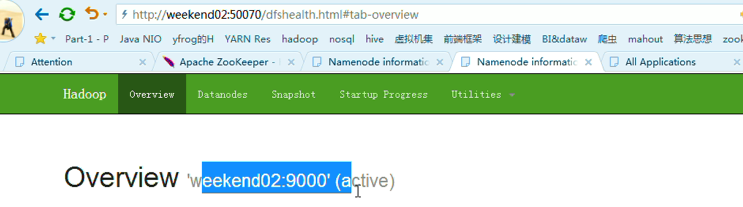
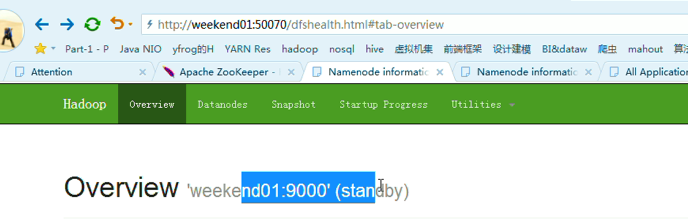

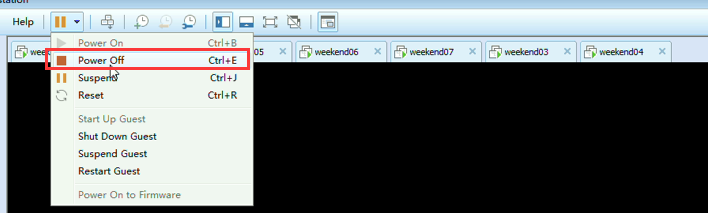
模拟weekend02断电
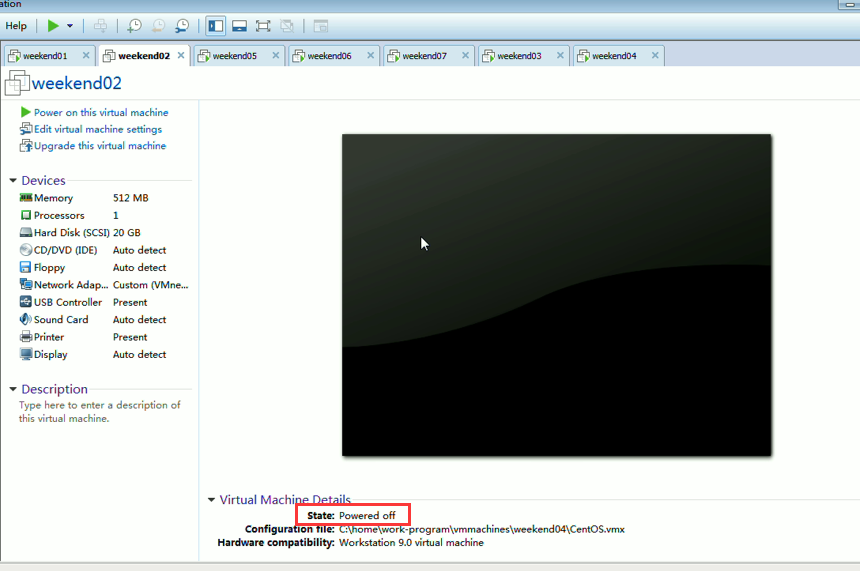


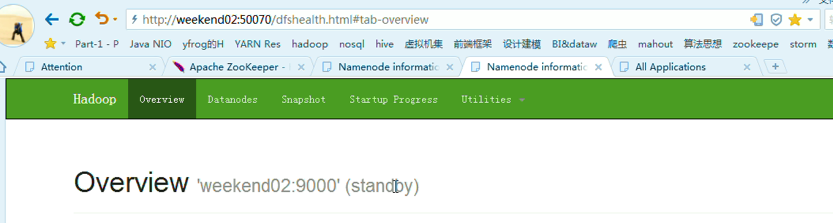
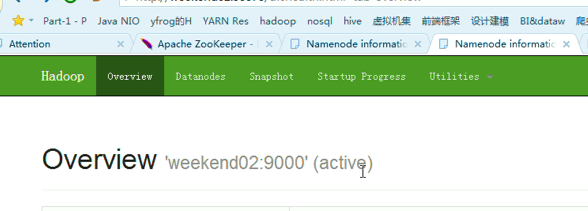
以上是weekend01(standby)、weekend02(active)
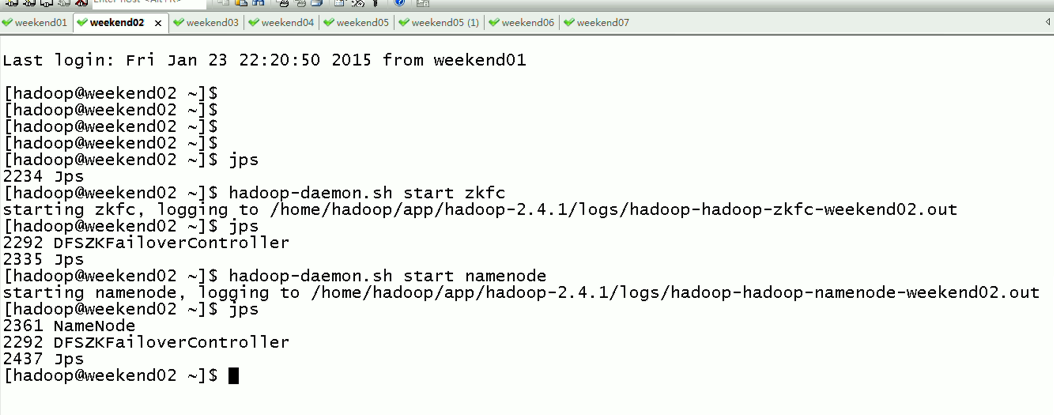
当weekend02断电后,再启动
weekend01(active)、weekend02(standby)
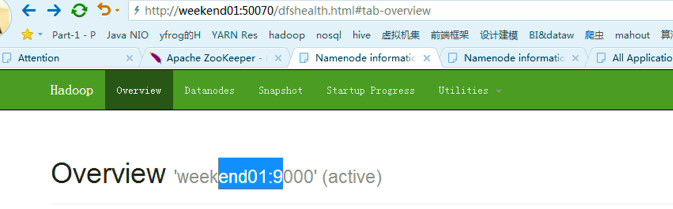


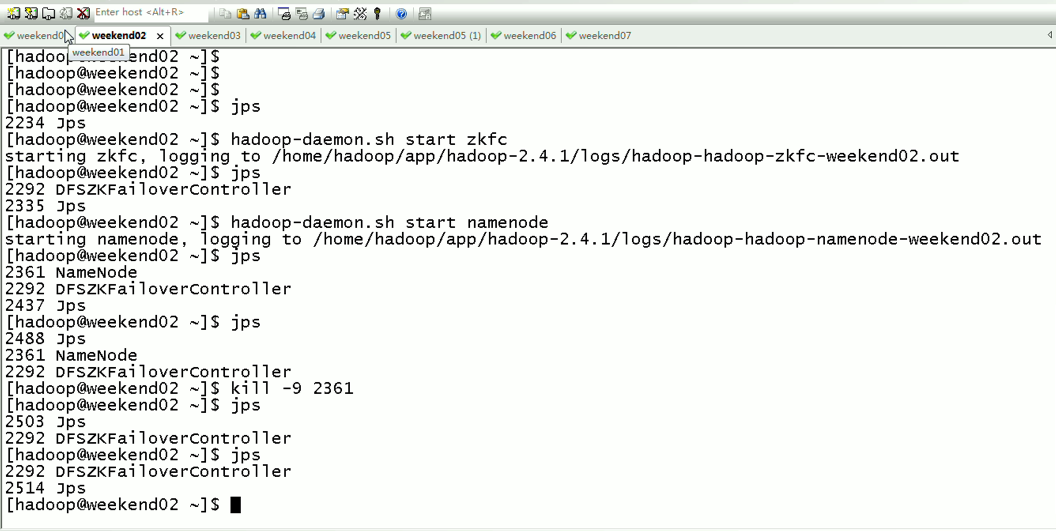
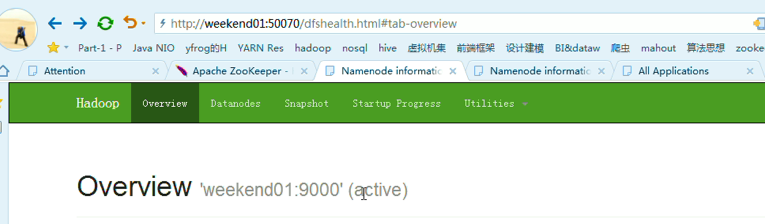
以上是weekend01(active)、weekend02(standby)
当weekend01在传文件时,weekend02杀掉namenode进程,
依然还是weekend01(active)、weekend02(standby)
以上是weekend01、02的hdfs的HA测试
下面,

现在,用指令来切换
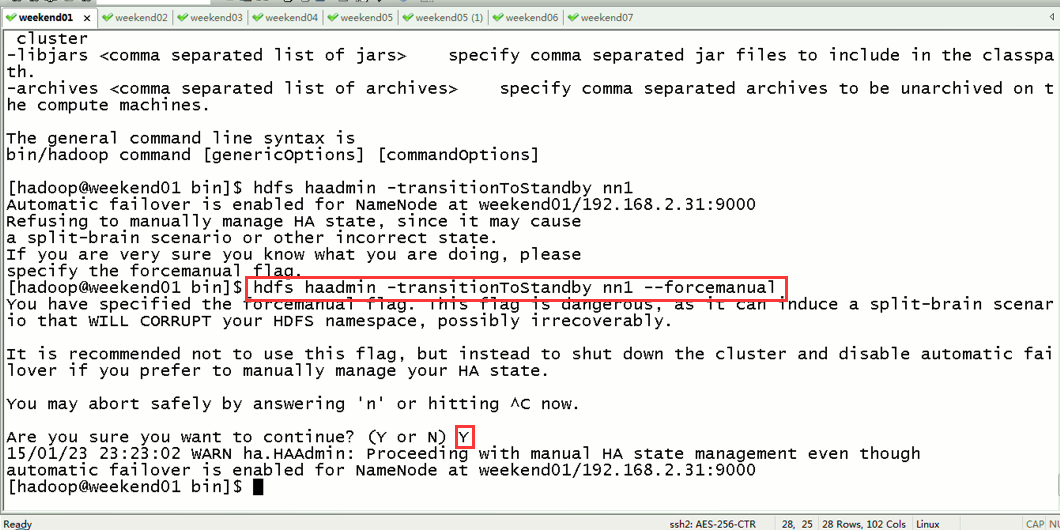
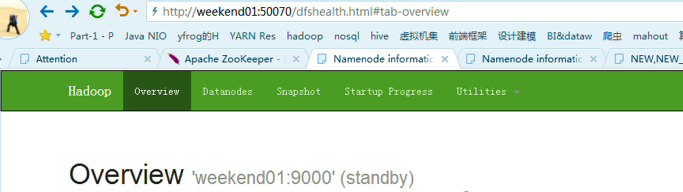
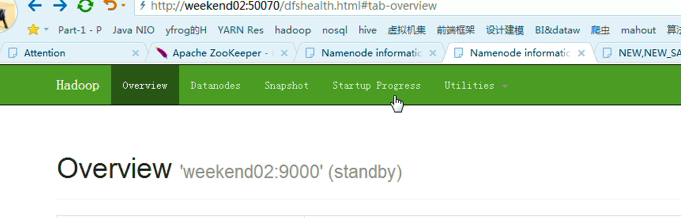
这样,是告诉我们,有时候会碰到,如weekend01、02都是standby时,来命令将其中一个切换成active
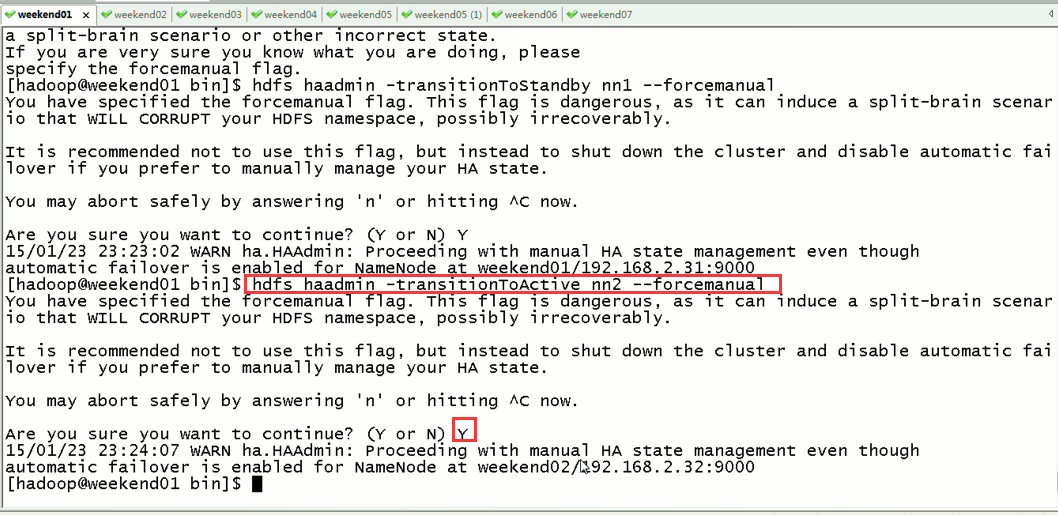

2) weekend03、04的resourcemanger的HA测试

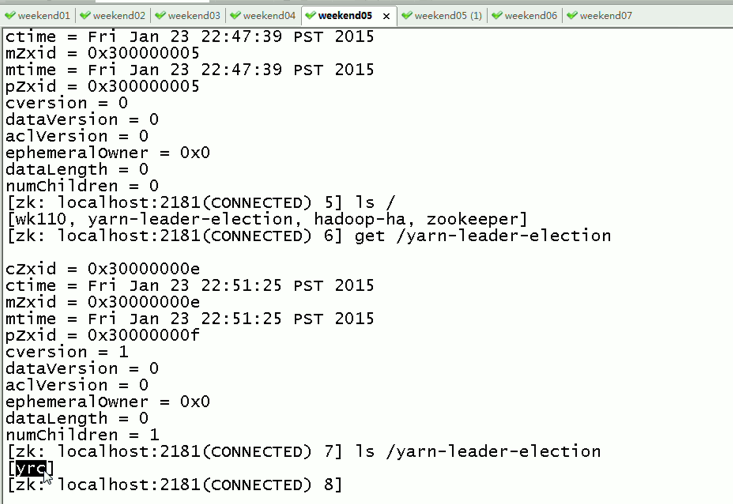
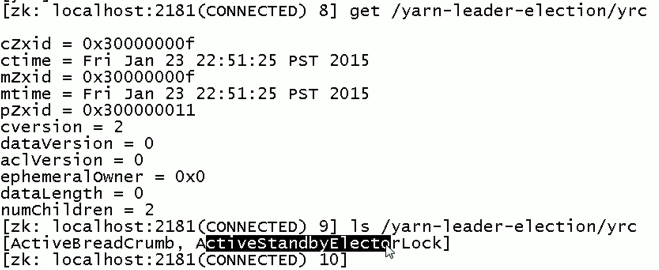
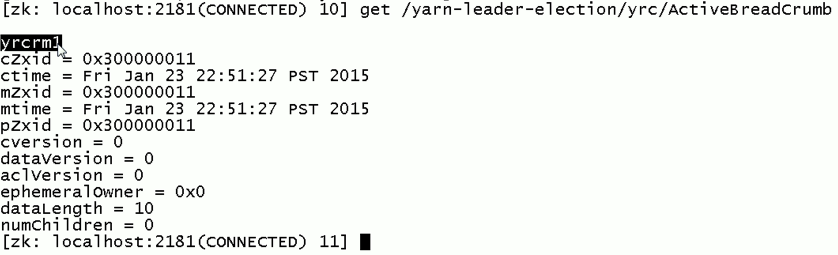
现在,来测试

会发现,yrcrm 变成 yrcrm
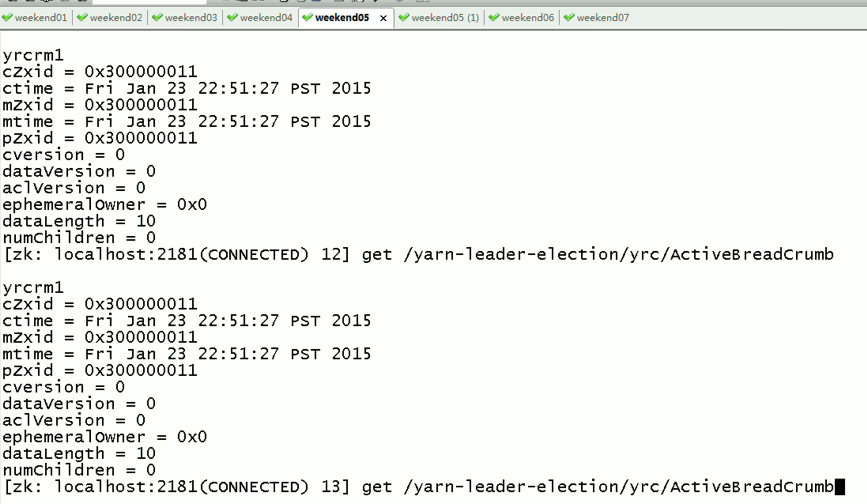
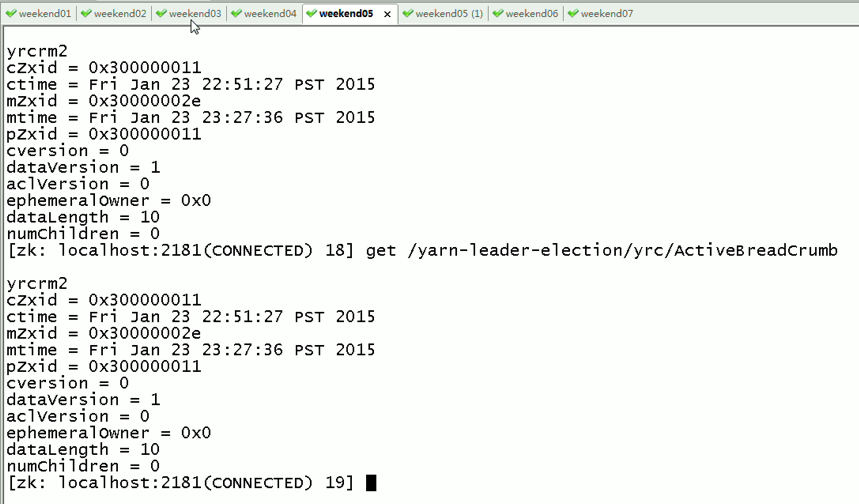
只是,resourcemanger的HA仅限于此,跟hdfs的HA不一样,
如weekend01(active)在上传文件,突然中断,weekend02(standby)
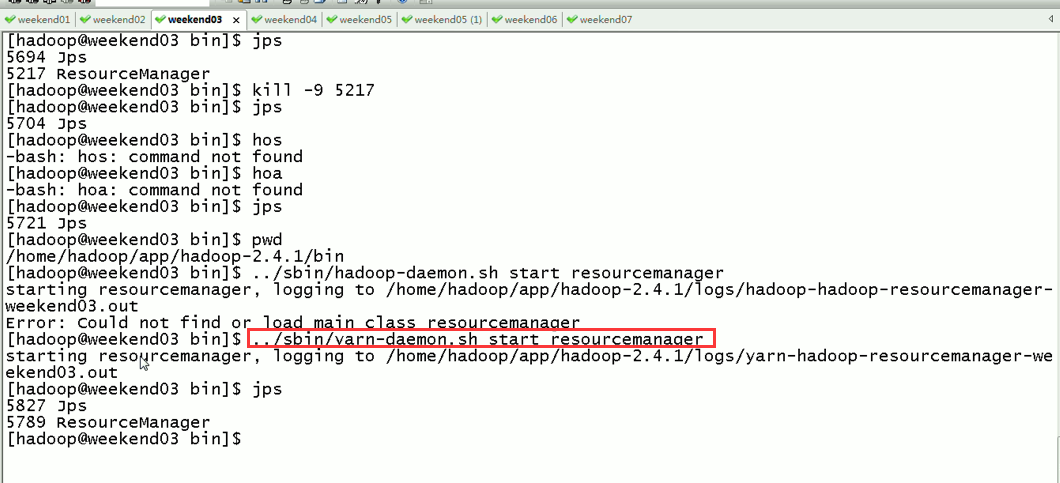

对于,weekend03、04的resourcemanager的HA,
现在是,weekend03(standby)提交作业,weekend04(active)

weekend07上,共有8个yarnchild,

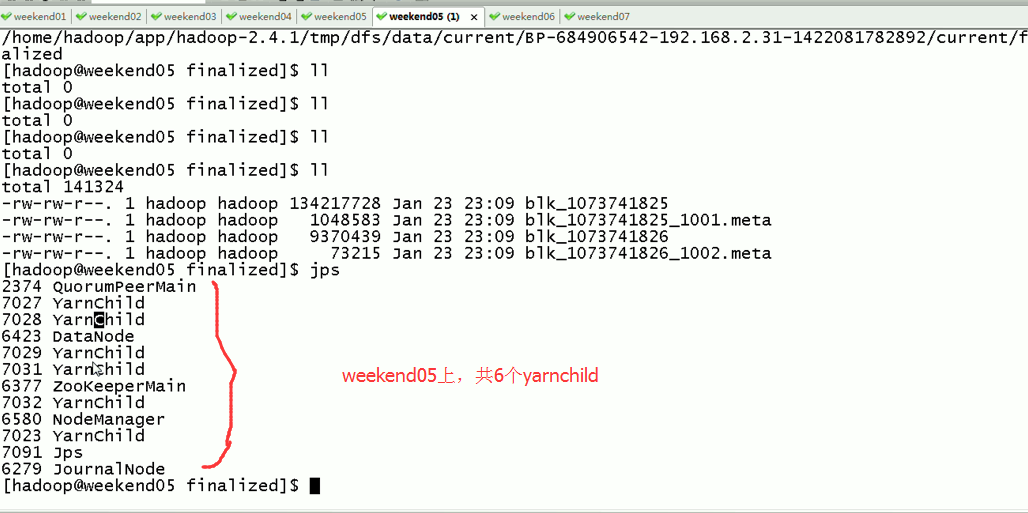
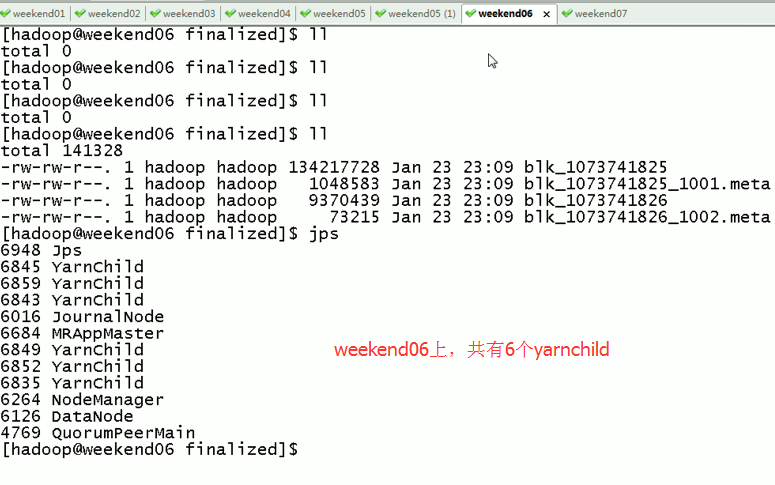
Weekend05、06、07一起,是20个yarnchild,跑作业的节点。

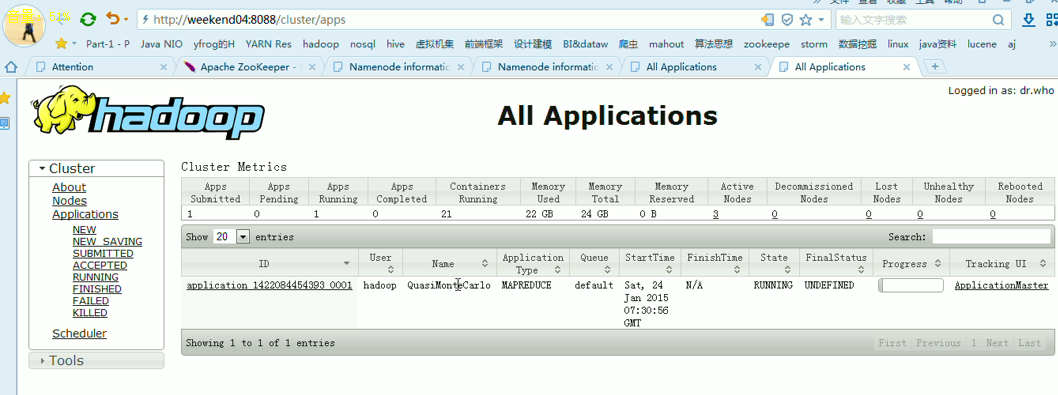
对于,weekend03、04的yarn的HA,
现在是,weekend03(standby)提交作业,weekend04(active)
现在依然还是,weekend03(standby)提交作业,weekend04(active)
以上是Weekend03、4的yarn的HA测试
总结:
以上是weekend01、02的hdfs的HA测试
Weekend03、4的yarn的HA测试
Weekend05、06、07是用来跑作业的,

关于hdfs的动态增加节点和副本数量管理,在视频里….
暂时,不赘述。
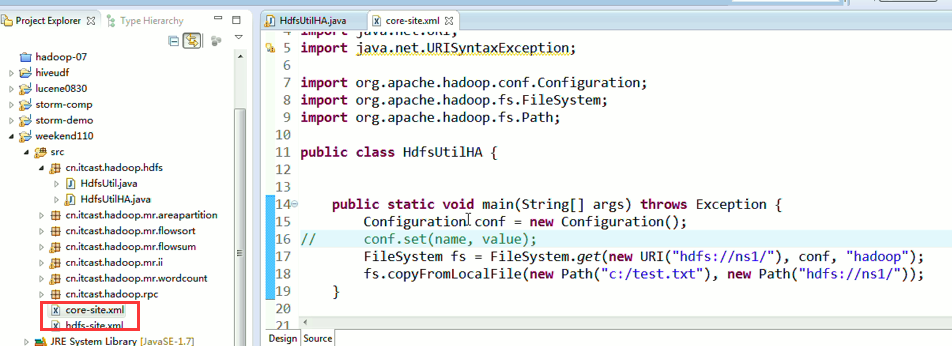
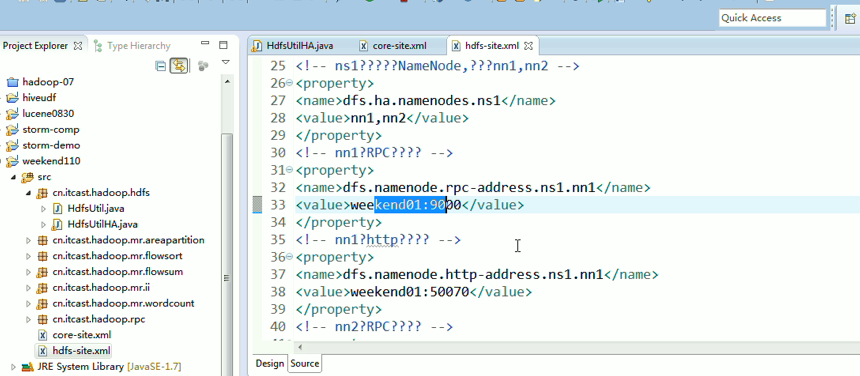
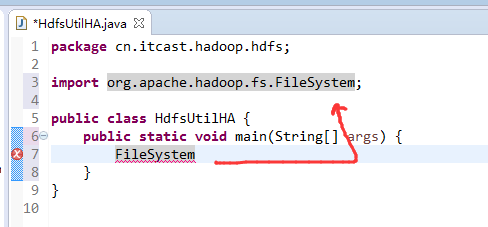
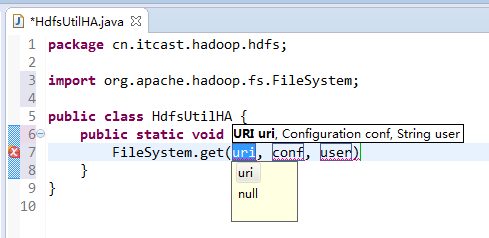
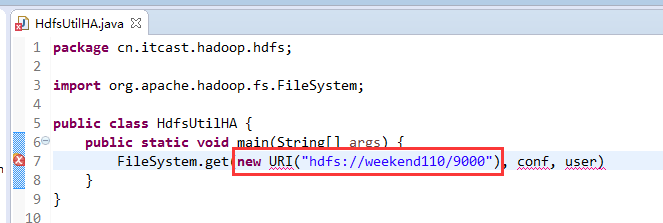
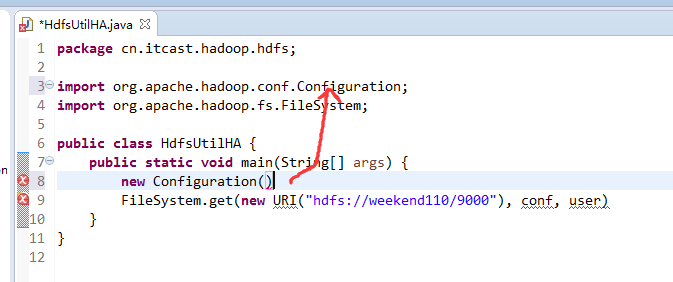
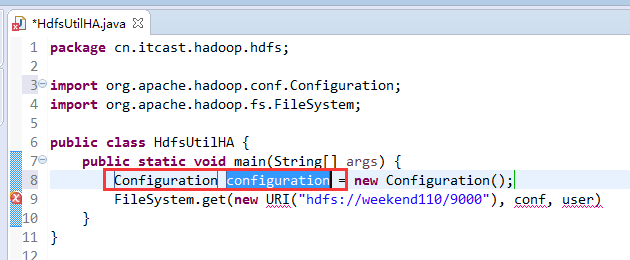
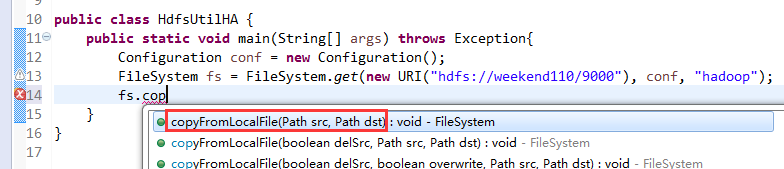
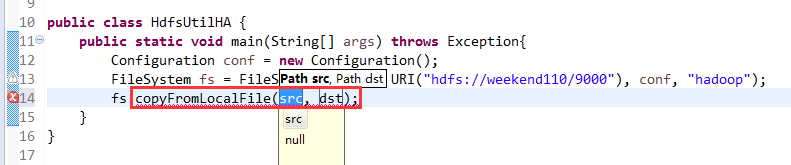
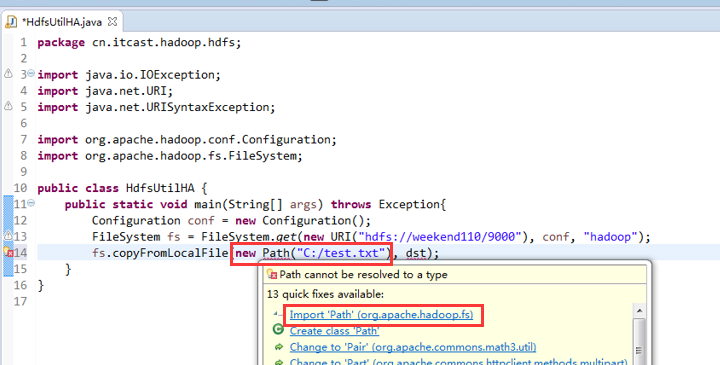
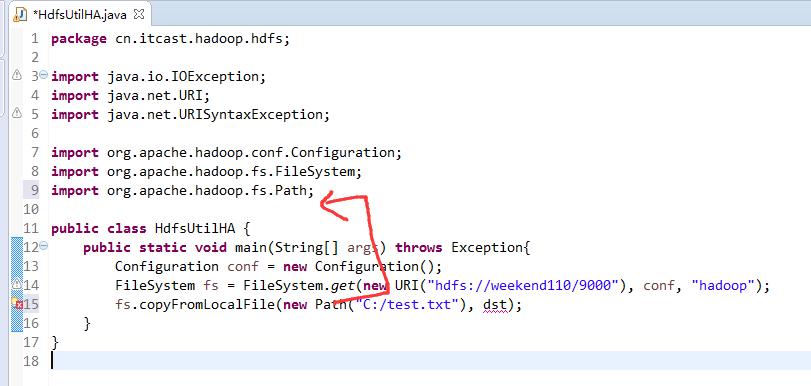
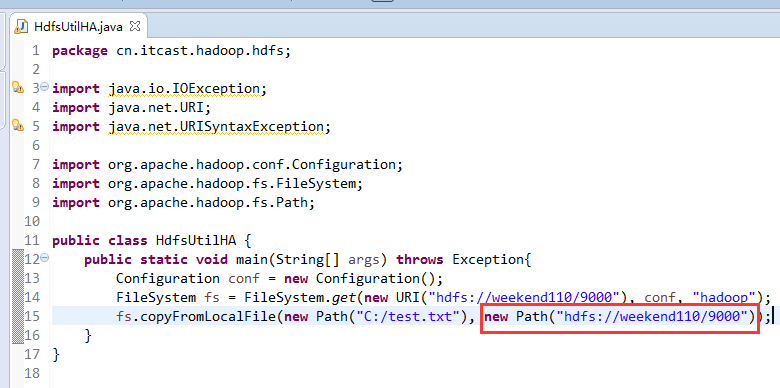
说明,下面是HA的java API访问,
所以,ns1和ns2,这里,是用ns1来访问。
而我,自己当时想在weekend110里玩玩,出现了有错误。还没解决。
当然,这知识点,是要在ns1里的。
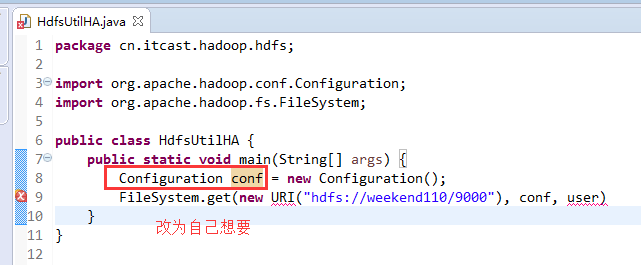
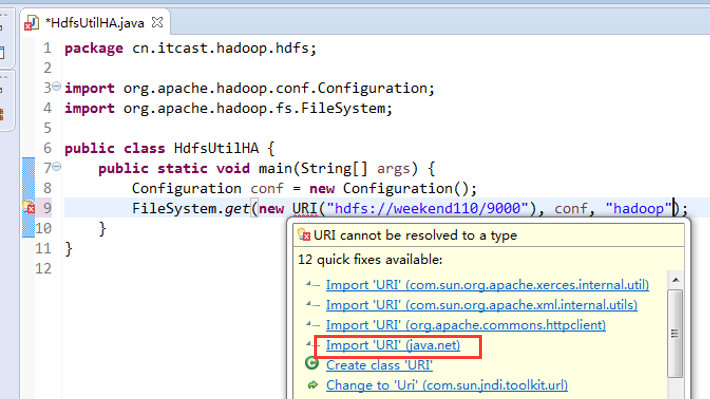
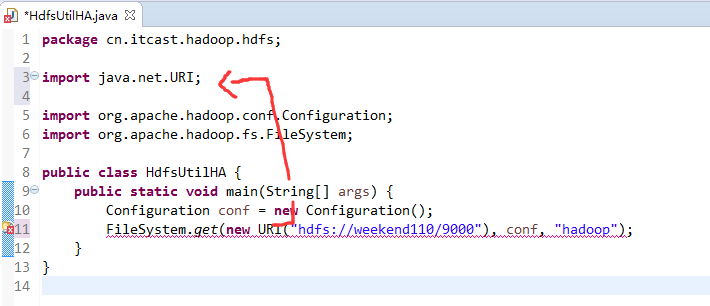
如果是视频里的话,则

如果是自己玩玩的话,则



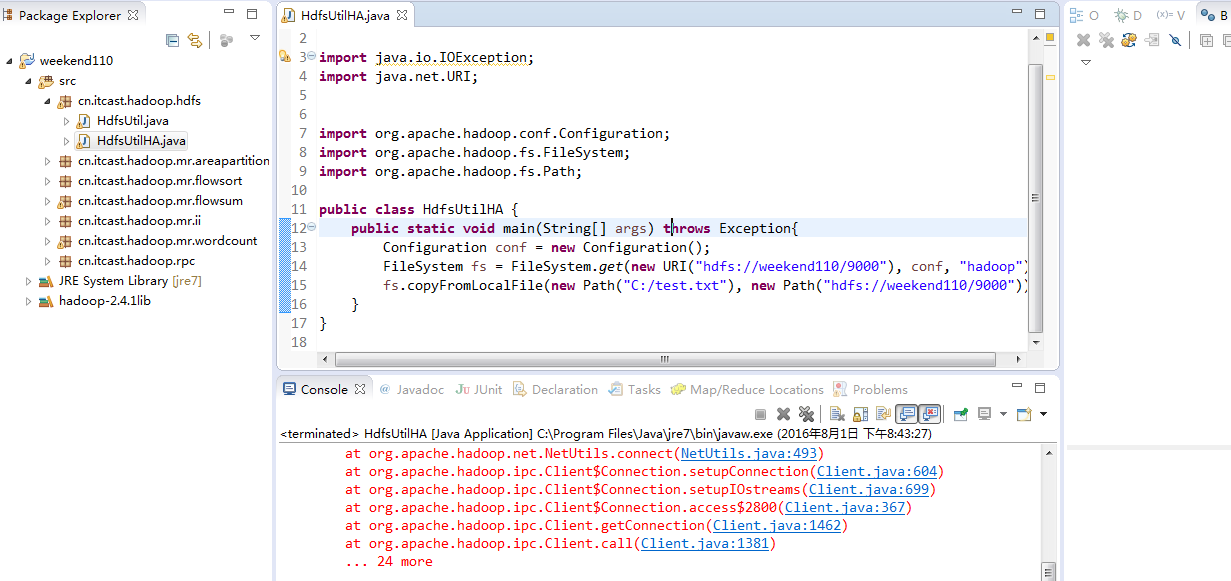
Exception in thread "main" java.net.ConnectException: Call From WIN-BQOBV63OBNM/192.168.56.1 to weekend110:8020 failed on connection exception: java.net.ConnectException: Connection refused: no further information; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(Unknown Source)
at java.lang.reflect.Constructor.newInstance(Unknown Source)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:783)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:730)
at org.apache.hadoop.ipc.Client.call(Client.java:1414)
at org.apache.hadoop.ipc.Client.call(Client.java:1363)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)
at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:190)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:103)
at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:699)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1762)
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1124)
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1120)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1120)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1398)
at org.apache.hadoop.fs.FileUtil.checkDest(FileUtil.java:496)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:348)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:338)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1903)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1871)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1836)
at cn.itcast.hadoop.hdfs.HdfsUtilHA.main(HdfsUtilHA.java:15)
Caused by: java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(Unknown Source)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:529)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:493)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:604)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:699)
at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:367)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1462)
at org.apache.hadoop.ipc.Client.call(Client.java:1381)
... 24 more
5 weekend01、02、03、04、05、06、07的分布式集群的HA测试 + hdfs--动态增加节点和副本数量管理 + HA的java api访问要点的更多相关文章
- 3 视频里weekend05、06、07的可靠性 + HA原理、分析、机制 + weekend01、02、03、04、05、06、07的分布式集群搭建
现在,我们来验证分析下,zookeeper集群的可靠性 现在有weekend05.06.07 将其一个关掉, 分析,这3个zookeeper集群里,杀死了weekend06,还存活weekend05. ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建
ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建 集群规划: hostname NameNode DataNode JournalNode Re ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- Ubuntu 12.04下Hadoop 2.2.0 集群搭建(原创)
现在大家可以跟我一起来实现Ubuntu 12.04下Hadoop 2.2.0 集群搭建,在这里我使用了两台服务器,一台作为master即namenode主机,另一台作为slave即datanode主机 ...
- 07、Spark集群的进程管理
07.Spark集群的进程管理 7.1 概述 Spark standalone集群模式涉及master和worker两个守护进程.master进程是管理节点,worker进程是工作节点.spark提供 ...
- ubuntu12.04+kafka2.9.2+zookeeper3.4.5的伪分布式集群安装和demo(java api)测试
博文作者:迦壹 博客地址:http://idoall.org/home.php?mod=space&uid=1&do=blog&id=547 转载声明:可以转载, 但必须以超链 ...
- Ubuntu 16.04上搭建CDH5.16.1集群
本文参考自:<Ubuntu16.04上搭建CDH5.14集群> 1.准备三台(CDH默认配置为三台)安装Ubuntu 16.04.4 LTS系统的服务器,假设ip地址分布为 192.168 ...
- Ubuntu16.04搭建kubernetes v1.11.2集群
1.节点介绍 master cluster-1 cluster-2 cluster-3 hostname k8s-55 k8s-5 ...
随机推荐
- shell中的双引号,单引号,反引号
在shell中引号分为三种:单引号,双引号和反引号. 单引号 ‘ 由单引号括起来的字符都作为普通字符出现.特殊字符用单引号括起来以后,也会失去原有意义,而只作为普通字符解释.单引号用于保持引号内所有字 ...
- C#实现JSON序列化与反序列化介绍
方法一:引入System.Web.Script.Serialization命名空间使用 JavaScriptSerializer类实现简单的序列化 序列化类:Personnel public clas ...
- GitHub命令精简教程
Github其实也可以作为文件分享的地方,但是免费空间只有300M,所以不能存放大文件,否则可以成为一个分享资源的下载站,而且非常方便. 常用命令: git add . //添加所有的文件到索引 ...
- jsonp跨域访问详解
jsonp是"用来跨域的" 同源策略 首先基于安全的原因,浏览器是存在同源策略这个机制的,同源策略阻止从一个源加载的文档或脚本获取或设置另一个源加载的文档的属性. 1.随便建两个网 ...
- Mysql存储过程知识,案例--mysql存储过程基本函数
Mysql存储过程知识,案例: create procedure delete_setting(in p_settingid integer) begin delete from setting wh ...
- 要将表的限制条件写到与该表同级别的where中
测试目的:将朱查询的限制条件放到子查询的where中,查看性能影响. 测试数据:create table t1 as select object_id,object_name from dba_obj ...
- c# 之 New新知
本人从事.NET工作已经一段时间,毕业之前一直想着做C++的,后来因为各种原因(跟学校导师相关),走向了.NET之路,从而时不时补一下.net的基础知识,因为自己的.NET知识还不是很扎实.近期每天早 ...
- 数据库之--- SQLite 语句
一. 基础创表操作: 1. 创建表 CREATE TABLE IF NOT EXISTS t_dog(name text, age bolb, weight real); 2. 插入记录 INSERT ...
- 配置Apache服务器 数据库mySQL
Mac 配置 apache php 详细解说 一.开启apache 并切改变引导 1.打开终端 输入:sudo apachectl start 回车,关闭终端 2.打开浏览器,地址栏输入 ...
- [原博客] POJ 1740 A New Stone Game
题目链接题意:有n堆石子,两人轮流操作,每次每个人可以从一堆中拿走若干个扔掉(必须),并且可以从中拿走一些分到别的有石子的堆里(可选),当一个人不能拿时这个人输.给定状态,问是否先手必胜. 我们参考普 ...