激活函数的比较,sigmoid,tanh,relu
1. 什么是激活函数
如下图,在神经元中,输入inputs通过加权、求和后,还被作用了一个函数。这个函数就是激活函数Activation Function
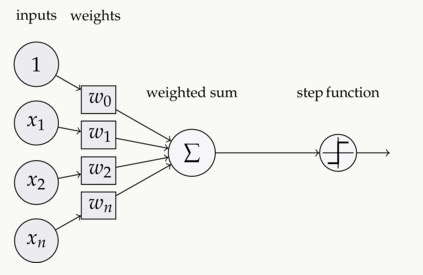
2. 为什么要用激活函数
如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网路有多少层,输出都是输入的线性组合。与没有隐藏层效果相当,这种情况就是最原始的感知机了。
使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
3. 都有什么激活函数
(1)sigmoid函数
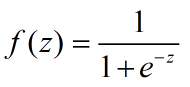

导数:
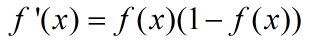
等式的证明也很简单。sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1)
sigmoid缺点:
- 激活函数计算量大,反向传播求误差梯度使,求导涉及除法
- 反向传播使,很容易就会出现梯度消失的情况,从而无法完成生成网络的训练
- sigmoid两端饱和且容易kill掉梯度
- 收敛缓慢
为何出现梯度消失:
sigmoid原函数及导数图如下图所示:
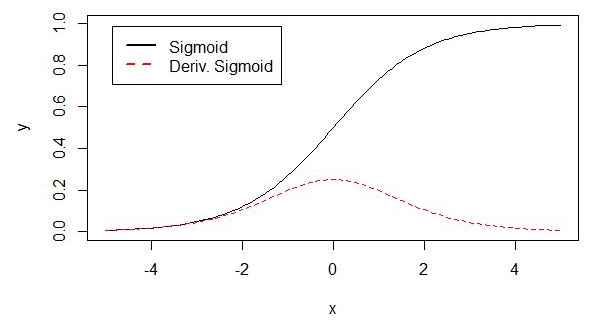
由图可知,导数从0开始很快又趋近于0,易造成"梯度消失"现象
(2)tanh函数(双曲正切)
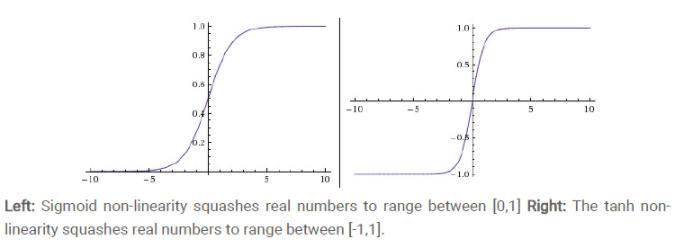
取值范围[-1,1]。0均值,实际应用中tanh比sigmoid要好
(3)ReLU
公式:
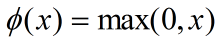
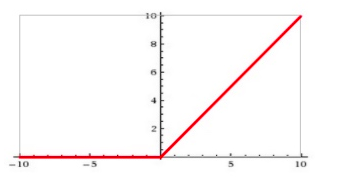
输入信号 < 0时,输出都是0;输入 > 0时,输出等于输入
1. ReLU更容易优化,因为其分段线性性质,导致其前传、后传、求导都是分段线性的。而传统的sigmoid函数,由于两端饱和,在传播过程中容易丢失信息
2. ReLU会使一部分神经元输出为0,造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合。
3. 当然现在也有一些对ReLU的改进,比如lrelu、prelu,在不同的数据集上会有一些训练速度上或者准确率上的改进。
4. 现在主流的做法,是在relu之后,加上一层batch normalization,尽可能保证每一层网络的输入具有相同的分布。
ReLU的缺点:
训练的时候很"脆弱",很容易"die"
例如:一个非常大的梯度流过一个ReLU神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了,那么这个神经元就永远都会是0.
(4)softmax函数
Softmax-用于多分类神经网络输出
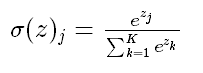
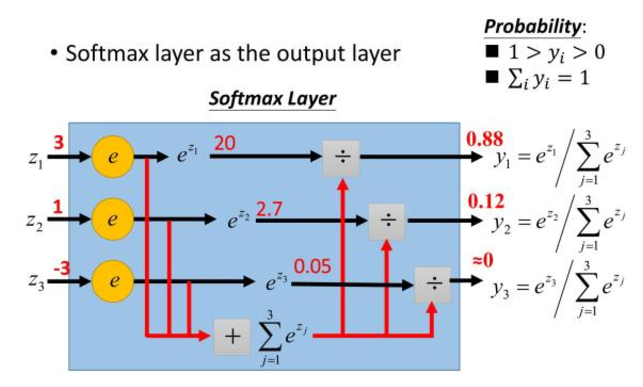
上图所示,如果某个 zj 大过其他 z,那这个映射的分量就逼近于1,其他逼近于0,主要应用于多分类
为什么要取指数?
1. 模拟 max 的行为,让大的更大
2. 需要一个可导函数
激活函数的比较,sigmoid,tanh,relu的更多相关文章
- 深度学习原理与框架-神经网络架构 1.神经网络构架 2.激活函数(sigmoid和relu) 3.图片预处理(减去均值和除标准差) 4.dropout(防止过拟合操作)
神经网络构架:主要时表示神经网络的组成,即中间隐藏层的结构 对图片进行说明:我们可以看出图中的层数分布: input layer表示输入层,维度(N_num, input_dim) N_num表示输 ...
- 人工智能-深度学习(3)TensorFlow 实战一:手写图片识别
http://gitbook.cn/gitchat/column/59f7e38160c9361563ebea95/topic/59f7e86d60c9361563ebeee5 wiki.jikexu ...
- 激活函数:Sigmod&tanh&Softplus&Relu详解
什么是激活函数? 激活函数(Activation functions)对于人工神经网络模型去学习.理解非常复杂和非线性的函数来说具有十分重要的作用. 它们将非线性特性引入到我们的网络中.其主要目的是将 ...
- 激活函数,Batch Normalization和Dropout
神经网络中还有一些激活函数,池化函数,正则化和归一化函数等.需要详细看看,啃一啃吧.. 1. 激活函数 1.1 激活函数作用 在生物的神经传导中,神经元接受多个神经的输入电位,当电位超过一定值时,该神 ...
- Pytorch1.0深度学习:损失函数、优化器、常见激活函数、批归一化详解
不用相当的独立功夫,不论在哪个严重的问题上都不能找出真理:谁怕用功夫,谁就无法找到真理. —— 列宁 本文主要介绍损失函数.优化器.反向传播.链式求导法则.激活函数.批归一化. 1 经典损失函数 1. ...
- Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- Andrew Ng机器学习课程笔记--week5(上)
Neural Networks: Learning 内容较多,故分成上下两篇文章. 一.内容概要 Cost Function and Backpropagation Cost Function Bac ...
- 转 Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
- TensorFlow(2)Softmax Regression
Softmax Regression Chapter Basics generate random Tensors Three usual activation function in Neural ...
- Layers Of Caffe
本文试图描述构建一个网络结构的layers,可以用prototxt脚本直接写,也可以用python接口实现. 最简单的神经网络包含但不限于以下四部分: 数据层(Data): Data.ImageDat ...
随机推荐
- Linux系统安全学习笔记(1)-- 文件系统类型
今天看了一个关于Linux系统安全的视频教程,这个教程有很多的知识点,我会分几篇博文将我的笔记分享出来. 首先是关于Linux文件系统类型的一些知识,Linux有四种常见的文件系统类型(网上大多数是3 ...
- [sklearn] 实现随即梯度下降(SGD)&分类器评价参数查看
直接贴代码吧: 1 # -*- coding:UTF-8 -*- 2 from sklearn import datasets 3 from sklearn.cross_validation impo ...
- Cola Cloud 基于 Spring Boot, Spring Cloud 构建微服务架构企业级开发平台
Cola Cloud 基于 Spring Boot, Spring Cloud 构建微服务架构企业级开发平台: https://gitee.com/leecho/cola-cloud
- 设计模式C++学习笔记之一(Strategy策略模式)
无意中,从网上下到一本电子书<24种设计模式介绍与6大设计原则>,很好奇这里有24种设计模式,印象中GOF写的<设计模式>(Design Patterns),好像只有23种吧. ...
- genPanel.py
#!/usr/bin/python # -*- coding: UTF-8 -*- import os import sys import re import shutil import glob ' ...
- Centos6.8下卸载软件(以Mysql为例)
1 删除Mysql yum remove mysql mysql-server mysql-libs mysql-server; find / -name mysql 将找到的相关东西delete掉 ...
- 【转】Java并发编程:阻塞队列
在前面几篇文章中,我们讨论了同步容器(Hashtable.Vector),也讨论了并发容器(ConcurrentHashMap.CopyOnWriteArrayList),这些工具都为我们编写多线程程 ...
- sugarCRM文档翻译1
2018-3-9 14:42:14 星期五 本文分两部分: 第一部分是从index.php入口开始的代码执行的部分流程 第二部分是对官方文档的翻译 第一部分: 流程: 入口文件: index.php ...
- [MySQL]join的细节
left join,左表返回所有记录,右表只返回跟左表有关联的记录,当右表有N条记录跟左表的某一条记录A关联,那么查询结果会出现N条A记录(相应关联右表的N条记录) right join,右表返回所有 ...
- elasticsearch索引自动清理
一 es 基本操作 查看所有的索引文件: curl -XGET http://localhost:9200/_cat/indices?v GET /_cat/indices?v DELETE /fi ...