Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的。从bottom得到一个blob数据输入,运算后,从top输入一个blob数据。在运算过程中,没有改变数据的大小,即输入和输出的数据大小是相等的。
输入:n*c*h*w
输出:n*c*h*w
常用的激活函数有sigmoid, tanh,relu等,下面分别介绍。
1、Sigmoid
对每个输入数据,利用sigmoid函数执行操作。这种层设置比较简单,没有额外的参数。
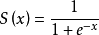
层类型:Sigmoid
示例:
layer {
name: "encode1neuron"
bottom: "encode1"
top: "encode1neuron"
type: "Sigmoid"
}
2、ReLU / Rectified-Linear and Leaky-ReLU
ReLU是目前使用最多的激活函数,主要因为其收敛更快,并且能保持同样效果。
标准的ReLU函数为max(x, 0),当x>0时,输出x; 当x<=0时,输出0
f(x)=max(x,0)
层类型:ReLU
可选参数:
negative_slope:默认为0. 对标准的ReLU函数进行变化,如果设置了这个值,那么数据为负数时,就不再设置为0,而是用原始数据乘以negative_slope
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
RELU层支持in-place计算,这意味着bottom的输出和输入相同以避免内存的消耗。
3、TanH / Hyperbolic Tangent
利用双曲正切函数对数据进行变换。
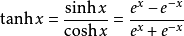
层类型:TanH
layer {
name: "layer"
bottom: "in"
top: "out"
type: "TanH"
}
4、Absolute Value
求每个输入数据的绝对值。
f(x)=Abs(x)
层类型:AbsVal
layer {
name: "layer"
bottom: "in"
top: "out"
type: "AbsVal"
}
5、Power
对每个输入数据进行幂运算
f(x)= (shift + scale * x) ^ power
层类型:Power
可选参数:
power: 默认为1
scale: 默认为1
shift: 默认为0
layer {
name: "layer"
bottom: "in"
top: "out"
type: "Power"
power_param {
power: 2
scale: 1
shift: 0
}
}
6、BNLL
binomial normal log likelihood的简称
f(x)=log(1 + exp(x))
层类型:BNLL
layer {
name: "layer"
bottom: "in"
top: "out"
type: “BNLL”
}
Caffe学习系列(4):激活层(Activiation Layers)及参数的更多相关文章
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
- Caffe学习系列(21):caffe图形化操作工具digits的安装与运行
经过前面一系列的学习,我们基本上学会了如何在linux下运行caffe程序,也学会了如何用python接口进行数据及参数的可视化. 如果还没有学会的,请自行细细阅读: caffe学习系列:http:/ ...
随机推荐
- iOS开发Facebook POP动效库使用教程
如果说Origami这款动效原型工具是Facebook Paper的幕后功臣,那么POP便是Origami的地基.感谢Facebook开源了POP动效库,让人人都能制作出华丽的动效.我们只需5步,便能 ...
- DP大作战——多重背包
题目描述 在之前的上机中,零崎已经出过了01背包和完全背包,也介绍了使用-1初始化容量限定背包必须装满这种小技巧,接下来的背包问题相对有些难度,可以说是01背包和完全背包的进阶问题. 多重背包:物品可 ...
- n&(n-1) n&(-n)
n&(n-1) n&(-n) n&(n-1)作用:将n的二进制表示中的最低位为1的改为0,先看一个简单的例子:n = 10100(二进制),则(n-1) = 10011 = ...
- C#输入输出重定向
当 Process 将文本写入其标准流中时,通常将在控制台上显示该文本.通过重定向 StandardOutput 流,可以操作或取消进程的输出.例如,可以筛选文本.用不同方式将其格式化,也可以将输出同 ...
- uname
uname uname用于打印操作系统和硬件架构相关的信息,对于可能在多个系统或架构上运行的Shell脚本程序很有用, 缺省选项相当于 -s 或--system $uname [-amnrsvpio] ...
- java 使用POI批量导入excel数据
一.定义 Apache POI是Apache软件基金会的开放源码函式库,POI提供API给Java程序对Microsoft Office格式档案读和写的功能. 二.所需jar包: 三.简单的一个读取e ...
- centos 下使用locate命令
首先安装mlocate yum -y install mlocate 更新数据库:updatedb 查找:locate nginx
- XNote Ver:0.79
隐藏主窗后,双击小图标显示主窗. 支持拖拉网页文字到小图标上,直接在当前项目上创建下级资料项目. 项目分类限50个汉字.
- spark加载hadoop本地库的时候出现不能加载的情况要怎么解决呢?
hadoop shell运行的时候不会报这个错误,因为我已经重新在64位机上编译了源文件,并把so文件复制到hadoop的native目录下,而且环境变量也设置正确了,所以hadoop本身没有问题. ...
- 自定义input[type="file"]的样式
input[type="file"]的样式在各个浏览器中的表现不尽相同: 1. chrome: 2. firefox: 3. opera: 4. ie: 5. edge: 另外,当 ...