Spark大数据平台安装教程
一.Spark介绍
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
二.安装Spark
环境:Docker(17.04.0-ce)、镜像Ubuntu(16.04.3)、JDK(1.8.0_144)、Hadoop(3.1.1)、Spark(2.3.2)
1.安装Hadoop
参考:Hadoop伪分布式模式安装
2.解压Spark
bigdata@lab-bd:~$ tar -xf spark-2.3.-bin-without-hadoop.tgz
3.重名名conf/spark-env.sh.template为spark-env.sh
bigdata@lab-bd:~$ mv spark-2.3.-bin-without-hadoop/conf/spark-env.sh.template spark-2.3.-bin-without-hadoop/conf/spark-env.sh
4.编辑conf/spark-env.sh文件,增加如下变量
export JAVA_HOME=/home/hadoop/jdk1..0_144
export SPARK_DIST_CLASSPATH=$(/home/hadoop/hadoop-3.1./bin/hadoop classpath)
export HADOOP_CONF_DIR=/home/hadoop/hadoop-3.1./etc/hadoop
export PYSPARK_PYTHON=/usr/bin/python3.
三.运行Spark
1.启动Hdfs服务
bigdata@lab-bd:~$ hadoop-3.1./sbin/start-dfs.sh
2.启动Yarn服务
bigdata@lab-bd:~$ hadoop-3.1./sbin/start-yarn.sh
3.交互模式运行pyspark
bigdata@lab-bd:~$ spark-2.3.-bin-without-hadoop/bin/pyspark --master yarn --deploy-mode client 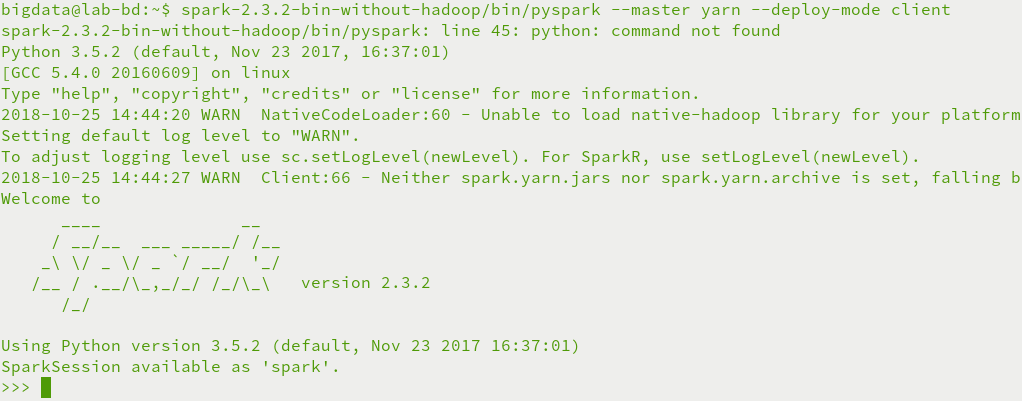
4.提交模式运行spark-submit
bigdata@lab-bd:~$ spark-2.3.-bin-without-hadoop/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client \
> spark-2.3.-bin-without-hadoop/examples/jars/spark-examples_2.-2.3..jar
5.浏览器访问http://10.0.0.3:8088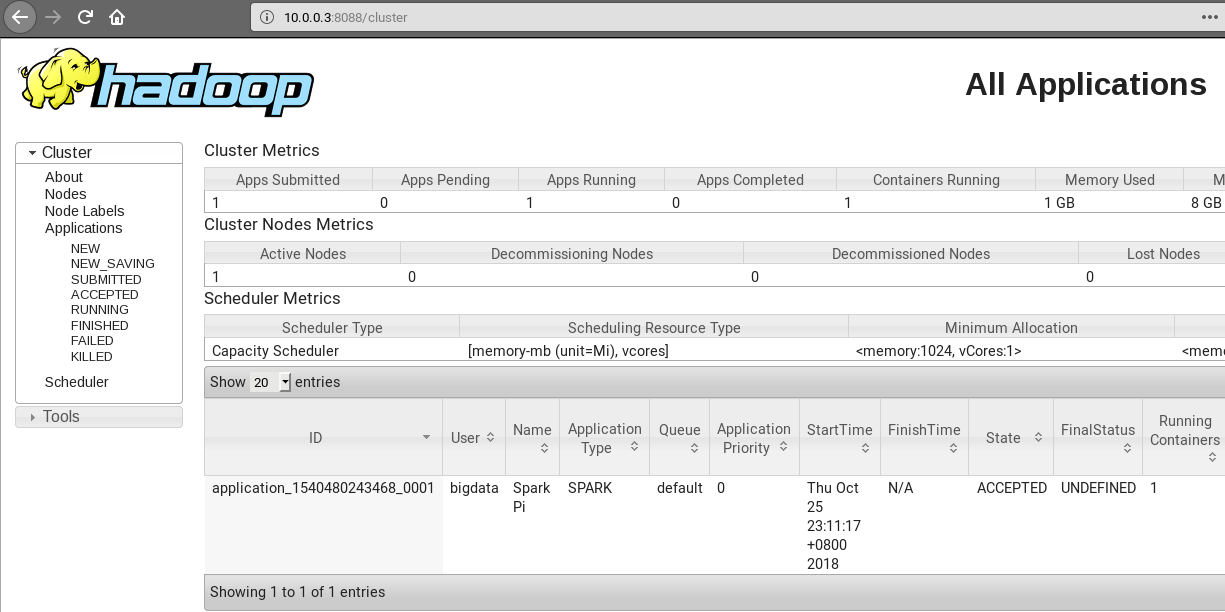
四.启动异常
1.Caused by: java.lang.ClassNotFoundException: org.slf4j.Logger异常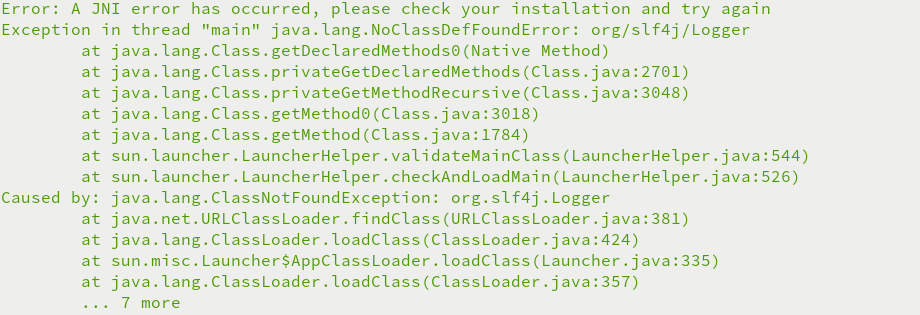
Hadoop和Spark独立安装,Spakr运行需要Hadoop,无SPARK_DIST_CLASSPATH变量,无法关联hadoop
编辑conf/spark-env.sh文件,配置SPARK_DIST_CLASSPATH变量
export SPARK_DIST_CLASSPATH=$(/home/bigdata/hadoop-3.1./bin/hadoop classpath)
2.Exception in thread "main" java.lang.Exception: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment异常
Hadoop和Spark独立安装,Spakr运行需要Hadoop,无HADOOP_CONF_DIR变量,无法关联YARN
编辑conf/spark-env.sh文件,配置HADOOP_CONF_DIR变量
export HADOOP_CONF_DIR=/home/bigdata/hadoop-3.1./etc/hadoop
3.org.apache.spark.rpc.RpcEnvStoppedException: RpcEnv already stopped异常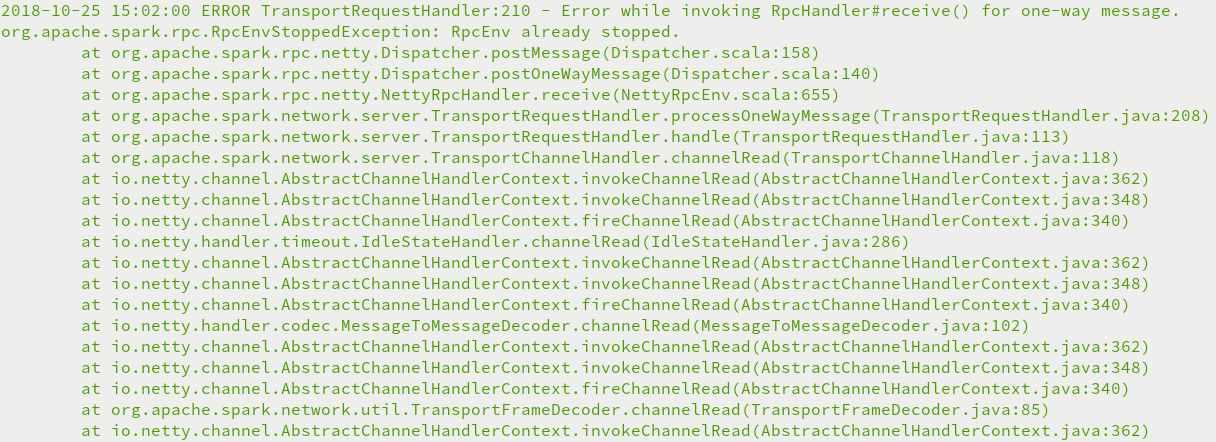
物理内存或者虚拟内存分配不够,Yarn直接杀死进程,需要禁止内存检查
编辑Hadoop中的etc/hadoop/yarn-site.xml文件,添加如下配置
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4.env: 'python': No such file or directory错误
pyspark需要使用python,未配置PYSPARK_PYTHON变量
export PYSPARK_PYTHON=/usr/bin/python3.
Spark大数据平台安装教程的更多相关文章
- 【福利】送Spark大数据平台视频学习资料
没有套路真的是送!! 大家都知道,大数据行业spark很重要,那话我就不多说了,贴心的大叔给你找了份spark的资料. 多啰嗦两句,一个好的程序猿的基本素养是学习能力和自驱力.视频给了你们,能不能 ...
- 最新版大数据平台安装部署指南,HDP-2.6.5.0,ambari-2.6.2.0
一.服务器环境配置 1 系统要求 名称 地址 操作系统 root密码 Master1 10.1.0.30 Centos 7.7 Root@bidsum1 Master2 10.1.0.105 Cent ...
- GreenPlum 大数据平台--安装
1. 环境准备 01, 安装包准备: Greenplum : >>>>链接地址 Pgadmin客户端 : >>>链接地址 greenplum-cc-web ...
- Spark 大数据平台 Introduction part 2 coding
Basic Functions sc.parallelize(List(1,2,3,4,5,6)).map(_ * 2).filter(_ > 5).collect() *** res: Arr ...
- Spark 大数据平台
Apache Spark is an open source cluster computing system that aims to make data analytics fast - both ...
- 大数据平台R语言web UI应用架构 设计与开发
1. 系统拓扑图 在日常业务分析中,R是非常常用的分析工具,而当数据量较大时,用R语言需要需用更多的时间来完成训练模型,spark作为大规模数据处理框架,采用内存计算,可以短时间内完成大量的数据的处理 ...
- HDP 企业级大数据平台
一 前言 阅读本文前需要掌握的知识: Linux基本原理和命令 Hadoop生态系统(包括HDFS,Spark的原理和安装命令) 由于Hadoop生态系统组件众多,导致大数据平台多节点的部署,监控极其 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- Spark大型项目实战:电商用户行为分析大数据平台
本项目主要讲解了一套应用于互联网电商企业中,使用Java.Spark等技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.页面跳转行为.购物行为.广告点击行为等)进行复杂的分析.用统计分 ...
随机推荐
- 向Spring容器中注册组件的方法汇总小结
1.通过xml定义 <bean class=""> <property name="" value=""></ ...
- Python3 系列之 面向对象篇
面向对象的三大特性:继承.封装和多态 Python 做到胶水语言,当然也支持面向对象的编程模式. 封装 class UserInfo(object): lv = 5 def __init__(self ...
- angular ng-repeat 动态获取的dom片段 显示
.filter('to_trusted', ['$sce',function ($sce) { return function (text) { return $sce.trustAsHtml(tex ...
- CSS之IE浏览器的hasLayout,IE低版本的bug根源
什么是hasLayout? hasLayout是IE特有的一个属性.很多的ie下的css bug都与其息息相关.在ie中,一个元素要么自己对自身的内容进行计算大小和组织,要么依赖于父元素来计算尺寸和组 ...
- 小tips:JS语法之标签(label)
JavaScript语言允许,语句的前面有标签(label),相当于定位符,用于跳转到程序的任意位置,标签的格式如下. label: statement 标签可以是任意的标识符,但是不能是保留字,语句 ...
- js匹配字符串
lastIndexOf() 方法可返回一个指定的字符串值最后出现的位置,在一个字符串中的指定位置从后向前搜索 var str = 'Hello World' str.lastIndexOf('Hell ...
- java调用matlab
object result[]; result = pClass1.job_3in1(2, c, ws2, 1275, a, 0); string adg[]; adg = result[1].toS ...
- html之head标签
本文内容: head标签 介绍 常用子标签 meta title link style script 首发时间:2018-02-12 修改: 2018-04-24:修改了标题名称,重新排版了内容,使得 ...
- python与html5 websocket开发聊天对话窗
1.下载必须的包 https://github.com/Pithikos/python-websocket-server,解压缩并把文件夹名‘python-websocket-server-maste ...
- 用好lua+unity,让性能飞起来——关于《Unity项目常见Lua解决方案性能比较》的一些补充
<Unity项目常见Lua解决方案性能比较>,这篇文章对比了现在主流几个lua+unity的方案 http://blog.uwa4d.com/archives/lua_perf.html ...