Kafka概述及安装部署
一、Kafka概述
1.Kafka是一个分布式流媒体平台,它有三个关键功能:
(1)发布和订阅记录流,类似于消息队列或企业消息传递系统;
(2)以容错的持久方式存储记录流;
(3)记录发送时处理流。
2.Kafka通常应用的两大类应用
(1)构建在系统或应用程序之间的可靠获取数据的实时流数据管道;
(2)构建转换或响应数据流的实施流应用程序。
3.Kafka中的角色
发送消息:Producer
接收消息:Consumer
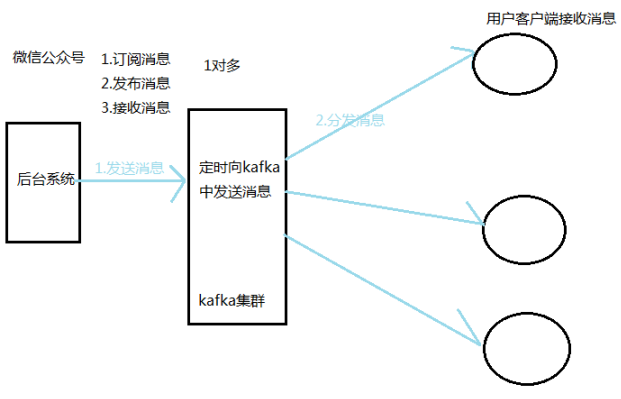
后台系统向kafka集群发送消息,然后kafka集群向用户分发消息
4.为什么要用消息队列
(1)解耦:可以自由处理和设置接收及发送端的配置,
是一个接口的约束,可以避免出现一些问题
(2)拓展性:可以增加处理过程
(3)灵活:面对访问量增长到峰值时,不会因为超负荷请求而完全瘫痪
(4)可恢复:一部分组件失效了,不会影响整个系统,并可以恢复
(5)缓存:控制数据量经过系统的速度
(6)顺序保证:保证消息数据按照有序处理
(7)异步通信:
提供了异步处理的机制,允许用户把消息当到队列中但不立即处理
5.Kafka架构设计
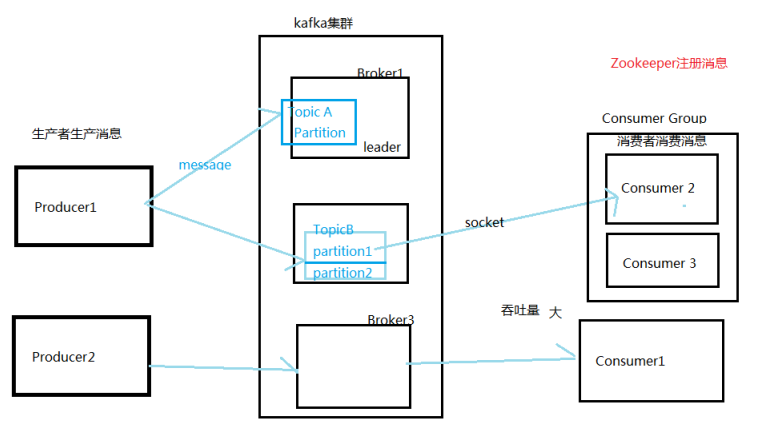
kafka依赖于zookeeper,用zk保存元数据信息(保存kafka集群节点状态信息和消费者当前消费信息)。所以要先搭建zookeeper集群,在搭建kafka集群。
在kafka中,用来处理和存储生产者生成的消息的是broker,broker将生产者生成的消息以topic分类到不同分区partition,然后根据消费者订阅的主题对消费者发送消息。
二、Kafka的安装部署
1.在下载安装包,本人使用的是2.11-2.0.0,上次到linux,解压
2.在kafka路径下创建其日志文件夹
mkdir logs
3.进入config目录,进入server.properties文件修改配置信息
broker.id=0
delete.topic.enable=true
log.dirs=/root/hd/kafka/logs
zokeeper.connect=hd1-1:2181,hd1-2:2181,hd1-3:2181
保存并退出;
4.将修改好的kafka文件夹发送到其他集群机器,并修改server.properties中的broker.id为1,2,3...
scp -r /root/hd/kafka hd09-01:/root/hd/
5.启动zookeeper集群,再启动kafka集群
进入kafka目录下输入命令:
bin/kafka-server-start.sh config/server/properties
启动完成!!
Kafka概述及安装部署的更多相关文章
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- HBase的概述和安装部署
一.HBase概述 1.HBase是Hadoop数据库,是一个分布式.可扩展的大数据存储. HBase是用于对大数据进行随机.实时读写访问的非关系型数据库,它的目标托管非常大的表——数十亿行N百万列. ...
- Zookeeper的概述、安装部署及选举机制
一.Zookeeper概述 1.Zookeeper是Hadoop生态的管理者,它致力于开发和维护开源服务器,实现高度可靠的分布式协调. 2.Zookeeper的两大功能: (1)存储数据 (2)监听 ...
- Flume的概述和安装部署
一.Flume概述 Flume是一种分布式.可靠且可用的服务,用于有效的收集.聚合和移动大量日志文件数据.Flume具有基于流数据流的简单灵活的框架,具有可靠的可靠性机制和许多故障转移和恢复机制,具有 ...
- Spark-Unit1-spark概述与安装部署
一.Spark概述 spark官网:spark.apache.org Spark是用的大规模数据处理的统一计算引擎,它是为大数据处理而设计的快速通用的计算引擎.spark诞生于加油大学伯克利分校AMP ...
- Kafka介绍及安装部署
本节内容: 消息中间件 消息中间件特点 消息中间件的传递模型 Kafka介绍 安装部署Kafka集群 安装Yahoo kafka manager kafka-manager添加kafka cluste ...
- Kafka 集群安装部署
2.1 安装部署 2.1.1 集群规划 192.168.1.102 192.168.1.103 192.168.1.104 zookeeper zookeeper zookeeper kafka ka ...
- kafka集群安装部署
kafka集群安装 使用的版本 系统:centos6.5 centos6.7 jdk:1.7.0_79 zookeeper:3.4.9 kafka:2.10-0.10.1.0 一.环境准备[只列,不具 ...
- centos7下kafka集群安装部署
应用摘要: Apache kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的 分布式发布订阅消息系统,是消息中间件的一种,用于构建实时 ...
随机推荐
- Swift 学习- 05 -- 集合类型
// 集合类型 // swift 提供 Arrays , Sets 和 Dictionaries 三种基本的集合类型用来存储数据 , 数组(Arrays) 是有序数据的集, 集合(Sets)是无序无重 ...
- Confluence 6 从生产环境中恢复一个测试实例
请参考 Restoring a Test Instance from Production 页面中的内容获得更多完整的说明. 很多 Confluence 的管理员将会使用生产实例运行完整数据和服务的 ...
- (六)STL仿函数functor
1.仿函数为算法服务,特点是重载操作符() 2.一共分为3大类,包括算术类,逻辑运算类,相对关系(比较大小):都继承了binary_function 3.仿函数的一些调用示例,其中右边的仿函数没有继承 ...
- Java测试代码(很不完整,建议大家别看,过几天会再发一次难的版本)
package ATM; import java.io.BufferedReader; import java.io.InputStreamReader; class Account{ priv ...
- LeetCode(86):分隔链表
Medium! 题目描述: 给定一个链表和一个特定值 x,对链表进行分隔,使得所有小于 x 的节点都在大于或等于 x 的节点之前. 你应当保留两个分区中每个节点的初始相对位置. 示例: 输入: hea ...
- light1370 欧拉函数打表
/* 给定n个数ai,要求欧拉函数值大于ai的最小的数bi 求sum{bi} */ #include<bits/stdc++.h> using namespace std; #define ...
- jQuery File Upload的使用
jQuery File Upload 是一个Jquery文件上传组件,支持多文件上传.取消.删除,上传前缩略图预览.列表显示图片大小,支持上传进度条显示等,以下就介绍一下该插件的简单使用 1.需要加载 ...
- vue中Axios的封装和API接口的管理
前端小白的声明: 这篇文章为转载:主要是为了方便自己查阅学习.如果对原博主造成侵犯,我会立即删除. 转载地址:点击查看 如图,面对一团糟代码的你~~~真的想说,What F~U~C~K!!! 回归正题 ...
- Python GUI界面编程
常用GUI框架 wxPython 安装wxPython pip install -U wxPython C:\Users> pip install -U wxPython Collecting ...
- python DLL接口测试
#coding=utf-8 import clr import sys import threading from itertools import permutations sys.path.app ...