Spark操作parquet文件
package code.parquet import java.net.URI import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{Path, FileSystem}
import org.apache.spark.sql.{SaveMode, SparkSession} /**
* Created by zhen on 2018/12/11.
*/
object ParquetIO {
// 指定hdfs根节点
private val hdfsRoot = "hdfs://172.20.32.163:8020"
// 获取HDFS路径
def getPath(path: String): Path = {
if (path.toLowerCase().startsWith("hdfs://")) {
new Path(path)
} else {
new Path(hdfsRoot + path)
}
}
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("parquet").master("local[2]").getOrCreate()
spark.sparkContext.setLogLevel("WARN") // 设置日志级别为WARN
val fsUri = new URI(hdfsRoot)
val fs = FileSystem.get(fsUri, new Configuration())
val path = hdfsRoot + "/YXFK/compute/KH_JLD"
val has = fs.exists(getPath(path))
if(has){
// 读取hdfs文件系统parquet数据
val dataFrame = spark.read.parquet(path)
dataFrame.show(10)
// 筛选,过滤数据
val result = dataFrame.select("JLDBH", "JLDDZ", "JLDMC", "JLFSDM", "CJSJ")
.filter("JLDDZ is not null AND JLFSDM = 3")
.sort("JLDBH")
result.show(10)
// 写入部分数据到本地
result.write.mode(SaveMode.Overwrite).parquet("E:\\result")
}
// 读取本地parquet数据
val localDataFrame = spark.read.parquet("E:\\jld.parquet")
localDataFrame.show(10)
// 读取写入数据验证
val resultSpace = spark.read.parquet("E:\\result")
resultSpace.show(10)
}
}
结果:
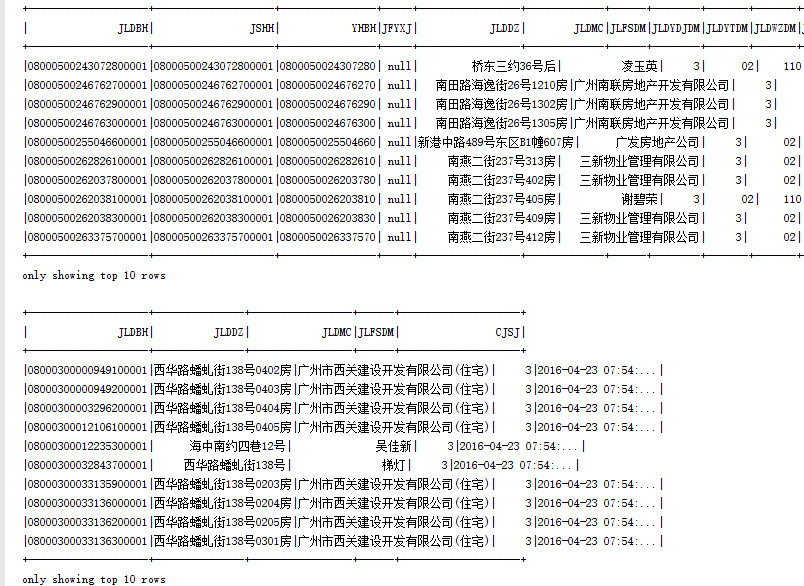

分析:Spark读取parquet数据默认为目录,因此可以只指定到你要读取的上级目录即可(本地模式除外),当保存为parquet时,会自动拆分,因此只能指定为上级目录。


Spark操作parquet文件的更多相关文章
- python读取hdfs上的parquet文件方式
在使用python做大数据和机器学习处理过程中,首先需要读取hdfs数据,对于常用格式数据一般比较容易读取,parquet略微特殊.从hdfs上使用python获取parquet格式数据的方法(当然也 ...
- Spark SQL读parquet文件及保存
import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.sql.{Row, SparkSession} im ...
- 大数据:Parquet文件存储格式
一.Parquet的组成 Parquet仅仅是一种存储格式,它是语言.平台无关的,并且不需要和任何一种数据处理框架绑定,目前能够和Parquet适配的组件包括下面这些,可以看出基本上通常使用的查询引擎 ...
- 大数据:Parquet文件存储格式【转】
一.Parquet的组成 Parquet仅仅是一种存储格式,它是语言.平台无关的,并且不需要和任何一种数据处理框架绑定,目前能够和Parquet适配的组件包括下面这些,可以看出基本上通常使用的查询引擎 ...
- Spark SQL 小文件问题处理
在生产中,无论是通过SQL语句或者Scala/Java等代码的方式使用Spark SQL处理数据,在Spark SQL写数据时,往往会遇到生成的小文件过多的问题,而管理这些大量的小文件,是一件非常头疼 ...
- Spark操作hbase
于Spark它是一个计算框架,于Spark环境,不仅支持单个文件操作,HDFS档,同时也可以使用Spark对Hbase操作. 从企业的数据源HBase取出.这涉及阅读hbase数据,在本文中尽快为了尽 ...
- scala读取parquet文件
import org.apache.spark.SparkConfimport org.apache.spark.SparkContextimport org.apache.spark.sql.SQL ...
- Spark操作实战
1. local模式 $SPARK_HOME/bin/spark-shell --master local import org.apache.log4j.{Level,Logger} // 导入ja ...
- 大数据学习day20-----spark03-----RDD编程实战案例(1 计算订单分类成交金额,2 将订单信息关联分类信息,并将这些数据存入Hbase中,3 使用Spark读取日志文件,根据Ip地址,查询地址对应的位置信息
1 RDD编程实战案例一 数据样例 字段说明: 其中cid中1代表手机,2代表家具,3代表服装 1.1 计算订单分类成交金额 需求:在给定的订单数据,根据订单的分类ID进行聚合,然后管理订单分类名称, ...
随机推荐
- Android--Service之基础
前言 本篇博客聊一下Android下的Service组件,对于Service组件,有点类似于Windows下的服务.Service是Android四大组件中与Activity最相似的组件,它们的区别在 ...
- 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装爬虫框架Scrapy(离线方式和在线方式)(图文详解)
不多说,直接上干货! 参考博客 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装OpenCV(离线方式和在线方式)(图文详解) 第一步:首先,提示升级下pip 第二步 ...
- salesforce零基础学习(九十二)使用Ant Migration Tool 实现Metadata迁移
我们在做项目时经常会使用changeset作为部署工具,但是某些场景使用changeset会比较难操作,比如当我们在sandbox将apex class更改名字想要部署到生产的org或者其他环境的or ...
- Spring mybatis源码篇章-MapperScannerConfigurer关联dao接口
前言:Spring针对Mybatis的XML方式的加载MappedStatement,通过引入MapperScannerConfigurer扫描类来关联相应的dao接口以供Service层调用.承接前 ...
- java基础系列--volatile关键字
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/7833881.html 1.volatile简述 据说,volatile是java语言中最轻 ...
- 如何快速使用Access实现一个登录验证界面?
大三上学期期末总结,嗯,没错,上学期,写在新学期开始,hhhh. 上学期末的时候信管班的一个同学问我会不会Access,能不能它实现一个登录验证界面,说实话,之前对Access只是有所耳闻,随便敷衍了 ...
- Perl文件句柄引用
目前还没介绍Perl的面向对象,所以这节内容除了几个注意点,没什么可讲的. 以前经常使用大写字母的句柄方式(即所谓的裸字文件句柄,bareword filehandle),现在可以考虑转向使用变量文件 ...
- javascript小实例,实现99乘法表及隔行变色
人生短暂,废话不多说,直奔主题! 这个小实例的要求: 实现在页面中输出99乘法表.(要求:以每三行为一组,实现隔行变色(颜色为白,红,黄(也可自己定义)),鼠标滑过每一行,行背景颜色变为蓝色,鼠标离开 ...
- 第一册:lesson fifty three。
原文: An interesting climate. A:where do you come from? B:I come from England. A:What's the climate li ...
- C#调用存储过程执行缓慢,但在数据库中执行却很快的问题
参考: http://www.debugease.com/mssqlbasic/976568.html https://www.cnblogs.com/Irving/p/3951220.html ht ...