EntityFramework Core 2.0 Explicitly Compiled Query(显式编译查询)
前言
EntityFramework Core 2.0引入了显式编译查询,在查询数据时预先编译好LINQ查询便于在请求数据时能够立即响应。显式编译查询提供了高可用场景,通过使用显式编译的查询可以提高查询性能。EF Core已经使用查询表达式的散列来表示自动编译和缓存查询,当我们的代码需要重用以前执行的查询时,EF Core将使用哈希查找并从缓存中返回已编译的查询。我们更希望直接使用编译查询绕过散列计算和高速缓存查找。
EntityFramework Core 2.0显式编译查询
比如我们要从博客实体中通过主键查询博客同时饥饿加载发表文章的集合列表,如下:
var id = ;
using (var context = new EFCoreDbContext())
{
var blog = context.Blogs
.AsNoTracking()
.Include(c => c.Posts)
.Where(c => c.Id == id)
.FirstOrDefault();
}
当进行上述查询时,此时要经过编译翻译阶段最终返回实际结果,比如在Web网站上这样的请求很频繁,此时将严重影响响应速度导致页面加载数据过慢。从Web程序应用角度来看我们大可利用ASP.NET Core中的响应式缓存,在实际应用中我们会将查询封装为方法来使用,我们无法优化结果和查询方式,但是我们能够通过编译查询来提前保存好数据以达到缓存的效果。通过EF静态类中的扩展方法CompileQuery来实现。如下:
static async Task<Blog> GetBlogAsync(EFCoreDbContext context, int id)
{
Func<EFCoreDbContext, int, Task<Blog>> blog = EF.CompileAsyncQuery((EFCoreDbContext context, int Id) =>
context.Blogs.Include(c => c.Posts)
.Where(c => c.Id == Id)
.FirstOrDefault());
return await blog(context, id);
}
常规查询和显式编译查询性能比较
接下来我们测试常规查询和使用显式编译查询的性能,我们利用EF Core提供的内存数据库来测试避免使用SQL Server数据库,利用SQL Server数据库很难去比较二者性能问题,因为数据库会进行查询计划优化和缓存,利用内存数据库只知道当前执行的查询不会进行任何优化, 首先我们下载EF Core内存数据库。额外再说明一点内存数据库在进行单元测试时很有意义。
接下来我们首先测试常规查询,我们预先在内存数据库中创建50条记录,然后查询十万次数据,这样来看每一次查询都会再次重新编译。
public static void Main(string[] args)
{
var options = new DbContextOptionsBuilder<EFCoreDbContext>()
.UseInMemoryDatabase(Guid.NewGuid().ToString())
.Options;
var context = new EFCoreDbContext(options); var stopWatch = new Stopwatch();
FillBlogs(context);
stopWatch.Start();
for (var i = ; i < ; i++)
{
GetUnCompileQueryBlog(context);
}
stopWatch.Stop();
Console.Write("Compiling time:");
Console.WriteLine(stopWatch.Elapsed);
Console.ReadKey();
} static void FillBlogs(EFCoreDbContext context)
{
for (var i = ; i < ; i++)
{
context.Blogs.Add(new Blog
{
Name = "Jeffcky",
CreatedTime = DateTime.Now,
Url = "http://www.cnblogs/com/CreateMyself",
ModifiedTime = DateTime.Now,
Posts = new List<Post>()
{
new Post()
{
CommentCount = i, CreatedTime = DateTime.Now,
ModifiedTime = DateTime.Now, Name = "EF Core"
}
}
});
}
context.SaveChanges(true);
} static Blog GetUnCompileQueryBlog(EFCoreDbContext context)
{
return context.Blogs.Include(c => c.Posts)
.OrderBy(o => o.Id)
.FirstOrDefault();
}
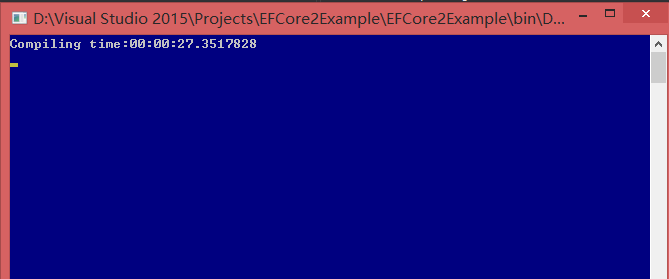
我们看到上述利用常规查询总耗时27秒,接下来我们再来看看显式编译查询耗时情况。
private static Func<EFCoreDbContext, Blog> _getCompiledBlog = EF.CompileQuery((EFCoreDbContext context) =>
context.Blogs.Include(c => c.Posts)
.OrderBy(o => o.Id)
.FirstOrDefault());
var options = new DbContextOptionsBuilder<EFCoreDbContext>()
.UseInMemoryDatabase(Guid.NewGuid().ToString())
.Options;
var context = new EFCoreDbContext(options); var stopWatch = new Stopwatch();
FillBlogs(context);
stopWatch.Start();
for (var i = ; i < ; i++)
{
GetCompileQueryBlog(context);
}
stopWatch.Stop();
Console.Write("Compiling time:");
Console.WriteLine(stopWatch.Elapsed);
Console.ReadKey();
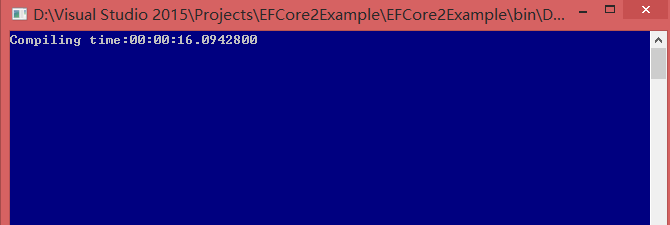
如上通过显式编译查询耗时16秒,那么是不是就说明显式编译查询性能一定优于常规查询呢?显然不是这样,上述只是简单的测试方法,有可能运行多次显式编译查询性能还低于常规查询,所以上述简单的测试方法并不能看出常规查询和显式编译查询之间的性能差异,当查询基数足够大时则能通过机器明显看出二者之间的性能差异,这也就说明了为什么EntityFramework Core官方文档说明显式编译查询的高可用。但是显式编译查询还有且缺点,当我们进行如下查询呢?
public static void Main(string[] args)
{
var options = new DbContextOptionsBuilder<EFCoreDbContext>()
.UseInMemoryDatabase(Guid.NewGuid().ToString())
.Options;
var context = new EFCoreDbContext(options); var blogs = GetCompileQueryBlogs(context); Console.ReadKey();
} static Blog[] GetCompileQueryBlogs(EFCoreDbContext context)
{
Func<EFCoreDbContext, Blog[]> func = EF.CompileQuery((EFCoreDbContext db) =>
db.Blogs.Include(c => c.Posts)
.OrderBy(o => o.Id)
.ToArray()); return func(context);
}
}
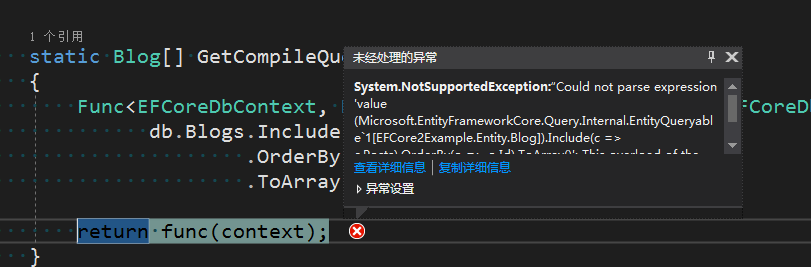
当前EntityFramework Core 2.0.1版本对于显式编译查询还不支持返回IEnumerable<T>, IQueryable<T>的集合类型,期待未来能够有所支持。
总结缺陷
显式编译查询提供高可用场景,但是仍然存在其缺陷,期待未来能有更多支持,希望给阅读的您一点帮助。精简的内容,简单的讲解,希望对阅读的您有所帮助,我们明天再会。
EntityFramework Core 2.0 Explicitly Compiled Query(显式编译查询)的更多相关文章
- EntityFramework Core 2.0执行原始查询如何防止SQL注入?
前言 接下来一段时间我们来讲讲EntityFramework Core基础,精简的内容,深入浅出,希望为想学习EntityFramework Core的童鞋提供一点帮助. EntityFramewor ...
- EntityFramework Core 2.0全局过滤(HasQueryFilter)
前言 EntityFramework Core每一次版本的迭代和更新都会带给我们惊喜,每次都会尽量满足大部分使用者的需求.在EF Core 2.0版本中出现了全局过滤新特性即HasQueryFilte ...
- .NetCore技术研究-EntityFramework Core 3.0 Preview
前段时间.Net Core 3.0 发布了,Entity Framework Core 3.0 也发布了Preview版.假期用了一上午大致研究了一遍,同时又体验了一把Visual Studio 20 ...
- EntityFramework Core 2.0自定义标量函数两种方式
前言 上一节我们讲完原始查询如何防止SQL注入问题同时并提供了几种方式.本节我们继续来讲讲EF Core 2.0中的新特性自定义标量函数. 自定义标量函数两种方式 在EF Core 2.0中我们可以将 ...
- EntityFramework Core 3.0查询
前言 随着.NET Core 3.0的发布,EF Core 3.0也随之正式发布,关于这一块最近一段时间也没太多去关注,陆续会去对比之前版本有什么变化没有,本节我们来看下两个查询. 分组 我们知道在E ...
- CSS3 Media Query 响应式媒体查询
在CSS中,有一个极其实用的功能:@media 响应式布局.具体来说,就是可以根据客户端的介质和屏幕大小,提供不同的样式表或者只展示样式表中的一部分.通过响应式布局,可以达到只使用单一文件提供多平台的 ...
- Entity Framework Core 2.0 新特性
本文翻译来自:https://docs.microsoft.com/en-us/ef/core/what-is-new/index 一.模型级查询过滤器(Model-level query filte ...
- 《你必须掌握的Entity Framework 6.x与Core 2.0》书籍出版
前言 到目前为止写过刚好两百来篇博客,看过我博客的读者应该大概知道我每一篇博客都沿袭着一贯的套路,从前言到话题最终到总结,本文依然是一如既往的套路,但是不是介绍技术,也可说是介绍技术,不过是介绍书中的 ...
- .Net Core 2.0生态(4):Entity Framework Core 2.0 特性介绍和使用指南
前言 这是.Net Core 2.0生态生态介绍的最后一篇,EF一直是我喜欢的一个ORM框架,随着版本升级EF也发展到EF6.x,Entity Framework Core是一个支持跨平台的全新版本, ...
随机推荐
- Linux内核链表-通用链表的实现
最近编程总想着参考一些有名的开源代码是如何实现的,因为要写链表就看了下linux内核中对链表的实现. 链表是一种非常常见的数据结构,特别是在动态创建相应数据结构的情况下更是如此,然而在操作系统内核中, ...
- R语言-选择样本数量
功效分析:可以帮助在给定置信度的情况下,判断检测到给定效应值时所需的样本量,也可以在给定置信水平的情况下,计算某样本量内可以检测到的给定效应值的概率 1.t检验 案例:使用手机和司机反应时间的实验 l ...
- C++ 内存分配(new,operator new)面面观 (转)
本文主要讲述C++ new运算符和operator new, placement new之间的种种关联,new的底层实现,以及operator new的重载和一些在内存池,STL中的应用. 一 new ...
- [Python Study Notes] 抉择--Python2.x Or Python 3.x
In summary : Python 2.x is legacy, Python 3.x is the present and future of the language Python 3.0 w ...
- 定制化WinPE
1 .首先挂载wim Dism /Mount-WIM /WimFile:D:\install.wim /Index: /MountDir:D:\wimmount 2. 如何要修改WinPE的启动项,可 ...
- VS2015安装时问题汇总
安装VS2015遇到teamexplorer严重错误 在控制台管理员权限执行: fsutil behavior set SymlinkEvaluation L2L:1 L2R:1 R2L:1 R2R: ...
- ansible安装
本文来自我的github pages博客http://galengao.github.io/ 即www.gaohuirong.cn 1.配置epel源 wget -O /etc/yum.repos.d ...
- kaggle-titanic 数据分析过程
1. 引入所有需要的包 # -*- coding:utf-8 -*- # 忽略警告 import warnings warnings.filterwarnings('ignore') # 引入数据处理 ...
- Java中的volatile的作用和synchronized作用
volatile该关键字是主要使用的场合是字啊多个线程中可以感知实例的变量被更改了并且可以获取到最新的值进行使用,也就是用多线程读取共享变量的时候可以获取到最新的值使用.不能保障原子性 如果你在jvm ...
- uva1343 IDA*
这题需要用数组记录每个block的位置.启发函数:d+wa(8-当前最多相同个数)>maxd直接退出 AC代码: #include<cstdio> #include<cstri ...