论文笔记——SQUEEZENET ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
论文地址:https://arxiv.org/abs/1602.07360
模型地址:https://github.com/DeepScale/SqueezeNet
1. 论文思想
提出一种新的卷积组合方式替代原来的3*3的卷积。类似于bottleneck layer减少参数数目。但是不太像MobileNet是提出了一种新的卷积计算方式来减少参数,加速计算。
2. 网络结构设计策略
- 用3*3的替代1*1的filter。 (NiN, GoogLeNet)
- 减少3*3的输入channel数目。 (bottleneck layer)
- 延迟下采样(so that convolution layers have large activation maps. (He & Sun)
3. 组合方式

squeeze中的1*1的卷积为了减少输入到3*3中的channel数目
expand中的1*1和3*3的卷积,也算是一种效果的综合吧。(不能全是3*3的,不然论文就没有什么创新了。不能全是1*1的卷积,估计会影响效果。)
4. 网络结构
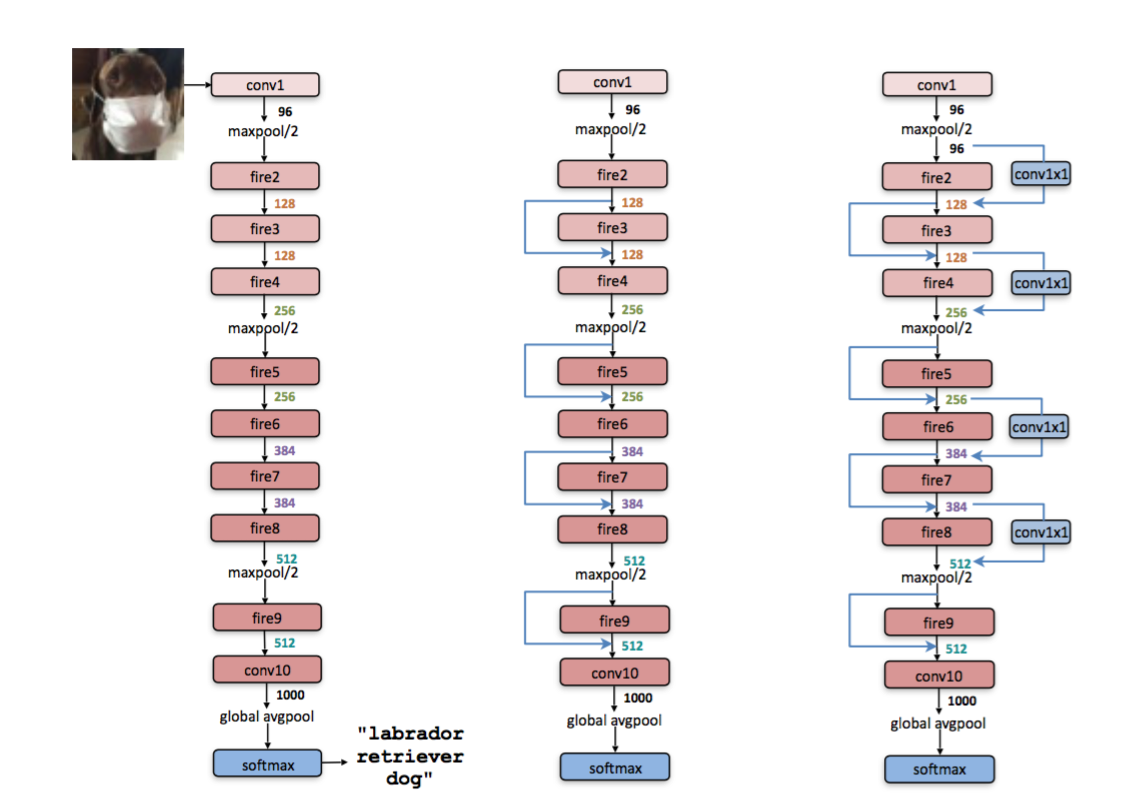
- SqueezeNet
- SqueezeNet with simple bypass(类似于ResNet,因为要做加操作,要求两个输入的channel num一样,所以只能在某些层加bypass)
- SqueezeNet with complex bypass(添加1*1的卷积,打破上面那个限制)
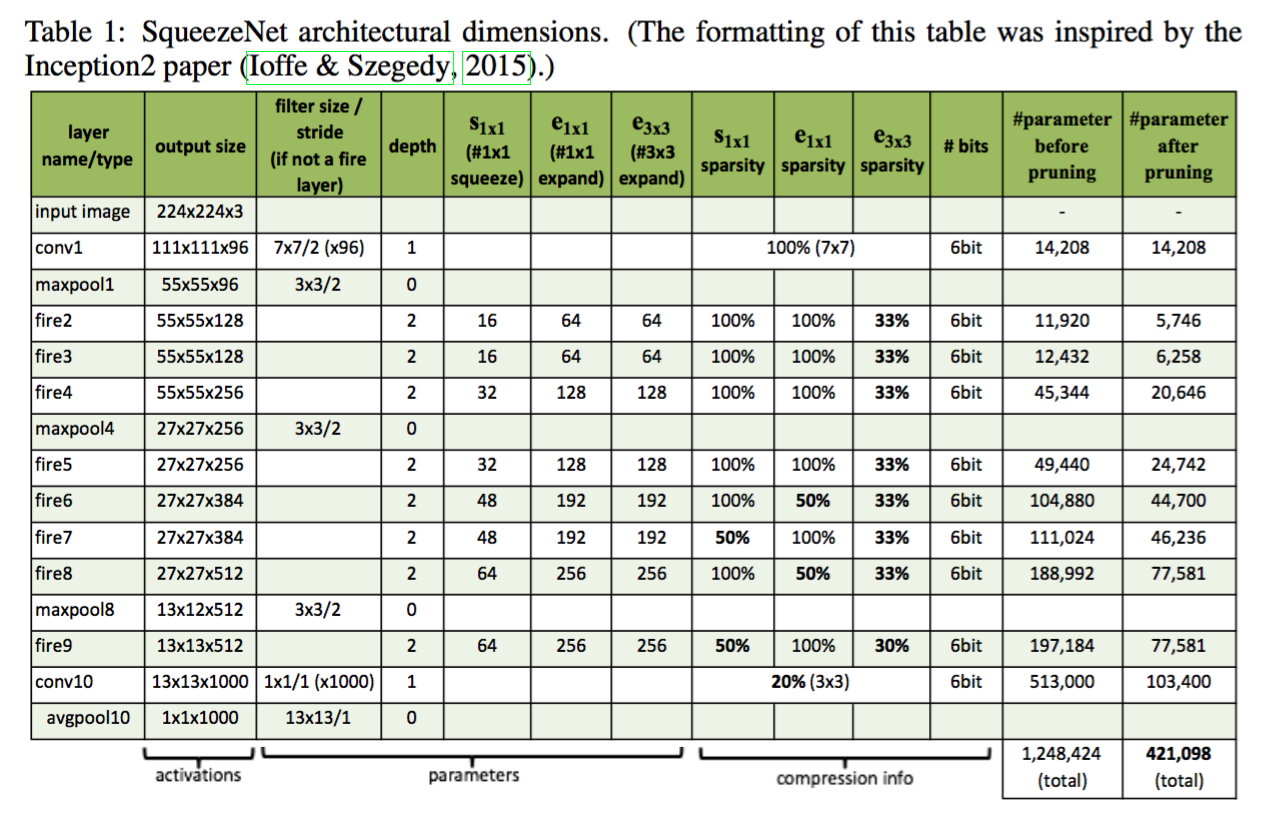
- compression info 应用的是Deep compression里面的稀疏性和量化的方法。
5. 组合方式探索
探索了几个超参数不同组合方式对网络大小以及准确率的影响。
结果

6. 总结
- 在AlexNet上实现了50x的缩减,模型大小小于0.5MB。
- 探索较深网络的时候,可以尝试这种方法。
- 又是一篇在1*1的卷积上做工作的文章。(MobileNet, ShuffleNet)
论文笔记——SQUEEZENET ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE的更多相关文章
- SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
论文阅读笔记 转载请注明出处: http://www.cnblogs.com/sysuzyq/p/6186518.html By 少侠阿朱
- SqueezeNet:AlexNet-level Accuracy with 50x fewer parameters and less than 0.5Mb model size
- Fire modules consisting of a 'squeeze' layer with 1*1 filters feeding an 'expand' layer with 1*1 a ...
- 论文笔记:CNN经典结构1(AlexNet,ZFNet,OverFeat,VGG,GoogleNet,ResNet)
前言 本文主要介绍2012-2015年的一些经典CNN结构,从AlexNet,ZFNet,OverFeat到VGG,GoogleNetv1-v4,ResNetv1-v2. 在论文笔记:CNN经典结构2 ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
随机推荐
- mysql 内置功能 存储过程 创建有参存储过程
对于存储过程,可以接收参数,其参数有三类: #in 仅用于传入参数用 #out 仅用于返回值用 #inout 既可以传入又可以当作返回值 传入参数使用格式 in 变量 数据类型 返回值使用格式 out ...
- CSS表格(未完成)
CSS 表格 使用 CSS 可以使 HTML 表格更美观. 表格边框 指定CSS表格边框,使用border属性. 下面的例子指定了一个表格的Th和TD元素的黑色边框:
- IO操作文件的复制与删除
import java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.IO ...
- for与while的特点及其if在什么情况下使用情况
for和while的特点: 什么时候使用循环结构呢? 1:当对某些代码执行很多次时,使用循环结构完成. 2:当对一个条件进行一次判断时,可以使用if语句. 3:当对一个条件进行多次判断时,可以使用wh ...
- 字符串最长子串匹配-dp矩阵[转载]
转自:https://blog.csdn.net/zls986992484/article/details/69863710 题目描述:求最长公共子串,sea和eat.它们的最长公共子串为ea,长度为 ...
- 【转】 Oracle 用户权限管理方法
sys;//系统管理员,拥有最高权限 system;//本地管理员,次高权限 scott;//普通用户,密码默认为tiger,默认未解锁 sys;//系统管理员,拥有最高权限 system;//本地管 ...
- Locust性能测试3-no-web模式和csv报告保存
前言 前面是在web页面操作,需要手动的点start启动,结束的时候也需要手工去点stop,没法自定义运行时间,这就不太方便. locust提供了命令行运行的方法,不启动web页面也能运行,这就是no ...
- DataTable转换成IList 【转载】
链接:http://www.cnblogs.com/hlxs/archive/2011/05/09/2087976.html#2738813 留着学习 using System; using Syst ...
- java数据结构经典问题
A:栈抽象数据类型 1.栈的主要操作 void push(int data);将data数据插入栈中. int pop();删除并返回最后一个插入栈的元素. 2.栈的辅助操作 int top();返回 ...
- 模仿WIN32程序处理消息
#include "stdafx.h" #include "MyMessage.h" #include <conio.h> using namesp ...