spring实现数据库读写分离
现在大型的电子商务系统,在数据库层面大都采用读写分离技术,就是一个Master数据库,多个Slave数据库。Master库负责数据更新和实时数据查询,Slave库当然负责非实时数据查询。因为在实际的应用中,数据库都是读多写少(读取数据的频率高,更新数据的频率相对较少),而读取数据通常耗时比较长,占用数据库服务器的CPU较多,从而影响用户体验。我们通常的做法就是把查询从主库中抽取出来,采用多个从库,使用负载均衡,减轻每个从库的查询压力。
采用读写分离技术的目标:有效减轻Master库的压力,又可以把用户查询数据的请求分发到不同的Slave库,从而保证系统的健壮性。我们看下采用读写分离的背景。
随着网站的业务不断扩展,数据不断增加,用户越来越多,数据库的压力也就越来越大,采用传统的方式,比如:数据库或者SQL的优化基本已达不到要求,这个时候可以采用读写分离的策 略来改变现状。
具体到开发中,如何方便的实现读写分离呢?目前常用的有两种方式:
1 第一种方式是我们最常用的方式,就是定义2个数据库连接,一个是MasterDataSource,另一个是SlaveDataSource。更新数据时我们读取MasterDataSource,查询数据时我们读取SlaveDataSource。这种方式很简单,我就不赘述了。
2 第二种方式动态数据源切换,就是在程序运行时,把数据源动态织入到程序中,从而选择读取主库还是从库。主要使用的技术是:annotation,Spring AOP ,反射。下面会详细的介绍实现方式。
在介绍实现方式之前,我们先准备一些必要的知识,spring 的AbstractRoutingDataSource 类
AbstractRoutingDataSource这个类 是spring2.0以后增加的,我们先来看下AbstractRoutingDataSource的定义:
public abstract class AbstractRoutingDataSource extends AbstractDataSource implements InitializingBean {}
AbstractRoutingDataSource继承了AbstractDataSource ,而AbstractDataSource 又是DataSource 的子类。DataSource 是javax.sql 的数据源接口,定义如下:
public interface DataSource extends CommonDataSource,Wrapper {
/**
* <p>Attempts to establish a connection with the data source that
* this <code>DataSource</code> object represents.
*
* @return a connection to the data source
* @exception SQLException if a database access error occurs
*/
Connection getConnection() throws SQLException;
/**
* <p>Attempts to establish a connection with the data source that
* this <code>DataSource</code> object represents.
*
* @param username the database user on whose behalf the connection is
* being made
* @param password the user's password
* @return a connection to the data source
* @exception SQLException if a database access error occurs
* @since 1.4
*/
Connection getConnection(String username, String password)
throws SQLException;
}
DataSource 接口定义了2个方法,都是获取数据库连接。我们在看下AbstractRoutingDataSource 如何实现了DataSource接口:
public Connection getConnection() throws SQLException {
return determineTargetDataSource().getConnection();
}
public Connection getConnection(String username, String password) throws SQLException {
return determineTargetDataSource().getConnection(username, password);
}
很显然就是调用自己的determineTargetDataSource() 方法获取到connection。determineTargetDataSource方法定义如下:
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources, "DataSource router not initialized");
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException("Cannot determine target DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}
我们最关心的还是下面2句话:
Object lookupKey = determineCurrentLookupKey();
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
determineCurrentLookupKey方法返回lookupKey,resolvedDataSources方法就是根据lookupKey从Map中获得数据源。resolvedDataSources 和determineCurrentLookupKey定义如下:
private Map<Object, DataSource> resolvedDataSources;
protected abstract Object determineCurrentLookupKey()
看到以上定义,我们是不是有点思路了,resolvedDataSources是Map类型,我们可以把MasterDataSource和SlaveDataSource存到Map中,如下:
key value
master MasterDataSource
slave SlaveDataSource
我们在写一个类DynamicDataSource 继承AbstractRoutingDataSource,实现其determineCurrentLookupKey() 方法,该方法返回Map的key,master或slave。
好了,说了这么多,有点烦了,下面我们看下怎么实现。
上面已经提到了我们要使用的技术,我们先看下annotation的定义:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface DataSource {
String value();
}
我们还需要实现spring的抽象类AbstractRoutingDataSource,就是实现determineCurrentLookupKey方法:
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
// TODO Auto-generated method stub
return DynamicDataSourceHolder.getDataSouce();
}
}
public class DynamicDataSourceHolder {
public static final ThreadLocal<String> holder = new ThreadLocal<String>();
public static void putDataSource(String name) {
holder.set(name);
}
public static String getDataSouce() {
return holder.get();
}
}
从DynamicDataSource 的定义看出,他返回的是DynamicDataSourceHolder.getDataSouce()值,我们需要在程序运行时调用DynamicDataSourceHolder.putDataSource()方法,对其赋值。下面是我们实现的核心部分,也就是AOP部分,DataSourceAspect定义如下:
public class DataSourceAspect {
public void before(JoinPoint point)
{
Object target = point.getTarget();
String method = point.getSignature().getName();
Class<?>[] classz = target.getClass().getInterfaces();
Class<?>[] parameterTypes = ((MethodSignature) point.getSignature())
.getMethod().getParameterTypes();
try {
Method m = classz[0].getMethod(method, parameterTypes);
if (m != null && m.isAnnotationPresent(DataSource.class)) {
DataSource data = m
.getAnnotation(DataSource.class);
DynamicDataSourceHolder.putDataSource(data.value());
System.out.println(data.value());
}
} catch (Exception e) {
// TODO: handle exception
}
}
}
为了方便测试,我定义了2个数据库,shop模拟Master库,test模拟Slave库,shop和test的表结构一致,但数据不同,数据库配置如下:
<bean id="masterdataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://127.0.0.1:3306/shop" />
<property name="username" value="root" />
<property name="password" value="yangyanping0615" />
</bean> <bean id="slavedataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://127.0.0.1:3306/test" />
<property name="username" value="root" />
<property name="password" value="yangyanping0615" />
</bean> <beans:bean id="dataSource" class="com.air.shop.common.db.DynamicDataSource">
<property name="targetDataSources">
<map key-type="java.lang.String">
<!-- write -->
<entry key="master" value-ref="masterdataSource"/>
<!-- read -->
<entry key="slave" value-ref="slavedataSource"/>
</map> </property>
<property name="defaultTargetDataSource" ref="masterdataSource"/>
</beans:bean> <bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean> <!-- 配置SqlSessionFactoryBean -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="configLocation" value="classpath:config/mybatis-config.xml" />
</bean>
在spring的配置中增加aop配置
<!-- 配置数据库注解aop -->
<aop:aspectj-autoproxy></aop:aspectj-autoproxy>
<beans:bean id="manyDataSourceAspect" class="com.air.shop.proxy.DataSourceAspect" />
<aop:config>
<aop:aspect id="c" ref="manyDataSourceAspect">
<aop:pointcut id="tx" expression="execution(* com.air.shop.mapper.*.*(..))"/>
<aop:before pointcut-ref="tx" method="before"/>
</aop:aspect>
</aop:config>
<!-- 配置数据库注解aop -->
下面是MyBatis的UserMapper的定义,为了方便测试,登录读取的是Master库,用户列表读取Slave库:
public interface UserMapper {
@DataSource("master")
public void add(User user);
@DataSource("master")
public void update(User user);
@DataSource("master")
public void delete(int id);
@DataSource("slave")
public User loadbyid(int id);
@DataSource("master")
public User loadbyname(String name);
@DataSource("slave")
public List<User> list();
}
好了,运行我们的Eclipse看看效果,输入用户名admin 登录看看效果
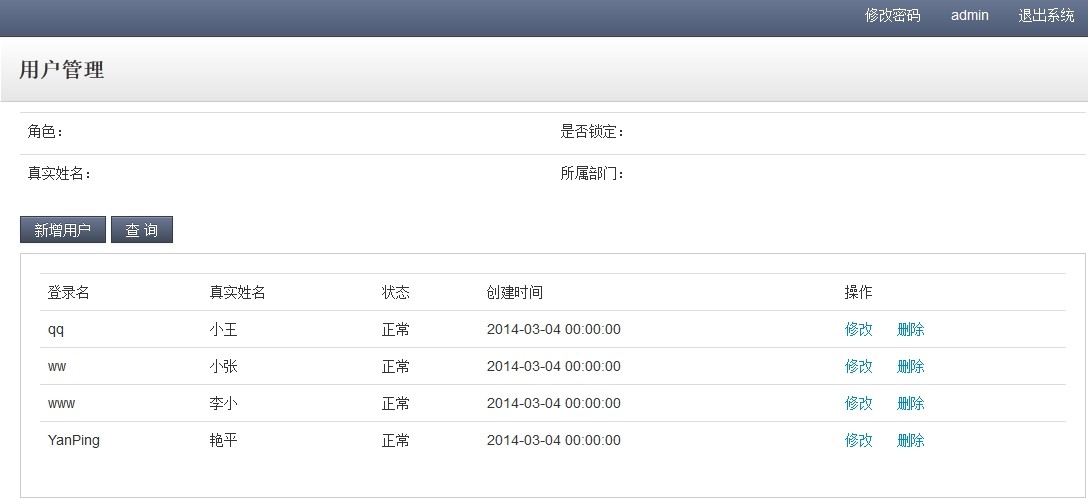
从图中可以看出,登录的用户和用户列表的数据是不同的,也验证了我们的实现,登录读取Master库,用户列表读取Slave库。
感谢阅读,希望这篇文章能给你带来帮助!
spring实现数据库读写分离的更多相关文章
- Spring 实现数据库读写分离
随着互联网的大型网站系统访问量的增高,数据库访问压力方面不断的显现而出,所以许多公司在数据库层面采用读写分离技术,也就是一个master,多个slave.master负责数据的实时更新或实时查询,而s ...
- Spring 实现数据库读写分离(转)
现在大型的电子商务系统,在数据库层面大都采用读写分离技术,就是一个Master数据库,多个Slave数据库.Master库负责数据更新和实时数据查询,Slave库当然负责非实时数据查询.因为在实际的应 ...
- 在应用层通过spring特性解决数据库读写分离
如何配置mysql数据库的主从? 单机配置mysql主从:http://my.oschina.net/god/blog/496 常见的解决数据库读写分离有两种方案 1.应用层 http://neore ...
- Spring aop应用之实现数据库读写分离
Spring加Mybatis实现MySQL数据库主从读写分离 ,实现的原理是配置了多套数据源,相应的sqlsessionfactory,transactionmanager和事务代理各配置了一套,如果 ...
- 161220、使用Spring AOP实现MySQL数据库读写分离案例分析
一.前言 分布式环境下数据库的读写分离策略是解决数据库读写性能瓶颈的一个关键解决方案,更是最大限度了提高了应用中读取 (Read)数据的速度和并发量. 在进行数据库读写分离的时候,我们首先要进行数据库 ...
- [转]Spring数据库读写分离
数据库的读写分离简单的说是把对数据库的读和写操作分开对应不同的数据库服务器,这样能有效地减轻数据库压力,也能减轻io压力. 主(master)数据库提供写操作,从(slave)数据库提供读操作,其实在 ...
- spring+mybatis利用interceptor(plugin)兑现数据库读写分离
使用spring的动态路由实现数据库负载均衡 系统中存在的多台服务器是"地位相当"的,不过,同一时间他们都处于活动(Active)状态,处于负载均衡等因素考虑,数据访问请求需要在这 ...
- Spring + Mybatis项目实现数据库读写分离
主要思路:通过实现AbstractRoutingDataSource类来动态管理数据源,利用面向切面思维,每一次进入service方法前,选择数据源. 1.首先pom.xml中添加aspect依赖 & ...
- Spring+MyBatis实现数据库读写分离方案
推荐第四种:https://github.com/shawntime/shawn-rwdb 方案1 通过MyBatis配置文件创建读写分离两个DataSource,每个SqlSessionFactor ...
随机推荐
- Dialog中显示倒计时,到时自己主动关闭
这里直接用系统Dialog中加入了倒计时的显示,假设用自己定义Dialog会更美观: private TextView mOffTextView; private Handler mOffHandle ...
- SHDocVw, AxSHDocVw的引用
原文:SHDocVw, AxSHDocVw的引用 SHDocVw的引用SHDocVw一定要在下面这个路径找: 类似 C:\Program Files\Microsoft Visual Studio 9 ...
- Android开展Exception:ActivityNotFoundException: Unable to find explicit activity class
project出现在一个以上的activity,不AndroidManifest.xml配置,在阅读的时候,你需要知道的配置activity,使用时间或忘记配置.流汗!配置activity后proje ...
- poj 3026 Borg Maze (bfs + 最小生成树)
链接:poj 3026 题意:y行x列的迷宫中,#代表阻隔墙(不可走).空格代表空位(可走).S代表搜索起点(可走),A代表目的地(可走),如今要从S出发,每次可上下左右移动一格到可走的地方.求到达全 ...
- tomcat加载类的顺序
/bin:存放启动和关闭tomcat的脚本文件: /conf:存放tomcat的各种配置文件,比如:server.xml /server/lib:存放tomcat服务器所需要的各种jar文件(jar文 ...
- IS2009制作Oracle 静默安装包(一)感谢空白先生特许授权
原文:IS2009制作Oracle 静默安装包(一)感谢空白先生特许授权 上一篇: MyEclipse中消除frame引起的“the file XXX can not be found.Please ...
- AngularJS + CoffeeScript
AngularJS + CoffeeScript 前端开发环境配置详解 AngularJS 号称 '第一框架' ('The first framework') 确实是名不虚传.由其从jQuery中完全 ...
- OCP-1Z0-051-题目解析-第4题
4. Which two statements are true regarding single row functions? (Choose two.) A. They a ccept only ...
- 在ubuntu下使用eclipse来调试ARM程序
该程序为外部Makefile project,导入到eclipse中来进行编译,之后使用Jlink来进行调试. 这个是因为你在编译的时候没有加-g这个标志,导致没有生成调试文件. 让你指定一个源文件. ...
- Mac OSX操作系统安装和配置Zend Server 6教程(3)
Zend Server安装好以后,在php.ini文件中,没有默认时区.就是导致很多警告信息出现的根本. 接下来,我们看看如果修改这个文件. 首先,进入php.ini文件.此文件在目录zend/etc ...