elasticsearch的rest搜索--- 查询
目录: 一、针对这次装B 的解释
四、 查询
四、 查询
1. 查询的官网的文档
- took —— Elasticsearch执行这个搜索的耗时,以毫秒为单位- timed_out —— 指明这个搜索是否超时
- _shards —— 指出多少个分片被搜索了,同时也指出了成功/失败的被搜索的shards的数量
- hits —— 搜索结果
- hits.total —— 能够匹配我们查询标准的文档的总数目
- hits.hits —— 真正的搜索结果数据(默认只显示前10个文档)- _score和max_score —— 现在先忽略这些字段
"query":{
"match":{
"UserName":"BWH-PC"
}
}
{
"query": {
"match": {
"text": "quick fox"
}
}
}
相当于
{
"query": {
"bool": {
"should": [
{
"term": {
"text": "quick"
}
},
{
"term": {
"text": "fox"
}
}
]
}
}
}
{
"query": {
"multi_match": {
"query": "bbc0641345dd8224ce81bbc79218a16f",
"operator": "or",
"fields": [
"*.machine"
]
}
}
}
{
"bool": {
"must": {
"match": {
"title": "how to make millions"
}
},
"must_not": {
"match": {
"tag": "spam"
}
},
"should": [
{
"match": {
"tag": "starred"
}
},
{
"range": {
"date": {
"gte": "2014-01-01"
}
}
}
]
}
}
"term": {
"CapabilityDescriptions": "aa"
}
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"query": {
"match": {
"description": "wifi"
}
}
}
},
{
"constant_score": {
"query": {
"match": {
"description": "garden"
}
}
}
},
{
"constant_score": {
"boost": {
"query": {
"match": {
"description": "pool"
}
}
}
}
}
]
}
}
}
missing相当于is null【没查到的是null】
{
"query": {
"filtered": {
"query": {
"match": {
"email": "business opportunity"
}
},
"filter": {
"term": {
"folder": "inbox"
}
}
}
}
}
{
"query": {
"filtered": {
"filter": {
"bool": {
"must": {
"term": {
"folder": "inbox"
}
},
"must_not": {
"query": {
"match": {
"email": "urgent business proposal"
}
}
}
}
}
}
}
}
"range": {
"price": {
"gt": 20,
"lt": 40
}
}
{
"query": {
"filtered": {
"filter": {
"range": {
"price": {
"gte": 20,
"lt": 40
}
}
}
}
}
}
{
"range": {
"timestamp": {
"gt": "2014-01-0100: 00: 00",
"lt": "2014-01-0700: 00: 00"
}
}
}
{
"range": {
"timestamp": {
"gt": "now-1h"
}
}
}
后置过滤--post_filter元素是一个顶层元素,只会对搜索结果进行过滤。警告:性能考量
只有当你需要对搜索结果和聚合使用不同的过滤方式时才考虑使用post_filter。有时一些用户会直接在常规搜索中使用post_filter。
不要这样做!post_filter会在查询之后才会被执行,因此会失去过滤在性能上帮助(比如缓存)。
post_filter应该只和聚合一起使用,并且仅当你使用了不同的过滤条件时。
{
"query": {
"query_string": {
"query": "*"
}
},
"post_filter": {
"bool": {
"should": {
"query": {
"bool": {
"should": [
{
"match": {
"machine": "bbc0641345dd8224ce81bbc79218a16f"
}
},
{
"match": {
"machine": "bbc0641345dd8224ce81bbc79218a16f"
}
}
]
}
}
}
}
}
}
当然,在里面的每一个should中,可以去做很多变形,但是should多个子类时,必须用[]
{
"query": {
"query_string": {
"query": "*"
}
},
"post_filter": {
"bool": {
"should": [
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "bbc0641345dd8224ce81bbc79218a16f",
"operator": "or",
"fields": [
"*.machine",
""
]
}
},
{
"multi_match": {
"query": "10.10.185.99",
"operator": "or",
"fields": [
"*.IPAddress",
""
]
}
}
]
}
}
},
{
"query": {
"bool": {
"must": [
{
"match": {
"machine": "bbc0641345dd8224ce81bbc79218a16f"
}
},
{
"match": {
"IPAddress": "10.10.11.11"
}
}
]
}
}
}
]
}
}
}


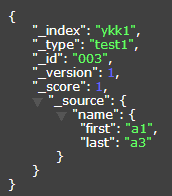
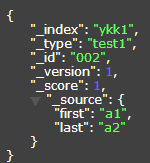
{
"query": {
"filtered": {
"query": {
"query_string": {
"query": "*"
}
},
"filter": {
"bool": {
"should": {
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "a2",
"operator": "or",
"fields": [
"*.last"
]
}
},
{
"match": {
"last": "a2"
}
}
]
}
}
}
}
}
}
}
}

elasticsearch的rest搜索--- 查询的更多相关文章
- ElasticSearch High Level REST API【2】搜索查询
如下为一段带有分页的简单搜索查询示例 在search搜索中大部分的搜索条件添加都可通过设置SearchSourceBuilder来实现,然后将SearchSourceBuilder RestHighL ...
- ElasticSearch第四步-查询详解
ElasticSearch系列学习 ElasticSearch第一步-环境配置 ElasticSearch第二步-CRUD之Sense ElasticSearch第三步-中文分词 ElasticSea ...
- ElasticSearch中的简单查询
前言 最近修改项目,又看了下ElasticSearch中的搜索,所以简单整理一下其中的查询语句等.都是比较基础的.PS,好久没写博客了..大概就是因为懒吧.闲言少叙书归正传. 查询示例 http:// ...
- ElasticSearch(8)-分布式搜索
分布式搜索的执行方式 在继续之前,我们将绕道讲一下搜索是如何在分布式环境中执行的. 它比我们之前讲的基础的增删改查(create-read-update-delete ,CRUD)请求要复杂一些. 注 ...
- ElasticSearch(6)-结构化查询
引用:ElasticSearch权威指南 一.请求体查询 请求体查询 简单查询语句(lite)是一种有效的命令行_adhoc_查询.但是,如果你想要善用搜索,你必须使用请求体查询(request bo ...
- ElasticSearch改造研报查询实践
背景: 1,系统简介:通过人工解读研报然后获取并录入研报分类及摘要等信息,系统通过摘要等信息来获得该研报的URI 2,现有实现:老系统使用MSSQL存储摘要等信息,并将不同的关键字分解为不同字段来提供 ...
- elasticsearch基本概念与查询语法
序言 后面有大量类似于mysql的sum, group by查询 elk === elk总体架构 https://www.elastic.co/cn/products Beat 基于go语言写的轻量型 ...
- Graylog日志管理系统---搜索查询方法使用简介
Elasticsearch 是一个基于 Lucene 构建的开源.分布式.提供 RESTful 接口的全文搜索引擎 一.Search页面的各位置功能介绍: 1.日志搜索的时间范围 为了使用方便,预设有 ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
随机推荐
- HDU 4313 Matrix
水题:在一个双连通的树上有一些点很有破坏性,我们要把这些带破环性的点隔开,就是破坏一些边使这些点之间不连通,破坏一条边需要一点时间,问最少需要多少时间(同一时间只能破坏一个地方,且忽略位置转移的时间) ...
- .net Quartz 服务 作业调度
.net项目中使用Quartz (1)在web.config中进行相关配置 <configSections> <section name="quartz" t ...
- hdu 神、上帝以及老天爷
HDU 2006'10 ACM contest的颁奖晚会隆重开始了! 为了活跃气氛,组织者举行了一个别开生面.奖品丰厚的抽奖活动,这个活动的具体要求是这样的: 首先,所有参加晚会的人员都将一张写有自己 ...
- 玩转Web之Json(一)-----easy ui+ajax + json 中关于Json的解析问题
在easy ui中使用Ajax+Json实现前后的数据交互时,当后台数据传输到客户端是需对Json数据进行解析,这里将对Json数据解析做简单总结. (一) 对于服务器返回的数据若没有做类型说明,需要 ...
- YT新人之巅峰大决战03
题目链接 Problem Description Now give you two integers n m, you just tell me the m-th number after radix ...
- Android - 用Fragments实现动态UI - 使用Android Support Library
Android Support Library提供了一个带有API库的JAR文件来让你可以在使用最新的Android API的同时也也已在早期版本的Android上运行.例如,Support Libr ...
- 开源:矿Android新闻client,快、小、支持离线阅读、操作简单、内容丰富,形式多样展示、的信息量、全功能 等待(离开码邮箱)
分享:矿Android新闻client.快.小.支持离线阅读.操作简单.内容丰富,形式多样展示.的信息量.全功能 等待(离开码邮箱) 历时30天我为了开发这个新闻clientAPP,下面简称觅闻 ht ...
- hdu 1575 Tr A(矩阵高速电源输入)
Tr A Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submi ...
- 猫学习IOS(四)UI半小时就搞定Tom猫
阿土 首先对影响 下载项目的源材料: Tom猫游戏代码iOS 素材http://blog.csdn.net/u013357243/article/details/44457357 效果图 以前风靡一时 ...
- Raw-OS互斥的源代码分析的量的Mutex
作为分析的内核版本2014-04-15,基于1.05正式版.blogs我们会跟上的内核开发进度的最新版本,如果出现源代码的目光"???"的话,没有深究的部分是理解. Raw-OS官 ...