深度学习面试题03:改进版梯度下降法Adagrad、RMSprop、Momentum、Adam
目录
Adagrad法
RMSprop法
Momentum法
Adam法
参考资料
发展历史

标准梯度下降法的缺陷
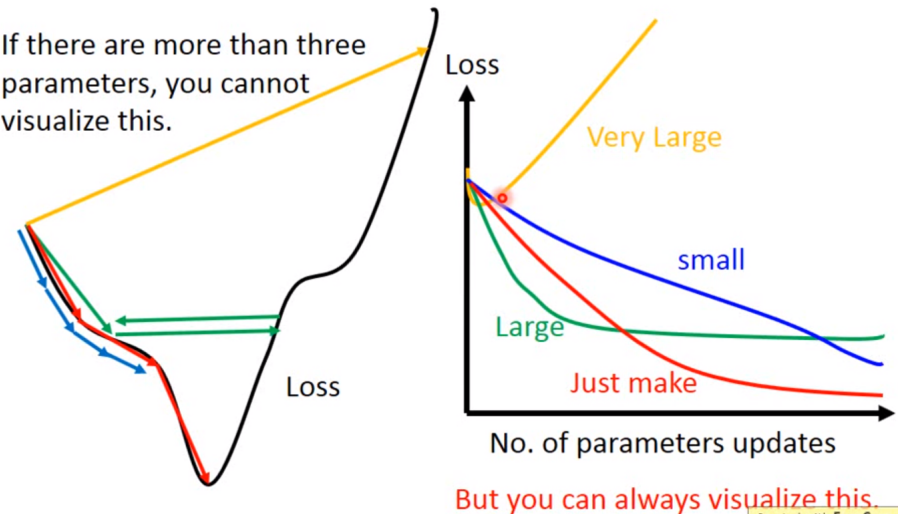
如果学习率选的不恰当会出现以上情况
因此有一些自动调学习率的方法。一般来说,随着迭代次数的增加,学习率应该越来越小,因为迭代次数增加后,得到的解应该比较靠近最优解,所以要缩小步长η,那么有什么公式吗?比如: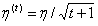 ,但是这样做后,所有参数更新时仍都采用同一个学习率,即学习率不能适应所有的参数更新。
,但是这样做后,所有参数更新时仍都采用同一个学习率,即学习率不能适应所有的参数更新。
解决方案是:给不同的参数不同的学习率
|
Adagrad法 |
假设N元函数f(x),针对一个自变量研究Adagrad梯度下降的迭代过程,
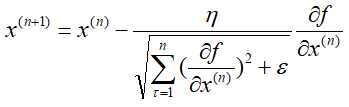
可以看出,Adagrad算法中有自适应调整梯度的意味(adaptive gradient),学习率需要除以一个东西,这个东西就是前n次迭代过程中偏导数的平方和再加一个常量最后开根号。
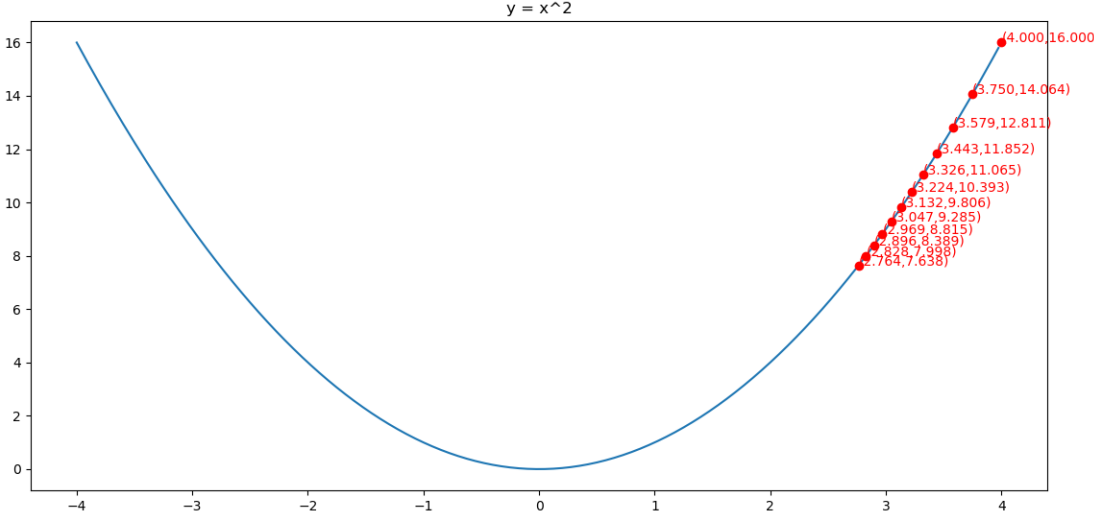
举例:使用Adagrad算法求y = x2的最小值点
导函数为g(x) = 2x
初始化x(0) = 4,学习率η=0.25,ε=0.1
第①次迭代:
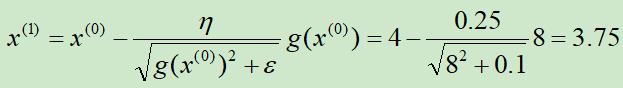
第②次迭代:
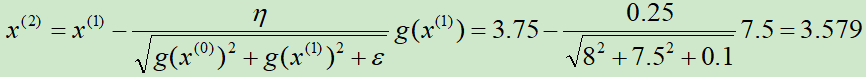
第③次迭代:
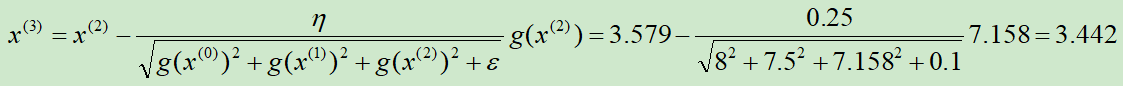
求解的过程如下图所示
对应代码为:
缺点:由于分母是累加梯度的平方,到后面累加的比较大时,会导致梯度更新缓慢
|
RMSprop法 |
AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。为了解决这一问题,RMSprop算法对Adagrad算法做了一点小小的修改,RMSprop使用指数衰减只保留过去给定窗口大小的梯度,使其能够在找到凸碗状结构后快速收敛。
假设N元函数f(x),针对一个自变量研究RMSprop梯度下降的迭代过程,

可以看出分母不再是一味的增加,它会重点考虑距离他较近的梯度(指数衰减的效果),也就不会出现Adagrad到后期收敛缓慢的问题
举例:使用RMSprop算法求y = x2的最小值点
导函数为h(x) = 2x
初始化g(0) = 1,x(0) = 4,ρ=0.9,η=0.01,ε=10-10
第①次迭代:
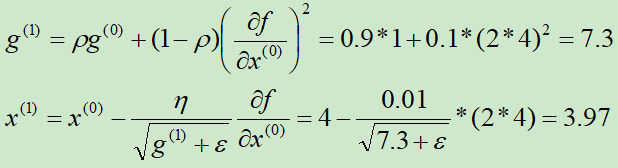
第②次迭代:
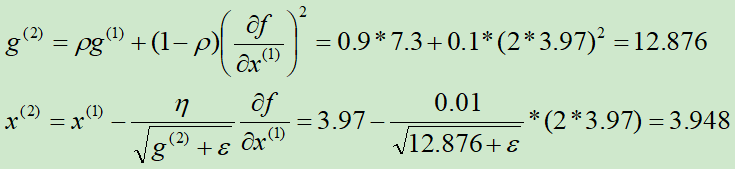
求解的过程如下图所示
对应代码为:
|
Momentum法 |
Momentum是动量的意思,想象一下,一个小车从高坡上冲下来,他不会停在最低点,因为他还有一个动量,还会向前冲,甚至可以冲过一些小的山丘,如果面对的是较大的坡,他可能爬不上去,最终又会倒车回来,折叠几次,停在谷底。

如果使用的是没有动量的梯度下降法,则可能会停到第一个次优解
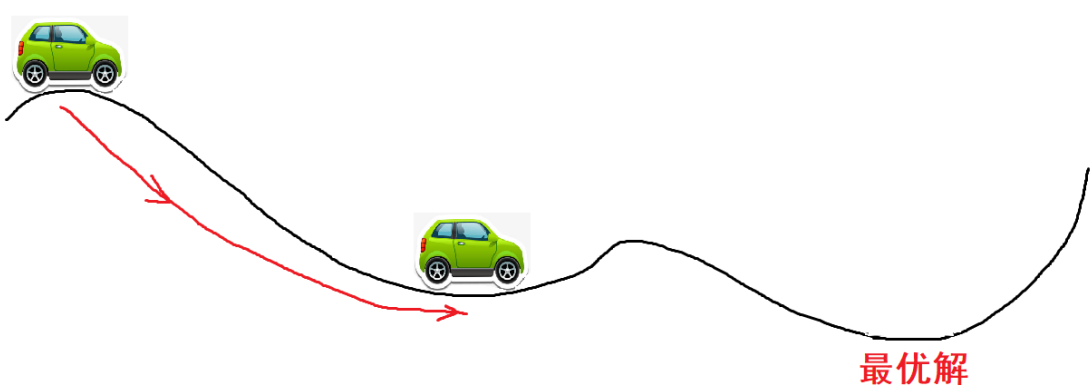
最直观的理解就是,若当前的梯度方向与累积的历史梯度方向一致,则当前的梯度会被加强,从而这一步下降的幅度更大。若当前的梯度方向与累积的梯度方向不一致,则会减弱当前下降的梯度幅度。
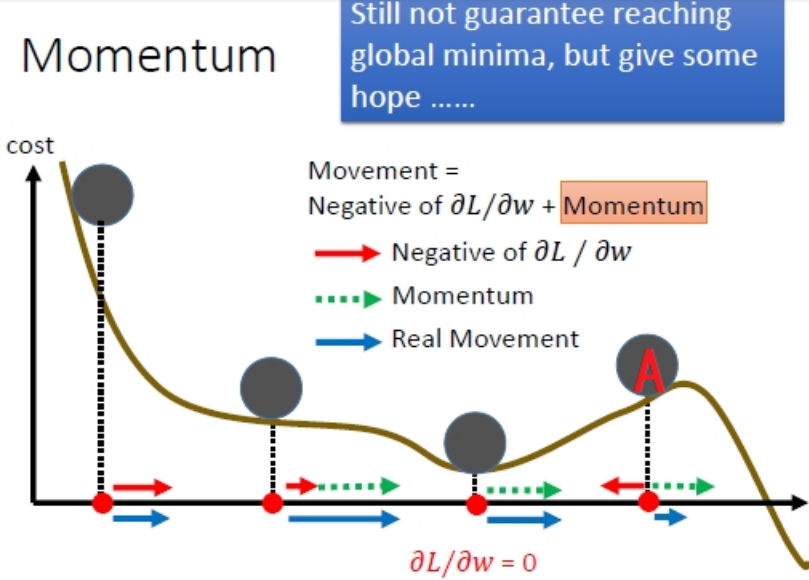
从这幅图可以看出来,当小球到达A点处,负梯度方向的红箭头朝着x轴负向,但是动量方向(绿箭头)朝着x轴的正向并且长度大于红箭头,因此小球在A处还会朝着x轴正向移动。
下面正式介绍Momentum法
假设N元函数f(x),针对一个自变量研究Momentum梯度下降的迭代过程,
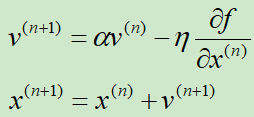
v表示动量,初始v=0
α是一个接近于1的数,一般设置为0.9,也就是把之前的动量缩减到0.9倍
η是学习率
下面通过一个例子演示一下,求y = 2*x^4-x^3-x^2的极小值点
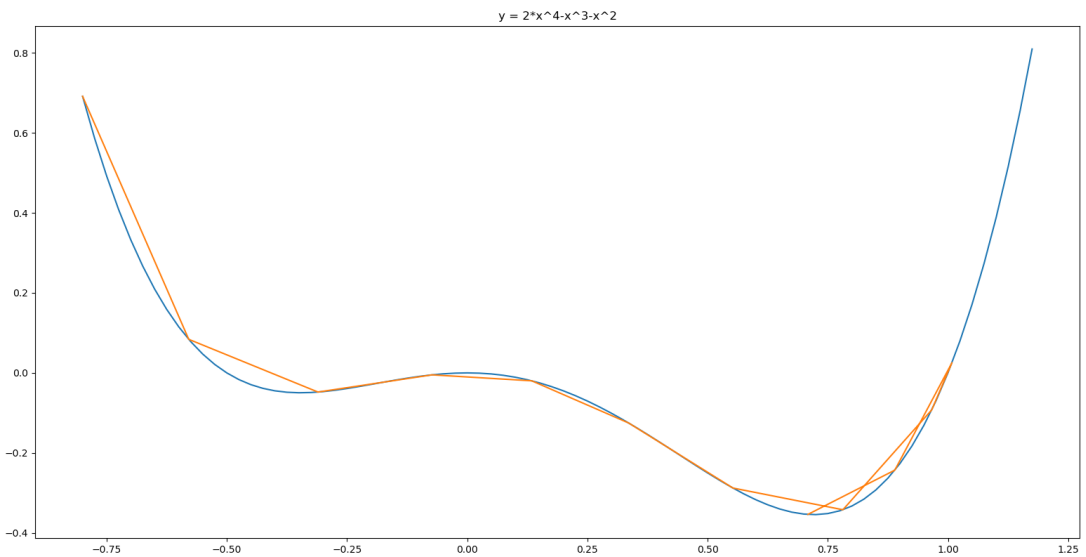
可以看出从-0.8开始迭代,依靠动量成功越过第一个次优解,发现无法越过最优解,折叠回来,最终收敛到最优解。对应代码如下
|
Adam法 |
Adam实际上是把momentum和RMSprop结合起来的一种算法
假设N元函数f(x),针对一个自变量研究Adam梯度下降的迭代过程,
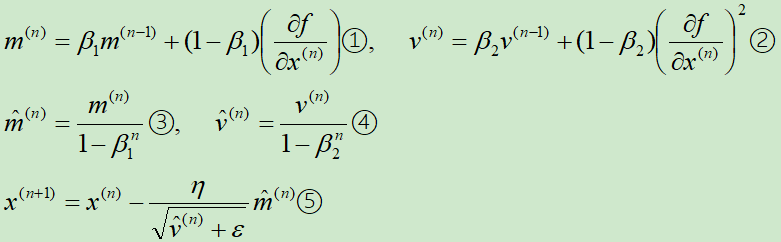
下面依次解释这五个式子:
在①式中,注意m(n)是反向的动量与梯度的和(而在Momentum中是正向动量与负梯度的和,因此⑤式对应的是减号)
在②式中,借鉴的是RMSprop的指数衰减
③和④式目的是纠正偏差
⑤式进行梯度更新
举例:使用Adagrad算法求y = x2的最小值点
导函数为h(x) = 2x
初始化x(0) = 4,m(0) = 0,v(0) = 0,β1=0.9,β2=0.999,ε=10-8,η = 0.001
第①次迭代:
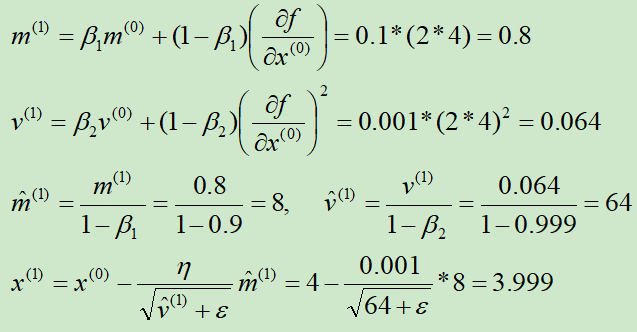
第②次迭代:
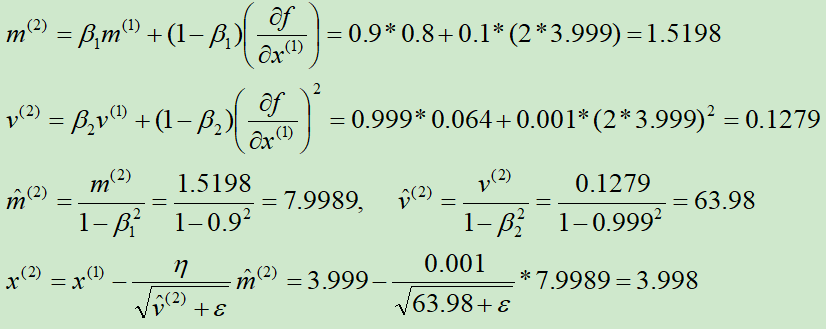
求解的过程如下图所示
对应代码为:
|
参考资料 |
李宏毅——一天搞懂深度学习
深度学习中优化方法——momentum、Nesterov Momentum、AdaGrad、Adadelta、RMSprop、Adam
https://blog.csdn.net/u012328159/article/details/80311892
《图解深度学习与神经网络:从张量到TensorFlow实现》_张平
深度学习面试题03:改进版梯度下降法Adagrad、RMSprop、Momentum、Adam的更多相关文章
- ubuntu之路——day8.1 深度学习优化算法之mini-batch梯度下降法
所谓Mini-batch梯度下降法就是划分训练集和测试集为等分的数个子集,比如原来有500W个样本,将其划分为5000个baby batch,每个子集中有1000个样本,然后每次对一个mini-bat ...
- 深度学习面试题29:GoogLeNet(Inception V3)
目录 使用非对称卷积分解大filters 重新设计pooling层 辅助构造器 使用标签平滑 参考资料 在<深度学习面试题20:GoogLeNet(Inception V1)>和<深 ...
- 深度学习面试题27:非对称卷积(Asymmetric Convolutions)
目录 产生背景 举例 参考资料 产生背景 之前在深度学习面试题16:小卷积核级联卷积VS大卷积核卷积中介绍过小卷积核的三个优势: ①整合了三个非线性激活层,代替单一非线性激活层,增加了判别能力. ②减 ...
- 深度学习面试题13:AlexNet(1000类图像分类)
目录 网络结构 两大创新点 参考资料 第一个典型的CNN是LeNet5网络结构,但是第一个引起大家注意的网络却是AlexNet,Alex Krizhevsky其实是Hinton的学生,这个团队领导者是 ...
- [源码解析] 深度学习流水线并行GPipe (2) ----- 梯度累积
[源码解析] 深度学习流水线并行GPipe (2) ----- 梯度累积 目录 [源码解析] 深度学习流水线并行GPipe (2) ----- 梯度累积 0x00 摘要 0x01 概述 1.1 前文回 ...
- 深度学习笔记之【随机梯度下降(SGD)】
随机梯度下降 几乎所有的深度学习算法都用到了一个非常重要的算法:随机梯度下降(stochastic gradient descent,SGD) 随机梯度下降是梯度下降算法的一个扩展 机器学习中一个反复 ...
- 深度学习面试题21:批量归一化(Batch Normalization,BN)
目录 BN的由来 BN的作用 BN的操作阶段 BN的操作流程 BN可以防止梯度消失吗 为什么归一化后还要放缩和平移 BN在GoogLeNet中的应用 参考资料 BN的由来 BN是由Google于201 ...
- 深度学习面试题20:GoogLeNet(Inception V1)
目录 简介 网络结构 对应代码 网络说明 参考资料 简介 2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名.VGG获得了第二 ...
- 深度学习面试题05:激活函数sigmod、tanh、ReLU、LeakyRelu、Relu6
目录 为什么要用激活函数 sigmod tanh ReLU LeakyReLU ReLU6 参考资料 为什么要用激活函数 在神经网络中,如果不对上一层结点的输出做非线性转换的话,再深的网络也是线性模型 ...
随机推荐
- git如何删除已经提交的文件夹
在上传项目到github时,忘记忽略了某个文件夹.idea,就直接push上去了, 最后意识到了此问题,决定删除掉远程仓库中的.idea文件夹 删除前: 删除后: 在github上只能删除仓库,却无法 ...
- 软件测试过程中如何区分什么是功能bug,什么是需求bug,什么是设计bug?
问题描述: 测试过程中如何区分什么是功能bug,什么是需求bug,什么是设计bug? 精彩答案: 会员 土土的豆豆: 本期问题其实主要是针对不同方面或纬度上对于bug的一个归类和定位. 个人认为,从软 ...
- 学underscore在数组中查找指定元素
前言 在开发中,我们经常会遇到在数组中查找指定元素的需求,可能大家觉得这个需求过于简单,然而如何优雅的去实现一个 findIndex 和 findLastIndex.indexOf 和 lastInd ...
- bzoj 2480——扩展BSGS
题意 给定 $a,b$ 和模数 $p$,求整数 $x$ 满足 $a^x \equiv b(mod \ p)$,不保证 $a,p$ 互质. (好像是权限题,可见洛谷P4195 分析 之前讲过,可以通过 ...
- [React] Write a Custom React Effect Hook
Similar to writing a custom State Hook, we’ll write our own Effect Hook called useStarWarsQuote, whi ...
- Sublime 原版安装
sublime text3 安装方法 ① 官网下载安装 https://www.sublimetext.com/3 ② 更改hosts文件 具体方法如下: windows系统的hosts文件在C:\W ...
- 动手动脑-------找出指定文件夹下所有扩展名为.txt和.java的文件
思路:首先向获取文件,如果是文件的话,则判断它是否以".txt"或".java"结尾,如果是则输出它的路径.如果是文件夹的话,则需获取子文件,利用递归方法遍历子 ...
- Codeforces Round #609 (Div. 2) 【A,B,C】
题意:给一个n<=1e7,找两个合数a和b使得a-b的差为n. 构造a=3n,b=2n,必含有公因子n,只有当n是1的时候是特例. #include<bits/stdc++.h> u ...
- IDEA激活码(直到2020年6月)
K6IXATEF43-eyJsaWNlbnNlSWQiOiJLNklYQVRFRjQzIiwibGljZW5zZWVOYW1lIjoi5o6I5p2D5Luj55CG5ZWGOiBodHRwOi8va ...
- C# 模式匹配
最近在使用vs编码时,重构提示:模式匹配 Element view = bindable as Element; if (view == null) { return; } 运用模式匹配可以简写为: ...