MongoDB中4种日志的详细介绍
前言
任何一种数据库都有各种各样的日志,MongoDB也不例外。MongoDB中有4种日志,分别是系统日志、Journal日志、oplog主从日志、慢查询日志等。这些日志记录着MongoDB数据库不同方面的踪迹。下面分别介绍这几种日志。
系统日志
系统日志在MongoDB数据库中很重要,它记录着MongoDB启动和停止的操作,以及服务器在运行过程中发生的任何异常信息。
配置系统日志的方法比较简单,在启动mongod时指定logpath参数即可
|
1
|
mongod -logpath=/data/log/mongodb/serverlog.log -logappend |
系统日志会向logpath指定的文件持续追加。
Journal日志
journaling(日记) 日志功能则是 MongoDB 里面非常重要的一个功能 , 它保证了数据库服务器在意外断电 、 自然灾害等情况下数据的完整性。它通过预写式的redo日志为MongoDB增加了额外的可靠性保障。开启该功能时,MongoDB会在进行写入时建立一条Journal日志,其中包含了此次写入操作具体更改的磁盘地址和字节。因此一旦服务器突然停机,可在启动时对日记进行重放,从而重新执行那些停机前没能够刷新到磁盘的写入操作。
MongoDB配置WiredTiger引擎使用内存缓冲区来保存journal记录,WiredTiger根据以下间隔或条件将缓冲的日志记录同步到磁盘
- 从MongoDB 3.2版本开始每隔50ms将缓冲的journal数据同步到磁盘
- 如果写入操作设置了j:true,则WiredTiger强制同步日志文件
- 由于MongoDB使用的journal文件大小限制为100MB,因此WiredTiger大约每100MB数据创建一个新的日志文件。当WiredTiger创建新的journal文件时,WiredTiger会同步以前journal文件
MongoDB达到上面的提交,便会将更新操作写入日志。这意味着MongoDB会批量地提交更改,即每次写入不会立即刷新到磁盘。不过在默认设置下,系统发生崩溃时,不可能丢失超过50ms的写入数据。
数据文件默认每60秒刷新到磁盘一次,因此Journal文件只需记录约60s的写入数据。日志系统为此预先分配了若干个空文件,这些文件存放在/data/db/journal目录中,目录名为_j.0、_j.1等
长时间运行MongoDB后,日志目录中会出现类似_j.6217、_j.6218的文件,这些是当前的日志文件,文件中的数值会随着MongoDB运行时间的增长而增大。数据库正常关闭后,日记文件会被清除(因为正常关闭后就不在需要这些文件了).
向mongodb中写入数据是先写入内存,然后每隔60s在刷盘,同样写入journal,也是先写入对应的buffer,然后每隔50ms在刷盘到磁盘的journal文件
使用WiredTiger,即使没有journal功能,MongoDB也可以从最后一个检查点(checkpoint,可以想成镜像)恢复;但是,要恢复在上一个检查点之后所做的更改,还是需要使用Journal
如发生系统崩溃或使用kill -9命令强制终止数据库的运行,mongod会在启动时重放journal文件,同时会显示出大量的校验信息。
上面说的都是针对WiredTiger引擎,对于MMAPv1引擎来说有一点不一样,首先它是每100ms进行刷盘,其次它是通过private view写入journal文件,通过shared view写入数据文件。这里就不过多讲解了,因为MongoDB 4.0已经不推荐使用这个存储引擎了。
从MongoDB 3.2版本开始WiredTiger是MongoDB推荐的默认存储引擎
需要注意的是如果客户端的写入速度超过了日记的刷新速度,mongod则会限制写入操作,直到日记完成磁盘的写入。这是mongod会限制写入的唯一情况。
固定集合(Capped Collection)
在讲下面两种日志之前先来认识下capped collection。
MongoDB中的普通集合是动态创建的,而且可以自动增长以容纳更多的数据。MongoDB中还有另一种不同类型的集合,叫做固定集合。固定集合需要事先创建好,而且它的大小是固定的。固定集合的行为类型与循环队列一样。如果没有空间了,最老的文档会被删除以释放空间,新插入的文档会占据这块空间。
创建固定集合:
|
1
|
db.createCollection("collectionName",{"capped":true, "size":100000, "max":100}) |
创建了一个大小为100000字节的固定大小集合,文档数量为100.不管先到达哪个限制,之后插入的新文档就会把最老的文档挤出集合:固定集合的文档数量不能超过文档数量限制,也不能超过大小限制。
固定集合创建之后就不能改变,无法将固定集合转换为非固定集合,但是可以将常规集合转换为固定集合。
|
1
|
db.runCommand({"convertToCapped": "test", "size" : 10000}); |
固定集合可以进行一种特殊的排序,称为自然排序(natural sort),自然排序返回结果集中文档的顺序就是文档在磁盘的顺序。自然顺序就是文档的插入顺序,因此自然排序得到的文档是从旧到新排列的。当然也可以按照从新到旧:
|
1
|
db.my_capped_collection.find().sort({"$natural": -1}); |
oplog主从日志
Replica Sets复制集用于在多台服务器之间备份数据。MongoDB的复制功能是使用操作日志oplog实现的,操作日志包含了主节点的每一次写操作。oplog是主节点的local数据库中的一个固定集合。备份节点通过查询这个集合就可以知道需要进行复制的操作。
一个mongod实例中的所有数据库都使用同一个oplog,也就是所有数据库的操作日志(插入,删除,修改)都会记录到oplog中
每个备份节点都维护着自己的oplog,记录着每一次从主节点复制数据的操作。这样,每个成员都可以作为同步源给其他成员使用。
如图所示,备份节点从当前使用的同步源中获取需要执行的操作,然后在自己的数据集上执行这些操作,最后再将这些操作写入自己的oplog,如果遇到某个操作失败的情况(只有当同步源的数据损坏或者数据与主节点不一致时才可能发生),那么备份节点就会停止从当前的同步源复制数据。
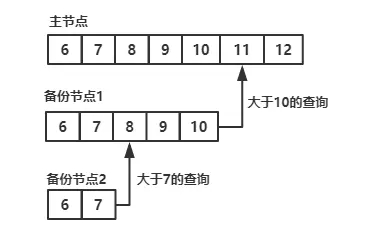
oplog中按顺序保存着所有执行过的写操作,replica sets中每个成员都维护者一份自己的oplog,每个成员的oplog都应该跟主节点的oplog完全一致(可能会有一些延迟)
如果某个备份节点由于某些原因挂了,但它重新启动后,就会自动从oplog中最后一个操作开始进行同步。由于复制操作的过程是想复制数据在写入oplog,所以备份节点可能会在已经同步过的数据上再次执行复制操作。MongoDB在设计之初就考虑到了这种情况:将oplog中的同一个操作执行多次,与只执行一次的效果是一样的。
由于oplog大小是固定的,它只能保持特定数量的操作日志。通常,oplog使用空间的增长速度与系统处理写请求的速率几乎相同:如果主节点上每分钟处理了1KB的写入请求,那么oplog很可能也会在一分钟内写入1KB条操作日志。
但是,有一些例外:如果单次请求能够影响到多个文档(比如删除多个文档或者多文档更新),oplog中就会出现多条操作日志。如果单个操作会影响多个文档,那么每个受影响的文档都会对应oplog的一条日志。因此,如果执行db.student.remove()删除了10w个文档,那么oplog中也就会有10w条操作日志,每个日志对应一个被删除的文档。如果执行大量的批量操作,oplog很快就会被填满。
慢查询日志
MongoDB中使用系统分析器(system profiler)来查找耗时过长的操作。系统分析器记录固定集合system.profile中的操作,并提供大量有关耗时过长的操作信息,但相应的mongod的整体性能也会有所下降。因此我们一般定期打开分析器来获取信息。
默认情况下,系统分析器处于关闭状态,不会进行任何记录。可以在shell中运行db.setProfilingLevel()开启分析器
|
1
|
db.setProfilingLevel(level,<slowms>) 0=off 1=slow 2=all |
第一个参数是指定级别,不同的级别代表不同的意义,0表示关闭,1表示默认记录耗时大于100毫秒的操作,2表示记录所有操作。第二个参数则是自定义“耗时过长"标准,比如记录所有耗时操作500ms的操作
|
1
|
db.setProfilingLevel(1,500); |
如果开启了分析器而system.profile集合并不存在,MongoDB会为其建立一个大小为若干MB的固定集合(capped collection)。如希望分析器运行更长时间,可能需要更大的空间记录更多的操作。此时可以关闭分析器,删除并重新建立一个新的名为system.profile的固定集合,并令其容量符合要求。然后在数据库上重新启用分析器。
可以通过db.system.profile.stats()查看集合的最大容量.
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对脚本之家的支持。
转载自:https://www.jb51.net/article/167189.htm
MongoDB中4种日志的详细介绍的更多相关文章
- QT中PRO文件写法的详细介绍
学习Qt时,发现有些知识看了不经常用就忘了,以下是书本上写的一些关于qmake的相关知识,自己看后,打算把一些经常用到的记下来,整理整理. Qt程序一般使用Qt提供的qmake工具来编译. qmake ...
- 转载:Java中的字符串常量池详细介绍
引用自:http://blog.csdn.net/langhong8/article/details/50938041 这篇文章主要介绍了Java中的字符串常量池详细介绍,JVM为了减少字符串对象的重 ...
- 日志模块详细介绍 hashlib模块 动态加盐
目录 一:hashlib模块 二:logging 一:hashlib模块 加密: 将明文数据通过一系列算法变成密文数据(目的就是为了数据的安全) 能够做文件一系列校验 python的hashlib提供 ...
- (转载)SQL语句中Group by语句的详细介绍
转自:http://blog.163.com/yuer_d/blog/static/76761152201010203719835 SQL语句中Group by语句的详细介绍 ...
- java中的compareto方法的详细介绍
java中的compareto方法的详细介绍 Java Comparator接口实例讲解(抽象方法.常用静态/默认方法) 一.java中的compareto方法 1.返回参与比较的前后两个字符串的as ...
- MongoDB中聚合工具Aggregate等的介绍与使用
Aggregate是MongoDB提供的众多工具中的比较重要的一个,类似于SQL语句中的GROUP BY.聚合工具可以让开发人员直接使用MongoDB原生的命令操作数据库中的数据,并且按照要求进行聚合 ...
- Java中几种日志方案
.本文记录Java中几种常用的日志解决方案 0x01 Log4j .这应该是一个比较老牌的日志方案了,配置也比较简单,步骤如下 1)添加对应依赖,比如 Gradle 中 dependencies { ...
- Linux中三种SCSI target的介绍之SCST
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/scaleqiao/article/deta ...
- Xcode中c++&Object-C混编,详细介绍如何在cocos2dx中访问object函数以及Apple Api
转自:http://www.himigame.com/iphone-cocos2dx/743.html Cocos2dx系列博文的上一篇详细介绍了如何在Xcode中利用jni调用Android的Jav ...
随机推荐
- C语言输入带空格的字符串
参考:https://blog.csdn.net/vincemar/article/details/78750435 因为: scanf("%s",str); 遇到空格就停止接收后 ...
- SQL分类之DCL:管理用户、授权
DCL:管理用户.授权 SQL分类: DDL:操作数据库和表 DML:增删改表中的数据 DQL:查询表中的数据 DCL:管理用户.授权 DBA:数据库管理员 DCL:管理用户.授权 1.管理用户 1. ...
- SQL分类之DDL:操作数据库表
DDL:操作数据库表 1.操作数据库:CRUD 1.C(Create):创建 创建数据库: create database 数据库名称 创建数据库,判断不存在,再创建: create database ...
- SQL系列(十四)—— 视图(view)
说到视图view,大家应该都很熟悉.如几何学中用三视图来描述集合物体的外观构成,三视图中反应出物体的面貌.这里我们讨论数据库中视图的概念: 什么是视图 为什么会有会用视图 怎样使用视图 视图与表的异同 ...
- golang 学习笔记 -- 类型
int 和 uint的实际宽度会根据计算架构不同而不同,386下4个字节, amd64下8个字节 byte可看做uint8的别名类型 rune可看做int32的别名类型,专用于存储Unicode编码的 ...
- gitblit服务器:用户、团队、权限管理
在日常开发工作中,我们通常使用版本控制软件管理团队的源代码,常用的SVN.Git.与SVN相比,Git有分支的概念,可以从主分支创建开发分支,在开发分支测试没有问题之后,再合并到主分支上去,从而避免了 ...
- kvm第一章--概念
- 【转载】C#通过InsertAt方法在DataTable特定位置插入一条数据
在C#中的Datatable数据变量的操作过程中,可以通过DataTable变量的Rows属性的InsertAt方法往DataTable的指定位置行数位置插入一个新行数据,即往DataTable表格指 ...
- 43、css实现镂空半圆环
<style> .circle { position: relative; box-sizing: border-box; } .big { width: 140px; height: 1 ...
- 聊聊webpack 4
前言 hello,小伙伴们,本篇仓库出至于我的GitHub仓库 web-study ,如果你觉得对你有帮助的话欢迎star,你们的点赞是我持续更新的动力 web-study webpack 打包工具 ...