Solr7.x学习(3)-创建core并使用分词器
1、创建core文件夹
ck /usr/local/solr-7.7.2/server/solr
mkdir first_core
cp -r configsets/_default/* first_core/
chown -R solr:solr first_core
2、添加core

3、配置中文IK分词器
参考:https://github.com/magese/ik-analyzer-solr
1)将ik-analyzer-7.7.1.jar复制到solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib目录下
2)将https://github.com/magese/ik-analyzer-solr/tree/v7.7.1/src/main/resources目录下的dynamicdic.txt、ext.dic、ik.conf、IKAnalyzer.cfg.xml、stopword.dic文件复制到solr-7.7.2/server/solr-webapp/webapp/WEB-INF/classes目录下。
3)修改managed-schema,添加配置:
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
4)重启solr服务,测试IK分词器

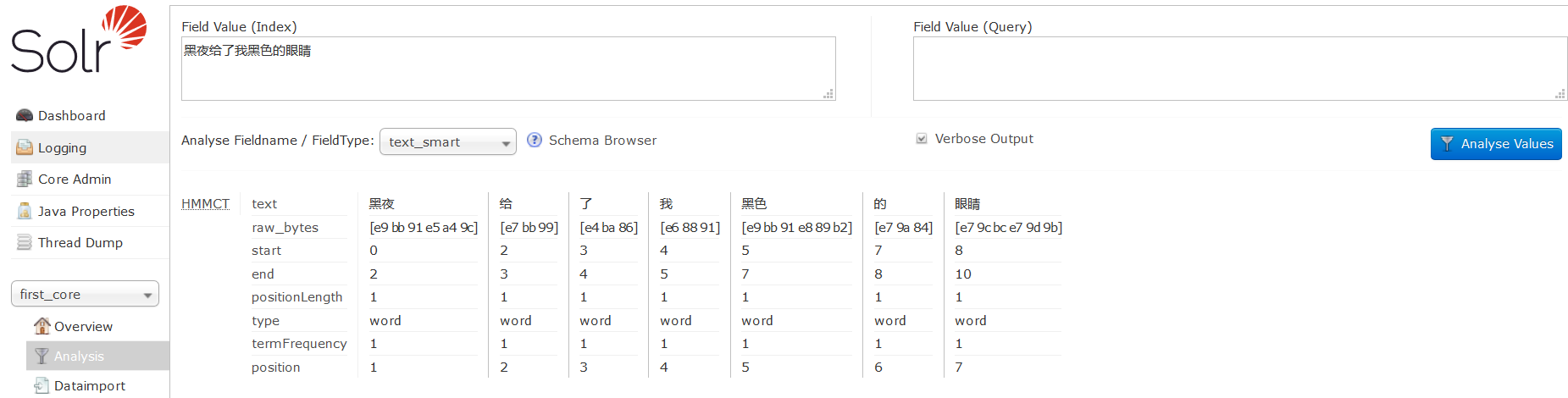
4、使用solr自带的smart中文分词器
1)复制solr-7.7.2\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-7.7.2.jar到solr-7.7.2/server/solr-webapp/webapp/WEB-INF/lib目录下
2)修改managed-schema文件,增加配置
<fieldType name="text_smart" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
3)重启solr,测试smart分词器
Solr7.x学习(3)-创建core并使用分词器的更多相关文章
- solr学习篇(二) solr 分词器篇
关于solr7.4搭建与配置可以参考 solr7.4 安装配置篇 在这里我们探讨一下分词的配置 目录 关于分词 配置分词 验证成功 1.关于分词 1.分词是指将一个中文词语拆成若干个词,提供搜索引擎 ...
- Solr7.1---数据库导入并建立中文分词器
这里只是告诉你如何导入,生产环境不要这样部署你的solr服务. 首先修改solrConfig.xml文件 备份_default文件夹 修改solrconfig.xml 加入如下内容 官方示例:< ...
- 学习笔记(三)--Lucene分词器详解
Lucene-分词器API org.apache.lucene.analysi.Analyzer 分析器,分词器组件的核心API,它的职责:构建真正对文本进行分词处理的TokenStream(分词处理 ...
- ElasticSearch7.3 学习之倒排索引揭秘及初识分词器(Analyzer)
一.倒排索引 1. 构建倒排索引 例如说有下面两个句子doc1,doc2 doc1:I really liked my small dogs, and I think my mom also like ...
- lucene全文搜索之二:创建索引器(创建IKAnalyzer分词器和索引目录管理)基于lucene5.5.3
前言: lucene全文搜索之一中讲解了lucene开发搜索服务的基本结构,本章将会讲解如何创建索引器.管理索引目录和中文分词器的使用. 包括标准分词器,IKAnalyzer分词器以及两种索引目录的创 ...
- ElasticSearch7.3 学习之定制分词器(Analyzer)
1.默认的分词器 关于分词器,前面的博客已经有介绍了,链接:ElasticSearch7.3 学习之倒排索引揭秘及初识分词器(Analyzer).这里就只介绍默认的分词器standard analyz ...
- 从零开始学习 asp.net core 2.1 web api 后端api基础框架(二)-创建项目
原文:从零开始学习 asp.net core 2.1 web api 后端api基础框架(二)-创建项目 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.ne ...
- 从零开始学习 asp.net core 2.1 web api 后端api基础框架(三)-创建Data Transfer Object
原文:从零开始学习 asp.net core 2.1 web api 后端api基础框架(三)-创建Data Transfer Object 版权声明:本文为博主原创文章,未经博主允许不得转载. ht ...
- 从零开始学习 asp.net core 2.1 web api 后端api基础框架(四)-创建Controller
原文:从零开始学习 asp.net core 2.1 web api 后端api基础框架(四)-创建Controller 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog ...
随机推荐
- 2019-11-29-WPF-客户端开发需要知道的触摸失效问题
原文:2019-11-29-WPF-客户端开发需要知道的触摸失效问题 title author date CreateTime categories WPF 客户端开发需要知道的触摸失效问题 lind ...
- net core 记录自定义端口多个方式
1.直接修改 . 2.代码定义 public class Program { public static void Main(string[] args) { CreateWebHostBuilder ...
- layui的使用说明
一.定义 layui,是一款采用自身模块规范编写的前端 UI 框架,遵循原生 HTML/CSS/JS 的书写与组织形式,跟其他UI框架比较(比如bootstrap.easyui.findui.topu ...
- Python 绘图与可视化 matplotlib text 与transform
Text 为plots添加文本或者公式,反正就是添加文本了 参考链接:https://matplotlib.org/api/_as_gen/matplotlib.pyplot.text.html#ma ...
- Java自学-I/O 中文问题
Java中的编码中文问题 步骤 1 : 编码概念 计算机存放数据只能存放数字,所有的字符都会被转换为不同的数字. 就像一个棋盘一样,不同的字,处于不同的位置,而不同的位置,有不同的数字编号. 有的棋盘 ...
- 强化Linux 服务器的7个步骤
这篇入门文章将向你介绍基本的 Linux 服务器安全知识.虽然主要针对 Debian/Ubuntu,但是你可以将此处介绍的所有内容应用于其他 Linux 发行版.我也鼓励你研究这份材料,并在适用的情况 ...
- innodb和myisam对比
MyISAM特点 1)不支持行锁(MyISAM只有表锁),读取时对需要读到的所有表加锁,写入时则对表加排他锁: 2)不支持事务 3)不支持外键 4)不支持崩溃后的安全恢复 5)在表有读取查询的同时,支 ...
- 2 Linux磁盘管理
Linux磁盘管理:磁盘管理好坏直接关系到整个系统的性能问题常用三个命令:df.du.fdiskdf:列出文件系统的整体磁盘使用量 df 参数 目录或文件名 -a:理出所有文件系统,包括系统特有的 / ...
- dos2unix的使用
由于在DOS(windows系统)下,文本文件的换行符为CRLF,而在Linux下换行符为LF,使用git进行代码管理时,git会自动进行CRLF和LF之间的转换,这个我们不用操心.而有时候,我们需要 ...
- Python字符编码和转码
一:Python2 python2默认编码格式是ascii码,解释器解释代码时会将代码以及代码中的字符串等转换成ascii码再执行.这样会导致字符串输出或传输时,与当前环境编码格式不同的话会显示乱码. ...