大数据之路【第十篇】:kafka消息系统
一、简介
1、简介
简 介
• Kafka是Linkedin于2010年12月份开源的消息系统
• 一种分布式的、基于发布/订阅的消息系统
2、特点
– 消息持久化:通过O(1)的磁盘数据结构提供数据的持久化
– 高吞吐量:每秒百万级的消息读写
– 分布式:扩展能力强
– 多客户端支持:java、php、python、c++ ……
– 实时性:生产者生产的message立即被消费者可见
3、基本组件
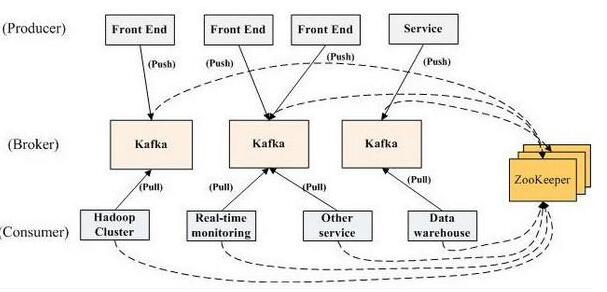
• Broker:每一台机器叫一个Broker
• Producer:日志消息生产者,用来写数据
• Consumer:消息的消费者,用来读数据
• Topic:不同消费者去指定的Topic中读,不同的生产者往不同的Topic中写
• Partition:新版本才支持Partition,在Topic基础上做了进一步区分分层
好处二:动态导入模块(基于反射当前模块成员)
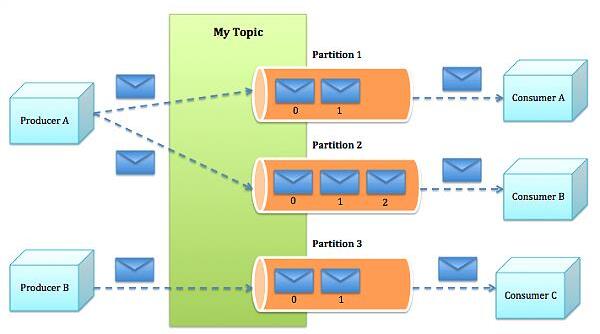
注意:
• Kafka内部是分布式的、一个Kafka集群通常包括多个Broker
• 负载均衡:将Topic分成多个分区,每个Broker存储一个或多个Partition
• 多个Producer和Consumer同时生产和消费消息
4、Topic
• 一个Topic是一个用于发布消息的分类或feed名,kafka集群使用分区的日志,每个分区都是有顺序且不变的消息序列。
• commit的log可以不断追加。消息在每个分区中都分配了一个叫offset的id序列来唯一识别分区中的消息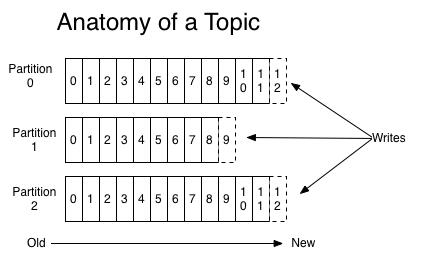
• 举例:若创建topic1和topic2两个topic,且分别有13个和19个分区,则整个集群上会相应会生成共32个文件夹
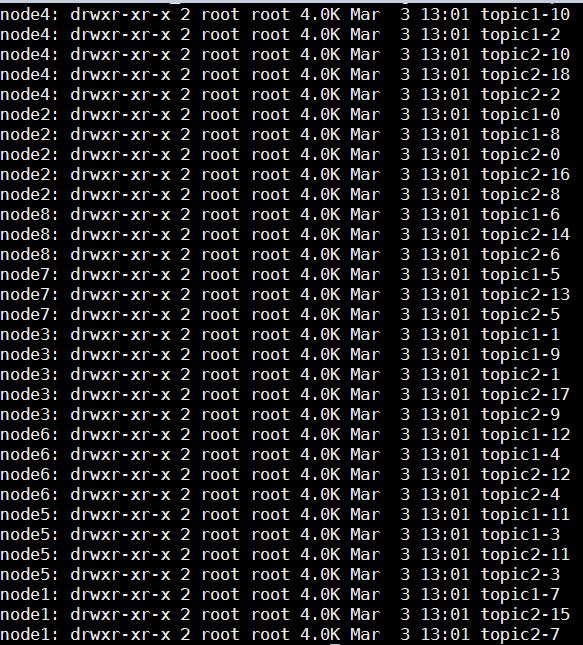
注意:
• 无论发布的消息是否被消费,kafka都会持久化一定时间(可配置)。
• 在每个消费者都持久化这个offset在日志中。通常消费者读消息时会使offset值线性的增长,但实际上其位置是由消费者控制,它可以按任意顺序来消费消息。
比如复位到老的offset来重新处理。
• 每个分区代表一个并行单元。
5、Message
• message(消息)是通信的基本单位,每个producer可以向一个topic(主题)
发布一些消息。如果consumer订阅了这个主题,那么新发布的消息就会广播给
这些consumer。
• message format:
– message length : 4 bytes (value: 1+4+n)
– "magic" value : 1 byte
– crc : 4 bytes
– payload : n bytes
6、Producer
• 生产者可以发布数据到它指定的topic中,并可以指定在topic里哪些消息分配到哪些分区(比如简单的轮流分发各个分区或通过指定分区语义分配key到对应分
区)
• 生产者直接把消息发送给对应分区的broker,而不需要任何路由层。
• 批处理发送,当message积累到一定数量或等待一定时间后进行发送。
7、Consumer
• 一种更抽象的消费方式:消费组(consumer group)
• 该方式包含了传统的queue和发布订阅方式
– 首先消费者标记自己一个消费组名。消息将投递到每个消费组中的某一个消费者实例上。
– 如果所有的消费者实例都有相同的消费组,这样就像传统的queue方式。
– 如果所有的消费者实例都有不同的消费组,这样就像传统的发布订阅方式。
– 消费组就好比是个逻辑的订阅者,每个订阅者由许多消费者实例构成(用于扩展或容错)。
• 相对于传统的消息系统,kafka拥有更强壮的顺序保证。
• 由于topic采用了分区,可在多Consumer进程操作时保证顺序性和负载均衡。
大数据之路【第十篇】:kafka消息系统的更多相关文章
- Hadoop生态圈-大数据生态体系快速入门篇
Hadoop生态圈-大数据生态体系快速入门篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.大数据概念 1>.什么是大数据 大数据(big data):是指无法在一定时间 ...
- CentOS6安装各种大数据软件 第五章:Kafka集群的配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 为什么会有kafka消息系统?小问题藏着大细节!
前言:老刘今天写这篇文章首先想对一些复制粘贴的博客表达不满:其次是想用通俗易懂的话解释消息系统:最后欢迎各位英雄好汉.女中豪杰前来battle. 1. 为什么有消息系统? 1.1 背景 今天复习kaf ...
- 大数据笔记(三十二)——SparkStreaming集成Kafka与Flume
三.集成:数据源 1.Apache Kafka:一种高吞吐量的分布式发布订阅消息系统 (1) (*)消息的类型 Topic:主题(相当于:广播) Queue:队列(相当于:点对点) (*)常见的消息系 ...
- 胖子哥的大数据之路(6)- NoSQL生态圈全景介绍
引言: NoSQL高级培训课程的基础理论篇的部分课件,是从一本英文原著中做的摘选,中文部分参考自互联网.给大家分享. 正文: The NoSQL Ecosystem 目录 The NoSQL Eco ...
- C#码农的大数据之路 - 使用C#编写MR作业
系列目录 写在前面 从Hadoop出现至今,大数据几乎就是Java平台专属一般.虽然Hadoop或Spark也提供了接口可以与其他语言一起使用,但作为基于JVM运行的框架,Java系语言有着天生优势. ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 大数据基础知识问答----hadoop篇
handoop相关知识点 1.Hadoop是什么? Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速 ...
- 大数据竞赛平台——Kaggle 入门篇
这篇文章适合那些刚接触Kaggle.想尽快熟悉Kaggle并且独立完成一个竞赛项目的网友,对于已经在Kaggle上参赛过的网友来说,大可不必耗费时间阅读本文.本文分为两部分介绍Kaggle,第一部分简 ...
随机推荐
- isopod dsl 框架管理kubernetes 配置
isopod 是一个包含了丰富能力的dsl 框架我们可以不用编写yaml 文件来进行k8s 管理 说明 语法类似python,目前移植内置了一些不错的功能kube 方法 vault 集成,helm 集 ...
- VMware Tools安装后设置自动挂载解决共享文件夹无法显示的问题
一. 确保成功安装了VMware Tools 二. 使用如下命令 1.apt-get install open-vm-tools 2.vmhgfs-fuse .host:/ /mnt/hgfs ...
- luoguP3964 [TJOI2013]松鼠聚会
链接 luogu 思路 切比雪夫距离有max,不好优化. 但是我们能转化成曼哈顿距离,只需要 \((x,y)变成(\frac{x+y}{2},\frac{x-y}{2})\) 相反的曼哈顿距离转切比雪 ...
- 一起学Makefile(二)
Makefile基本概念示例 新建一个Code文件夹来测试一个简单的makefile 目录结构如下: 源码如下: makefile依赖: 一般在编写makefile之前都需要先分析清楚整个工程各个模块 ...
- shell 查找字符串中字符出现的位置
#!/bin/bash a="The cat sat on the mat" test="cat" awk -v a="$a" -v b=& ...
- 第10组 Alpha冲刺(1/4)
队名:凹凸曼 组长博客 作业博客 组员实践情况 童景霖 过去两天完成了哪些任务 文字/口头描述 学习Android studio和Java,基本了解APP前端的制作 完善项目APP原型 展示GitHu ...
- AngularJS实现地址栏取值
有时候我们由如下需求 1.从a.html跳转到b.html 2.从a跳转时携带参数和值. 3.从b.html中取出传过来的参数值 在AngularJS的操作如下 在a.html中添加 <a hr ...
- shell 命令行参数(基本)
命令行参数 $0 表示程序名.$1 至 \$9则是位置参数.$# 表示参数的个数.$* 将所有参数当做一个整体来引用$@ 把每个参数作为一个字符串返回,可以使用for循环来遍历$? 最近一个执行的命令 ...
- js svg转图片格式
1.情景展示 闲来无事的时候,发现chrome扩展程序里面有图像,本想下载下来,却发现文件格式是svg格式,如何将svg文件改成图片格式? chrome-extension://jlgkpaici ...
- FZU Monthly-201909 获奖名单
FZU Monthly-201909 获奖名单 冠军: 空缺 一等奖: 张咏真 S031802540 孔铖晗 S031802115 二等奖: 苏锦程 S031802325 林柄灿 S031802117 ...