bert模型参数简化
我们下载下来的预训练的bert模型的大小大概是400M左右,但是我们自己预训练的bert模型,或者是我们在开源的bert模型上fine-tuning之后的模型的大小大约是1.1G,我们来看看到底是什么原因造成的,首先我们可以通过下一段代码来输出我们训练好的模型的参数变量。
下面这段代码可以输出我们下载的官方预训练模型的参数变量
import tensorflow as tf
from tensorflow.python import pywrap_tensorflow model_reader = pywrap_tensorflow.NewCheckpointReader("chinese_L-12_H-768_A-12/bert_model.ckpt")
var_dict = model_reader.get_variable_to_shape_map()
for key in var_dict:
print(key)
我们截取了部分参数如下:

现在换成我们自己预训练的bert模型,代码和上面一样
from tensorflow.python import pywrap_tensorflow
model_reader = pywrap_tensorflow.NewCheckpointReader("H_12_768_L12_vocab5/model.ckpt-1500000")
var_dict = model_reader.get_variable_to_shape_map()
for key in var_dict:
print(key)
我们同样截取部分参数
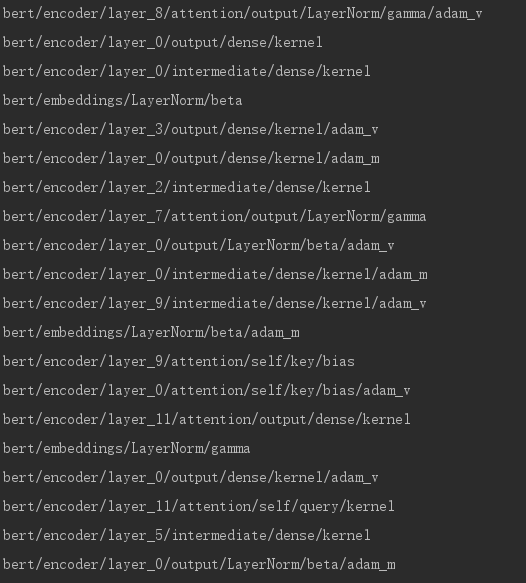
我们可以看到这里混入了不少带有"adam"的变量,我们来看adam优化算法,在计算一阶矩和二阶矩时,我们是要保存之前时刻的滑动平均值的,而每个需要通过梯度更新的参数,都要维护这样一个一阶矩和二阶矩之前时刻的滑动平均值,也就是对应上面的 "adam_m" (一阶矩) 和 “adam_v” (二阶矩),因此导致我们自己预训练的模型的大小大约是官方预训练模型的大小的3倍。而这些参数变量只有训练模型的时候有用,在之后预测的时候以及fine-tuning阶段都是没有用的(fine-tuning时我们只是用到了之前预训练好的模型的参数来作为初始化值,并不会用到优化算法中的中间值),因此我们可以在训练完或者fine-tuning完bert模型之后,在保存模型时将这些参数去掉,也可以在保存了完整的参数之后,再加载去掉这些参数,然后重新保存,这样就不需要改动bert的源码,具体的实现如下:
import re
import tensorflow as tf
from tensorflow.contrib.slim import get_variables_to_restore # 将bert中和adam相关的参数的值去掉,较小模型的内存
graph = tf.Graph()
with graph.as_default():
sess = tf.Session()
checkpoint_file = tf.train.latest_checkpoint("H_12_768_L12_vocab5/")
saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file))
saver.restore(sess, checkpoint_file) variables = get_variables_to_restore()
other_vars = [variable for variable in variables if not re.search("adam", variable.name)]
var_saver = tf.train.Saver(other_vars)
var_saver.save(sess, "light_bert/model.ckpt")
之后就可以直接加载这个去掉带"adam"的变量的模型用来做预测。这样虽然不能提升模型的预测速度,但是可以减小模型的内存。
bert模型参数简化的更多相关文章
- NLP突破性成果 BERT 模型详细解读 bert参数微调
https://zhuanlan.zhihu.com/p/46997268 NLP突破性成果 BERT 模型详细解读 章鱼小丸子 不懂算法的产品经理不是好的程序员 关注她 82 人赞了该文章 Goo ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- attention、self-attention、transformer和bert模型基本原理简述笔记
attention 以google神经机器翻译(NMT)为例 无attention: encoder-decoder在无attention机制时,由encoder将输入序列转化为最后一层输出state ...
- 深度学习方法(七):最新SqueezeNet 模型详解,CNN模型参数降低50倍,压缩461倍!
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 继续前面关于深度学习CNN经典模型的 ...
- BERT模型介绍
前不久,谷歌AI团队新发布的BERT模型,在NLP业内引起巨大反响,认为是NLP领域里程碑式的进步.BERT模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越 ...
- 想研究BERT模型?先看看这篇文章吧!
最近,笔者想研究BERT模型,然而发现想弄懂BERT模型,还得先了解Transformer. 本文尽量贴合Transformer的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- 图示详解BERT模型的输入与输出
一.BERT整体结构 BERT主要用了Transformer的Encoder,而没有用其Decoder,我想是因为BERT是一个预训练模型,只要学到其中语义关系即可,不需要去解码完成具体的任务.整体架 ...
- BERT模型
BERT模型是什么 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为de ...
随机推荐
- 洛谷p1137旅行计划
题面 关于拓扑排序 因为这好几次考试的题目里都有在DAG中拓扑排序求最长/短路 txt说它非常的好用 就找了个题做了下 拓扑排序就是寻找图中所有的入度为零的点把他入队 然后再枚举它所有的连到的点,只要 ...
- 算法&设计模式
这里更新Python 算法&设计模式部分的博客(或目录链接)
- centos7如何添加开机启动项?
centos7提供开启服务启动的方式: 1.系统服务管理命令,如果是通过yum安装的软件,开机启动脚本,已经自动创建好了,直接执行如下命令 nginx.service后缀可以省略 systemctl ...
- 企业级Nginx负载均衡与keepalived高可用实战(一)Nginx篇
1.集群简介 1.1.什么是集群 简单地说,集群就是指一组(若干个)相互独立的计算机,利用高速通信网络组成的一个较大的计算机服务系统,每个集群节点(即集群中的每台计算机)都是运行各自服务的独立服务器. ...
- 框架之jQuery妙用
1.jQuery介绍 jQuery是一个轻量级的.兼容多浏览器的JavaScript库. jQuery使用户能够更方便地处理HTML Document.Events.实现动画效果.方便地进行Ajax交 ...
- Java之数据库基础理论
一.事务的四大特性 ACID 只有满足一致性,事务的执行结果才是正确的. 在无并发的情况下,事务串行执行,隔离性一定能够满足.此时要只要能满足原子性,就一定能满足一致性. 在并发的情况下,多个事务并发 ...
- JavaScript 正则表达式匹配成功后的返回结果
原文地址:https://blog.csdn.net/liupeifeng3514/article/details/79005604 使用正则表达式EDIT 正则表达式可以被用于RegExp的exec ...
- 常见框架和WSGI协议
三大框架对比 Django 大而全 自带的功能特别特别多 类似于航空母舰 有时候过于笨重 Flask 小而精,只保留了核心功能,其他可以自由选择 第三方的模块特别特别多,如果将flask第三方模块全部 ...
- python正确使用异常处理机制
一.不要过度使用异常 不可否认,Python 的异常机制确实方便,但滥用异常机制也会带来一些负面影响.过度使用异常主要表现在两个方面: 把异常和普通错误混淆在一起,不再编写任何错误处理代码,而是以简单 ...
- JSON文件加注释的7种方法
JSON文件加注释的7种方法 缺省不能加注释,现实有需求 根据JSON规范(http://www.json.org, RFC 4627, RFC 7159),不支持注释.JSON规范之所以不允许加注释 ...