bert模型参数简化
我们下载下来的预训练的bert模型的大小大概是400M左右,但是我们自己预训练的bert模型,或者是我们在开源的bert模型上fine-tuning之后的模型的大小大约是1.1G,我们来看看到底是什么原因造成的,首先我们可以通过下一段代码来输出我们训练好的模型的参数变量。
下面这段代码可以输出我们下载的官方预训练模型的参数变量
import tensorflow as tf
from tensorflow.python import pywrap_tensorflow model_reader = pywrap_tensorflow.NewCheckpointReader("chinese_L-12_H-768_A-12/bert_model.ckpt")
var_dict = model_reader.get_variable_to_shape_map()
for key in var_dict:
print(key)
我们截取了部分参数如下:

现在换成我们自己预训练的bert模型,代码和上面一样
from tensorflow.python import pywrap_tensorflow
model_reader = pywrap_tensorflow.NewCheckpointReader("H_12_768_L12_vocab5/model.ckpt-1500000")
var_dict = model_reader.get_variable_to_shape_map()
for key in var_dict:
print(key)
我们同样截取部分参数
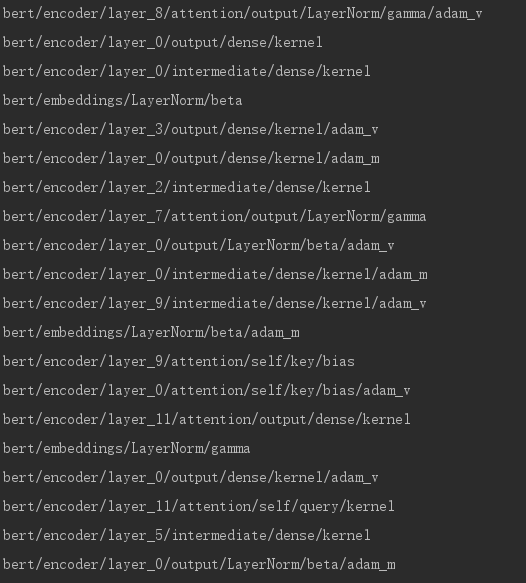
我们可以看到这里混入了不少带有"adam"的变量,我们来看adam优化算法,在计算一阶矩和二阶矩时,我们是要保存之前时刻的滑动平均值的,而每个需要通过梯度更新的参数,都要维护这样一个一阶矩和二阶矩之前时刻的滑动平均值,也就是对应上面的 "adam_m" (一阶矩) 和 “adam_v” (二阶矩),因此导致我们自己预训练的模型的大小大约是官方预训练模型的大小的3倍。而这些参数变量只有训练模型的时候有用,在之后预测的时候以及fine-tuning阶段都是没有用的(fine-tuning时我们只是用到了之前预训练好的模型的参数来作为初始化值,并不会用到优化算法中的中间值),因此我们可以在训练完或者fine-tuning完bert模型之后,在保存模型时将这些参数去掉,也可以在保存了完整的参数之后,再加载去掉这些参数,然后重新保存,这样就不需要改动bert的源码,具体的实现如下:
import re
import tensorflow as tf
from tensorflow.contrib.slim import get_variables_to_restore # 将bert中和adam相关的参数的值去掉,较小模型的内存
graph = tf.Graph()
with graph.as_default():
sess = tf.Session()
checkpoint_file = tf.train.latest_checkpoint("H_12_768_L12_vocab5/")
saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_file))
saver.restore(sess, checkpoint_file) variables = get_variables_to_restore()
other_vars = [variable for variable in variables if not re.search("adam", variable.name)]
var_saver = tf.train.Saver(other_vars)
var_saver.save(sess, "light_bert/model.ckpt")
之后就可以直接加载这个去掉带"adam"的变量的模型用来做预测。这样虽然不能提升模型的预测速度,但是可以减小模型的内存。
bert模型参数简化的更多相关文章
- NLP突破性成果 BERT 模型详细解读 bert参数微调
https://zhuanlan.zhihu.com/p/46997268 NLP突破性成果 BERT 模型详细解读 章鱼小丸子 不懂算法的产品经理不是好的程序员 关注她 82 人赞了该文章 Goo ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- attention、self-attention、transformer和bert模型基本原理简述笔记
attention 以google神经机器翻译(NMT)为例 无attention: encoder-decoder在无attention机制时,由encoder将输入序列转化为最后一层输出state ...
- 深度学习方法(七):最新SqueezeNet 模型详解,CNN模型参数降低50倍,压缩461倍!
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 继续前面关于深度学习CNN经典模型的 ...
- BERT模型介绍
前不久,谷歌AI团队新发布的BERT模型,在NLP业内引起巨大反响,认为是NLP领域里程碑式的进步.BERT模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越 ...
- 想研究BERT模型?先看看这篇文章吧!
最近,笔者想研究BERT模型,然而发现想弄懂BERT模型,还得先了解Transformer. 本文尽量贴合Transformer的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- 图示详解BERT模型的输入与输出
一.BERT整体结构 BERT主要用了Transformer的Encoder,而没有用其Decoder,我想是因为BERT是一个预训练模型,只要学到其中语义关系即可,不需要去解码完成具体的任务.整体架 ...
- BERT模型
BERT模型是什么 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为de ...
随机推荐
- 牛客CSP-S提高组赛前集训营2 ———— 2019.10.31
比赛链接 期望得分:100+20+20 实际得分:40+20+30 awa cccc T1 :基于贪心的思路,然后开始爆搜(雾 那必然是会死的,好吧他就是死了 #include<iostrea ...
- LoadRunner名词解释
Transactions(用户事务分析):用户事务分析是站在用户角度进行的基础性能分析. 1.Transation Sunmmary(事务综述) 对事务进行综合分析是性能分析的第一步,通过分析测试时间 ...
- 聊聊Runloop
1.什么是Runloop 在开始聊RunLoop之前,我们先来了解一下程序的执行原理.一般来说,程序是在线程中执行,一个线程一次只能执行一个任务(关于GCD,可看上篇文章介绍),执行完成后线程就会退出 ...
- 本地计算机上的SQL Server(MSSQLSERVER)服务启动后停止。某些服务在未由其他服务或程序使用时将自动停止
看下SQLExperss协议和 MySQLServer协议的TCP/IP端口,有可能是SQLEXPERSS将TCP端口占用了,将SQLEXPERSS的TCP/IP协议禁用,重启 SQLEXPRESS服 ...
- 在Azure DevOps Server(TFS)上集成Python环境,实现持续集成和发布
Python和Azure DevOps Server Python是一种计算机程序设计语言.是一种动态的.面向对象的脚本语言,最初主要为系统运维人员编写自动化脚本,在实际应用中,Python已经在前端 ...
- 在Visual Studio中新增生成项目
在Visual Studio中新增生成项目 选择适配器类型 选择WCF-SQL适配器 创建连接选项 选择相应的存储过程 生成相应的消息架构
- HTML+css基础 Text文本属性
Text文本属性: 1.颜色 color color:red 2.文本缩进 text-indent 属性值 数字+px: text-indent:10px: 3.文本修饰 text-decorati ...
- nginx产生【413 request entity too large】错误的原因与解决方法
项目上在做上传文件(清单导入)的时候产生了这个错误: 从字面上看,说的是请求的实体太大的问题,那么可以联想到是HTTP请求中的Body大小被限制了的原因. Nginx中的[client_max_bod ...
- golang --os系统包
环境变量 Environ 获取所有环境变量, 返回变量列表 func Environ() []string package main import ( "fmt" "os ...
- 使用VS Code远程开发
今天看到园子里的一篇文章:VS Code Remote 发布!开启远程开发新时代,简单的看了一下,它可以直接利用本地的环境远程开发,最直接的好处有: 在部署相同的操作系统上进行开发,或者使用更大或更专 ...