Flink 物理分区
Flink还通过以下函数对转换后的数据精确流分区进行低级控制(如果需要)。
1、自定义分区
使用用户定义的分区程序为每个元素选择目标任务。
dataStream.partitionCustom(partitioner, "someKey")
dataStream.partitionCustom(partitioner, 0)
如简单的hash 分区(下面的实例不是官网):
val input = env.addSource(source)
.map(json => {
// json : {"id" : 0, "createTime" : "2019-08-24 11:13:14.942", "amt" : "9.8"}
val id = json.get("id").asText()
val createTime = json.get("createTime").asText()
val amt = json.get("amt").asText()
LateDataEvent("key", id, createTime, amt)
})
.setParallelism(1)
.partitionCustom(new Partitioner[String] {
override def partition(key: String, numPartitions: Int): Int = {
// numPartitions 是下游算子的并发数
key.hashCode % numPartitions
}
}, "id")
.map(l => {
LateDataEvent(l.key, l.id, l.amt, l.createTime)
})
.setParallelism(3)
注:key 是传入的field 的类型
2、随机分区
根据均匀分布随机分配元素(类似于: random.nextInt(5),0 - 5 在概率上是均匀的)
dataStream.shuffle()
源码:
@Internal
public class ShufflePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L; private Random random = new Random(); @Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
// 传入下游分区数
return random.nextInt(numberOfChannels);
} @Override
public StreamPartitioner<T> copy() {
return new ShufflePartitioner<T>();
} @Override
public String toString() {
return "SHUFFLE";
}
}
3、均匀分区 rebalance
分区元素循环,每个分区创建相等的负载。在存在数据偏斜时用于性能优化。
dataStream.rebalance()
源码:
public class RebalancePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private int nextChannelToSendTo;
@Override
public void setup(int numberOfChannels) {
super.setup(numberOfChannels);
nextChannelToSendTo = ThreadLocalRandom.current().nextInt(numberOfChannels);
}
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
// 轮训的发往下游分区
nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;
return nextChannelToSendTo;
}
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "REBALANCE";
}
}
4、rescale
分区元素循环到下游操作的子集。如果您希望拥有管道,例如,从源的每个并行实例扇出到多个映射器的子集以分配负载但又不希望发生rebalance()会产生完全重新平衡,那么这非常有用。这将仅需要本地数据传输而不是通过网络传输数据,具体取决于其他配置值,例如TaskManagers的插槽数。
上游操作发送元素的下游操作的子集取决于上游和下游操作的并行度。例如,如果上游操作具有并行性2并且下游操作具有并行性4,则一个上游操作将元素分配给两个下游操作,而另一个上游操作将分配给另外两个下游操作。另一方面,如果下游操作具有并行性2而上游操作具有并行性4,那么两个上游操作将分配到一个下游操作,而另外两个上游操作将分配到其他下游操作。在不同并行度不是彼此的倍数的情况下,一个或多个下游操作将具有来自上游操作的不同数量的输入。
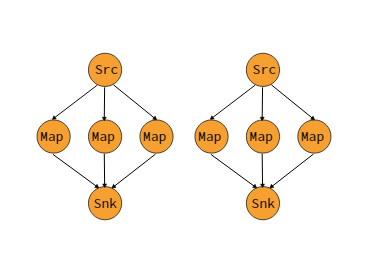
dataStream.rescale()
源码:
public class RescalePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private int nextChannelToSendTo = -1;
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
if (++nextChannelToSendTo >= numberOfChannels) {
nextChannelToSendTo = 0;
}
return nextChannelToSendTo;
}
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "RESCALE";
}
}
很遗憾这段代码只能看出,上游分区往下游分区发的时候,每个上游分区内部的数据是轮训发到下游分区的(没找到具体分配的地方,从这段代码debug,一直往上,找到分区出现在 RuntimeEnvironment 的对象里面,找不具体分配的地方)。
5、广播
向每个分区广播元素。
dataStream.broadcast()
Flink 物理分区的更多相关文章
- linux下vmware的安装、物理分区使用及卸载
1.安装 先下载安装文件VMware-Workstation-Full-12 在命令行下执行下载的文件安装即可(需要root权限) wget https://download3.vmware.com/ ...
- 扩大缩小Linux物理分区大小
由于产品在不同的标段,设备硬盘也不同, 有些500G,有些320G有些200G,开始在大硬盘上做的配置,想把自己定制好的Linux克隆到小硬盘上,再生龙会纠结空间大小的问题, 因此需要做一些分区的改变 ...
- ubuntu下挂载物理分区到openmediavault4
准备弄个NAS,但还没想好直接买现成,还是自己组装一台,先在虚拟机上体验下OpenMediaVault4和黑群晖.主系统是ubuntu,但刚买的时候这笔记本是装windows的,除了ubuntu的系统 ...
- aliyun添加数据盘后的物理分区和lvm逻辑卷两种挂载方式
一.普通磁盘分区管理方式 1.对磁盘进行分区 列出磁盘 # fdisk -l # fdisk /dev/vdb Welcome to fdisk (util-linux 2.23.2). Change ...
- linux 分区 物理卷 逻辑卷
今天我们主要说说分区.格式化.SWAP.LVM.软件RAID的创建哈~ 格式化 查看当前分区:fdisk -l 这个命令我们以前是讲过的,我现在问下,ID那项是什么意思? 83 是代表EXT2和E ...
- linux磁盘 分区 物理卷 卷组 逻辑卷 文件系统加载点操作案例
转自:truemylife.linux磁盘 分区 物理卷 卷组 逻辑卷 文件系统加载点操作案例 基本概念: 磁盘.分区.物理卷[物理部分] 卷组[中间部分] 逻辑卷.文件系统[虚拟化后可控制部分] 磁 ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- <译>Flink编程指南
Flink 的流数据 API 编程指南 Flink 的流数据处理程序是常规的程序 ,通过再流数据上,实现了各种转换 (比如 过滤, 更新中间状态, 定义窗口, 聚合).流数据可以来之多种数据源 (比如 ...
- flink学习笔记-split & select(拆分流)
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
随机推荐
- 在linux系统中安装MySQL
1.安装Linux系统中自带的MySQL安装包 在现在常用的发行版本里都集中了MySQL安装包 CentOS系统中的YUM中包含了MySQL安装包,版本是MySQL5,rpm软件包的名称是mysql- ...
- 微信小程序引入Vant组件库
前期准备 Vant Weapp组件库:https://youzan.github.io/vant-weapp/#/intro 1.先在微信开发者工具中打开项目的终端: 然后初始化一个package.j ...
- Dubbo源码分析(2):ServiceBean
ServiceBean时序图
- JQuery购物车多物品数量的加减+总价计算
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- luogu T96516 [DBOI2019]持盾 可持久化线段树+查分
因为题中的操作是区间加法,所以满足前缀相减性. 而每一次查询的时候还是单点查询,所以直接用可持久化线段树维护差分数组,然后查一个前缀和就行了. code: #include <bits/stdc ...
- 2017.10.4 国庆清北 D4T1 财富
(其实这题是luogu P1901 发射站 原题,而且数据范围还比luogu小) 题目描述 LYK有n个小伙伴.每个小伙伴有一个身高hi. 这个游戏是这样的,LYK生活的环境是以身高为美的环境,因此在 ...
- LOJ2269. 「SDOI2017」切树游戏 [FWT,动态DP]
LOJ 思路 显然是要DP的.设\(dp_{u,i}\)表示\(u\)子树内一个包含\(u\)的连通块异或出\(i\)的方案数,发现转移可以用FWT优化,写成生成函数就是这样的: \[ dp_{u}= ...
- 深入理解JVM虚拟机13:再谈四种引用及GC实践
Java中的四种引用类型 一.背景 Java的内存回收不需要程序员负责,JVM会在必要时启动Java GC完成垃圾回收.Java以便我们控制对象的生存周期,提供给了我们四种引用方式,引用强度从强到弱分 ...
- 记Oracle中regexp_substr的一次调优(速度提高95.5%)
项目中需要做一个船舶代理费的功能,针对代理的船进行收费,那么该功能的第一步便是选择进行代理费用信息的录入,在进行船舶选择的时候,发现加载相关船舶信息十分的慢,其主要在sql语句的执行,因为测试的时候数 ...
- 小福bbs-冲刺日志(第四天)
[小福bbs-冲刺日志(第四天)] 这个作业属于哪个课程 班级链接 这个作业要求在哪里 作业要求的链接 团队名称 小福bbs 这个作业的目标 两个前端完成15个界面 作业的正文 小福bbs-冲刺日志( ...