Flink 物理分区
Flink还通过以下函数对转换后的数据精确流分区进行低级控制(如果需要)。
1、自定义分区
使用用户定义的分区程序为每个元素选择目标任务。
dataStream.partitionCustom(partitioner, "someKey")
dataStream.partitionCustom(partitioner, 0)
如简单的hash 分区(下面的实例不是官网):
val input = env.addSource(source)
.map(json => {
// json : {"id" : 0, "createTime" : "2019-08-24 11:13:14.942", "amt" : "9.8"}
val id = json.get("id").asText()
val createTime = json.get("createTime").asText()
val amt = json.get("amt").asText()
LateDataEvent("key", id, createTime, amt)
})
.setParallelism(1)
.partitionCustom(new Partitioner[String] {
override def partition(key: String, numPartitions: Int): Int = {
// numPartitions 是下游算子的并发数
key.hashCode % numPartitions
}
}, "id")
.map(l => {
LateDataEvent(l.key, l.id, l.amt, l.createTime)
})
.setParallelism(3)
注:key 是传入的field 的类型
2、随机分区
根据均匀分布随机分配元素(类似于: random.nextInt(5),0 - 5 在概率上是均匀的)
dataStream.shuffle()
源码:
@Internal
public class ShufflePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L; private Random random = new Random(); @Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
// 传入下游分区数
return random.nextInt(numberOfChannels);
} @Override
public StreamPartitioner<T> copy() {
return new ShufflePartitioner<T>();
} @Override
public String toString() {
return "SHUFFLE";
}
}
3、均匀分区 rebalance
分区元素循环,每个分区创建相等的负载。在存在数据偏斜时用于性能优化。
dataStream.rebalance()
源码:
public class RebalancePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private int nextChannelToSendTo;
@Override
public void setup(int numberOfChannels) {
super.setup(numberOfChannels);
nextChannelToSendTo = ThreadLocalRandom.current().nextInt(numberOfChannels);
}
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
// 轮训的发往下游分区
nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;
return nextChannelToSendTo;
}
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "REBALANCE";
}
}
4、rescale
分区元素循环到下游操作的子集。如果您希望拥有管道,例如,从源的每个并行实例扇出到多个映射器的子集以分配负载但又不希望发生rebalance()会产生完全重新平衡,那么这非常有用。这将仅需要本地数据传输而不是通过网络传输数据,具体取决于其他配置值,例如TaskManagers的插槽数。
上游操作发送元素的下游操作的子集取决于上游和下游操作的并行度。例如,如果上游操作具有并行性2并且下游操作具有并行性4,则一个上游操作将元素分配给两个下游操作,而另一个上游操作将分配给另外两个下游操作。另一方面,如果下游操作具有并行性2而上游操作具有并行性4,那么两个上游操作将分配到一个下游操作,而另外两个上游操作将分配到其他下游操作。在不同并行度不是彼此的倍数的情况下,一个或多个下游操作将具有来自上游操作的不同数量的输入。
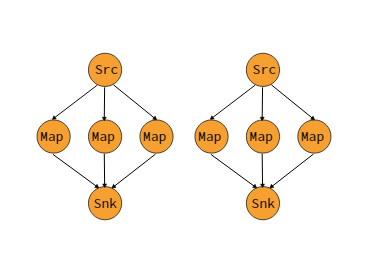
dataStream.rescale()
源码:
public class RescalePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;
private int nextChannelToSendTo = -1;
@Override
public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
if (++nextChannelToSendTo >= numberOfChannels) {
nextChannelToSendTo = 0;
}
return nextChannelToSendTo;
}
public StreamPartitioner<T> copy() {
return this;
}
@Override
public String toString() {
return "RESCALE";
}
}
很遗憾这段代码只能看出,上游分区往下游分区发的时候,每个上游分区内部的数据是轮训发到下游分区的(没找到具体分配的地方,从这段代码debug,一直往上,找到分区出现在 RuntimeEnvironment 的对象里面,找不具体分配的地方)。
5、广播
向每个分区广播元素。
dataStream.broadcast()
Flink 物理分区的更多相关文章
- linux下vmware的安装、物理分区使用及卸载
1.安装 先下载安装文件VMware-Workstation-Full-12 在命令行下执行下载的文件安装即可(需要root权限) wget https://download3.vmware.com/ ...
- 扩大缩小Linux物理分区大小
由于产品在不同的标段,设备硬盘也不同, 有些500G,有些320G有些200G,开始在大硬盘上做的配置,想把自己定制好的Linux克隆到小硬盘上,再生龙会纠结空间大小的问题, 因此需要做一些分区的改变 ...
- ubuntu下挂载物理分区到openmediavault4
准备弄个NAS,但还没想好直接买现成,还是自己组装一台,先在虚拟机上体验下OpenMediaVault4和黑群晖.主系统是ubuntu,但刚买的时候这笔记本是装windows的,除了ubuntu的系统 ...
- aliyun添加数据盘后的物理分区和lvm逻辑卷两种挂载方式
一.普通磁盘分区管理方式 1.对磁盘进行分区 列出磁盘 # fdisk -l # fdisk /dev/vdb Welcome to fdisk (util-linux 2.23.2). Change ...
- linux 分区 物理卷 逻辑卷
今天我们主要说说分区.格式化.SWAP.LVM.软件RAID的创建哈~ 格式化 查看当前分区:fdisk -l 这个命令我们以前是讲过的,我现在问下,ID那项是什么意思? 83 是代表EXT2和E ...
- linux磁盘 分区 物理卷 卷组 逻辑卷 文件系统加载点操作案例
转自:truemylife.linux磁盘 分区 物理卷 卷组 逻辑卷 文件系统加载点操作案例 基本概念: 磁盘.分区.物理卷[物理部分] 卷组[中间部分] 逻辑卷.文件系统[虚拟化后可控制部分] 磁 ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- <译>Flink编程指南
Flink 的流数据 API 编程指南 Flink 的流数据处理程序是常规的程序 ,通过再流数据上,实现了各种转换 (比如 过滤, 更新中间状态, 定义窗口, 聚合).流数据可以来之多种数据源 (比如 ...
- flink学习笔记-split & select(拆分流)
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
随机推荐
- C++处理异常
C++处理异常
- 接口-DBLINK初尝试
需求: 将寿险核心库中的黑名单数据提取到团险核心中,供团险核心使用,并且在核心前端页面需配置对应的菜单,提供相应的按钮,该接口采用dblink的方式进行提取. 通过本地数据库配置dblink访问远程数 ...
- Vue模板语法(一)
Vue模板语法 一 vue简介 Vue.js是一套构建用户界面的渐进式框架. 与其他重量级框架不同的是,Vue 采用自底向上增量开发的设计. Vue 的核心库只关注视图层,并且非常容易学习,非常容易与 ...
- 020_Python3 File(文件) 方法
1.open() 方法 Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError. 注意:使用 open ...
- nowcoder73E 白兔的刁难 单位根反演+NTT
感觉很套路? #include <bits/stdc++.h> #define ll long long #define setIO(s) freopen(s".in" ...
- 使用状态文件+vigil 监控系统状态
vigil 是一个不错的系统可用性报告系统,具有还不错的ui 界面,同时也有通知配置,以下是一个简单的 demo 使用状态文件,以及http body 匹配的模式进行web 应用状态的监控,只是简单的 ...
- makefile通用版本(一)
实际当中程序文件比较大,这时候对文件进行分类,分为头文件.源文件.目标文件.可执行文件.也就是说通常将文件按照文件类型放在不同的目录当中,这个时候的Makefile需要统一管理这些文件,将生产的目标文 ...
- 《挑战30天C++入门极限》C++面向对象编程入门:类(class)
C++面向对象编程入门:类(class) 上两篇内容我们着重说了结构体相关知识的操作. 以后的内容我们将逐步完全以c++作为主体了,这也意味着我们的教程正式进入面向对象的编程了. 前面的教程我 ...
- npropress进度条插件的使用
官网下载地址:http://ricostacruz.com/nprogress/ npropress.css /* Make clicks pass-through */ #nprogress { p ...
- Maven项目启动失败:class path resource [spring/] cannot be resolved to URL because it does not exist
目录 Maven项目启动失败:class path resource [spring/] cannot be resolved to URL because it does not exist 解决方 ...