你的DDPG/RDPG为何不收敛?
- DDPG不收敛的潜在原因分析
- RDPG不收敛的潜在原因分析(含Github上几个不能收敛的RDPG源码分析)
- D(R)DPG可以收敛的源码(分Keras和pytorch两种版本)
- 强化学习实践(编程)过程的几点建议
一:DDPG不收敛的潜在原因分析
先上DDPG的算法伪代码:

(1)在编写Q(s, a)的过程中,错误的使用了layer.Add层而非layer.concatenate (keras版)或torch.cat (pytorch版)
会导致不收敛的critic代码如下:
#程序清单1
1 from keras.layers import Add
2 #如下代码定义了critic网络
3 def _build_critic(self, featureDim, actionDim, learningRate=LR_C):
4 stateInputs = Input(shape = (featureDim, ), name = 'State-Input')
5 actionInput = Input(shape = (actionDim, ), name = 'Action-Input')
6 stateOut = Dense(30, activation = 'relu')(stateInputs)
7 actionOut = Dense(30, activation = 'relu')(actionInput)
8 Outputs = Add()([stateOut, actionOut])
9 init = RandomUniform(minval = -0.003, maxval = 0.003)
10 Outputs = Dense(1, activation = 'linear', name = 'Q-Value', kernel_initializer = init)(Outputs)
11 critic = Model(inputs = [stateInputs, actionInput], outputs = Outputs)
12 return critic
不收敛原因的分析:写代码的时候一定要多想想Q(s, a)的本质是什么?Q(s, a)的本质是多键值的联合查表,即采用s和a作为键值在一个表格中查表,只不过这个表格用神经网络替代了。也就是说,作为键值,s和a一定要分别单独给出,而不能加在一起然后再给神经网络。
可以收敛的critic写法如下(Keras版):
#程序清单2
1 from keras.layers import concatenate
2
3 def _build_critic(self, featureDim, actionDim, learningRate=LR_C):
4
5 sinput = Input(shape=(featureDim,), name='state_input')
6 ainput = Input(shape=(actionDim,), name='action_input')
7 s = Dense(40, activation='relu')(sinput)
8 a = Dense(40, activation='relu')(ainput)
9 x = concatenate([s, a])
10 x = Dense(40, activation='relu')(x)
11 output = Dense(1, activation='linear')(x)
12
13 model = Model(inputs=[sinput, ainput], outputs=output)
14 model.compile(loss='mse', optimizer=Adam(lr=learningRate))
15
16 return model
(2)如果采用PyTorch编写actor神经网络,有一点要注意(经笔者实验,只有PyTorch有这个问题,Keras的coder可以放心的跳过这一节了)
使用PyTorch尽量不要使用Lambda层,实验结果上来看它似乎非常影响收敛性。尽管Keras上使用Lambda层不影响收敛性。
会导致收敛过程很坎坷甚至不收敛的actor代码如下:
#程序清单3
1 class Actor(torch.nn.Module):
2 def __init__(self, s_dim, a_dim):
3 super(Actor, self).__init__()
4 self.Layer1 = torch.nn.Linear(s_dim, 30) # Input layer
5 self.Layer2 = torch.nn.Linear(30, 30)
6 self.Layer3 = torch.nn.Linear(30, a_dim)
7 self.relu = torch.nn.ReLU()
8 self.tanh = torch.nn.Tanh()
9
10 def forward(self, s_input):
11 out = self.relu(self.Layer1(s_input)) # linear output
12 out = self.relu(self.Layer2(out))
13 out = self.tanh(self.Layer3(out))
14 out = Lambda(lambda x: x * 2)(out)
15 return out
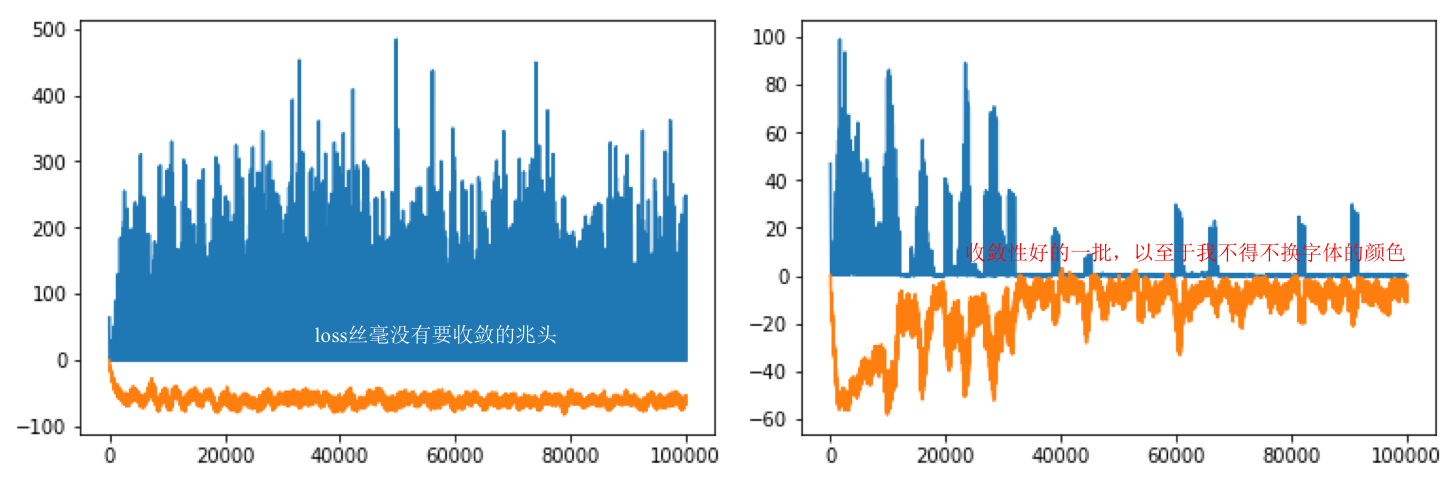
注意到程序的第14行引用了Lambda层,笔者当时解决的问题是“Pendulum-v0”,对于该问题,合法的动作空间是[-2, 2]之间的。而13行的tanh输出在[-1, 1]之间。所以需要把13行的输出乘以2。但是笔者发现,这种写法收敛的过程相较不采用Lambda层而直接将out乘以2(代码之后给出)输出收敛的更慢,并且收敛的过程会被反复破坏然后再收敛,如下图:

上图的蓝线表示critic_loss, 橘线表示实时动作-状态值函数的预测输出。可以从上图(左)看到,在PyTorch中采用Lambda层规范动作值使得critic对动作-状态值函数的预测难以收敛,这表示它对critic的预测带来了负面的影响,总是不断的破坏critic的收敛性。上图(右)的代码如程序清单4中所示。直接将上一层网络的输出乘以2而没有使用Lambda层。可见critic的预测可以逐渐趋近于0(对于Pendulum-v0这是收敛,其他环境不趋于0),收敛性也好了很多。
可以收敛的actor写法如下:
#程序清单4
1 class Actor(torch.nn.Module):
2 def __init__(self, s_dim, a_dim):
3 super(Actor, self).__init__()
4
5 self.l1 = torch.nn.Linear(s_dim, 40)
6 self.l2 = torch.nn.Linear(40, 30)
7 self.l3 = torch.nn.Linear(30, a_dim)
8
9 def forward(self, x):
10 x = F.relu(self.l1(x))
11 x = F.relu(self.l2(x))
12 x = 2 * torch.tanh(self.l3(x))
13 return x
(3)如果采用PyTorch编写critic神经网络,有一点要注意(经笔者实验,也是只有PyTorch有这个问题,Keras的coder可以放心的跳过这一节了)
在编写Q(s, a)的时候,s和a一定要在一开始输入神经网络的时候就做连接操作(上文提到的concatenate)而不要让s和a分别经过一层神经网络后再做连接操作。否则,critic会不收敛。
会导致不收敛的critic代码如下:
#程序清单5
1 class Critic(torch.nn.Module):
2 def __init__(self, s_dim, a_dim):
3 super(Critic, self).__init__()
4 self.Layer1_s = torch.nn.Linear(s_dim, 30)
5 self.Layer1_a = torch.nn.Linear(a_dim, 30)
6 self.Layer2 = torch.nn.Linear(30+30, 30)
7 self.Layer3 = torch.nn.Linear(30, 1)
8 self.relu = torch.nn.ReLU()
9
10 def forward(self, s_a):
11 s, a = s_a
12 out_s = self.relu(self.Layer1_s(s))
13 out_a = self.relu(self.Layer1_a(a))
14 out = self.relu(self.Layer2(torch.cat([out_s, out_a], dim=-1)))
15 out = self.Layer3(out)
16 return out
上图的蓝线表示critic_loss, 橘线表示实时动作-状态值函数的预测输出。上图(左)是程序清单5运行的结果输出。上图(右)是程序清单6运行的结果输出。
可以收敛的critic写法如下:
#程序清单6
1 class Critic(torch.nn.Module):
2 def __init__(self, s_dim, a_dim):
3 super(Critic, self).__init__()
4
5 self.l1 = torch.nn.Linear(s_dim + a_dim, 40)
6 self.l2 = torch.nn.Linear(40 , 30)
7 self.l3 = torch.nn.Linear(30, 1)
8
9 def forward(self, x_u):
10 x, u = x_u
11 x = F.relu(self.l1(torch.cat([x, u], 1)))
12 x = F.relu(self.l2(x))
13 x = self.l3(x)
14 return x
你的DDPG/RDPG为何不收敛?的更多相关文章
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 深度强化学习:Policy-Based methods、Actor-Critic以及DDPG
Policy-Based methods 在上篇文章中介绍的Deep Q-Learning算法属于基于价值(Value-Based)的方法,即估计最优的action-value function $q ...
- 强化学习调参技巧二:DDPG、TD3、SAC算法为例:
1.训练环境如何正确编写 强化学习里的 env.reset() env.step() 就是训练环境.其编写流程如下: 1.1 初始阶段: 先写一个简化版的训练环境.把任务难度降到最低,确保一定能正常训 ...
- 【算法总结】强化学习部分基础算法总结(Q-learning DQN PG AC DDPG TD3)
总结回顾一下近期学习的RL算法,并给部分实现算法整理了流程图.贴了代码. 1. value-based 基于价值的算法 基于价值算法是通过对agent所属的environment的状态或者状态动作对进 ...
- DNS解析过程和域名收敛、域名发散、SPDY应用
前段时间项目要做域名收敛,糊里糊涂的完成了,好多原理不清晰,现在整理搜集下知识点. 域名收敛的目的是什么?简单来说就是域名解析慢.那为什么解析慢?且听下文慢慢道来. 什么是DNS? DNS( Doma ...
- 非Animal呢?为何不写个万用类
/*4.非Animal呢?为何不写个万用类 * 类Object是JAVA里多有类的源头/父类*/ import java.util.*; class Animalb{ String name; voi ...
- Hadoop之为何不使用RAID?
一.引言: 在一次和同事的讨论中遇到一个这样的问题:有一个hadoop集群,在hbase的put数据出现瓶颈,他们想要把datanode上的磁盘做成RAID 0(比如10块磁盘做成一个RAID 0), ...
- 再论EM算法的收敛性和K-Means的收敛性
标签(空格分隔): 机器学习 (最近被一波波的笔试+面试淹没了,但是在有两次面试时被问到了同一个问题:K-Means算法的收敛性.在网上查阅了很多资料,并没有看到很清晰的解释,所以希望可以从K-Mea ...
- FPGA高级设计——时序分析和收敛(转)
何谓静态时序分析(Static Timing Analysis,简称STA)? 它可以简单的定义为:设计者提出一些特定的时序要求(或者说是添加特定的时序约束),套用特定的时序模型,针对特定的电路进行分 ...
- 收敛 p75
三种收敛.中心极限定理.大数定理.delta方法
随机推荐
- 跨界协作:借助gRPC实现Python数据分析能力的共享
gRPC是一个高性能.开源.通用的远程过程调用(RPC)框架,由Google推出.它基于HTTP/2协议标准设计开发,默认采用Protocol Buffers数据序列化协议,支持多种开发语言. 在gR ...
- 【Unity3D】固定管线着色器二
1 前言 固定管线着色器一 中介绍了 Shader 中外部属性.光照.贴图等基础用法,本文将进一步讲解固定管线着色器,介绍正面与反面剔除.Alpha 测试.深度测试.混合.渲染队列等用法.渲染管线 ...
- java类初始化及代码块加载顺序连根拔起
说明 相信很多人对于java中父子继承关系中,子类实例化调用过程中,代码块的执行顺序都容易忘记或搞混,尤其是java初级笔试题或面试题最容易出这类题目,让人恨得牙痒痒!!! 本文就一次性将其连根铲除, ...
- ORACLE cannot fetch plan for SQL_ID
今天做SQL执行计划测试的时候,发现sqlplus无法正常打印执行计划,根据网上资料整理如下: ..... SYS@orcl> select * 2 from table( 3 ...
- Java并发编程实例--10.使用线程组
并发API提供的一个有趣功能是可以将多个线程组成一个组. 这样我们就能将这一组线程看做一个单元并且提供改组内线程对象的读取操作.例如 你有一些线程在执行同样的任务并且你想控制他们,不考虑有多少个线程仍 ...
- letcode-两数相除
题解 设未知数: Br= 125 / 3,拆进行如下拆解: Br = 125 / 3 Br = (29 + 96)/3 Br = 29/3 + (32 * 3) / 3 Br = 29/3 + (2 ...
- 7zip 命令行压缩指定后缀名
接到一个需求,就是测试同学在测试软件的指定功能时,可能需要调试版本来查看输出信息,所以我们需要使用一个批处理文件来快速生成一个 debug 压缩包 7zip 给出了很多有用的命令行,我们可以使用它指定 ...
- APISIX介绍
APISIX是什么 Apache APISIX是Apache软件基金会下的云原生API网关,它兼具动态.实时.高性能等特点,提供了负载均衡.动态上游.灰度发布(金丝雀发布).服务熔断.身份认证.可观测 ...
- Qt+QtWebApp开发笔记(二):http服务器日志系统介绍、添加日志系统至Demo测试
前言 上一篇使用QtWebApp的基于Qt的轻量级http服务器实现了一个静态网页返回的Demo,网页服务器很重要的就是日志,因为在服务器类上并没有直接返回,所以,本篇先把日志加上. Demo ...
- 【ACM专项练习#03】打印图形、栈的合法性、链表操作、dp实例
运营商活动 题目描述 小明每天的话费是1元,运营商做活动,手机每充值K元就可以获赠1元,一开始小明充值M元,问最多可以用多少天? 注意赠送的话费也可以参与到奖励规则中 输入 输入包括多个测试实例.每个 ...