MapReduce实现倒排索引(类似协同过滤)
一、问题背景
倒排索引其实就是出现次数越多,那么权重越大,不过我国有凤巢....zf为啥不管,总局回应推广是不是广告有争议...
eclipse里ctrl+t找接口或者抽象类的实现类,看看都有啥方法,有时候hadoop的抽象类返回的接口没有需要的方法,那么我们返回他的实现类。
吧需要的文件放入hdfs下的目录下,只要不是以下划线开头的均算。
二、理论准备
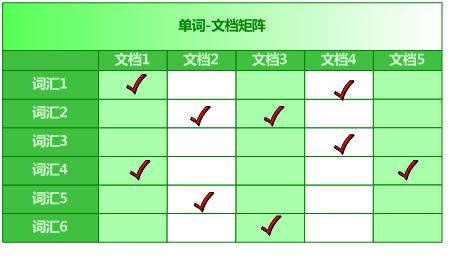
搜索引擎查询的时候就是查询这个单词文档矩阵,旺旺采用倒排索引存储,后缀树也可以。
不管理论直接看例子,这是原始的文档
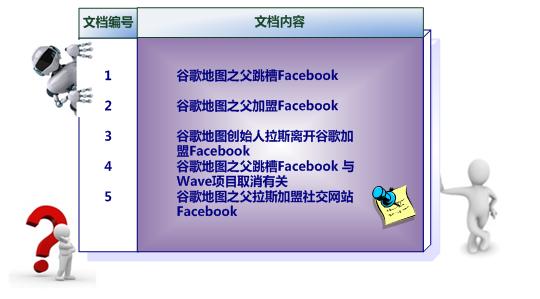
下面是简单的索引,只是表征是否在文档中出现过。
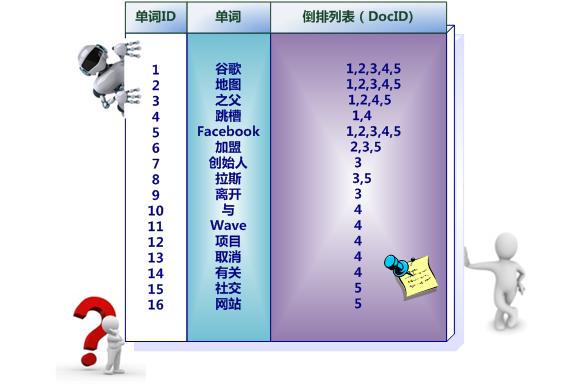
下面就是文档及出现次数。
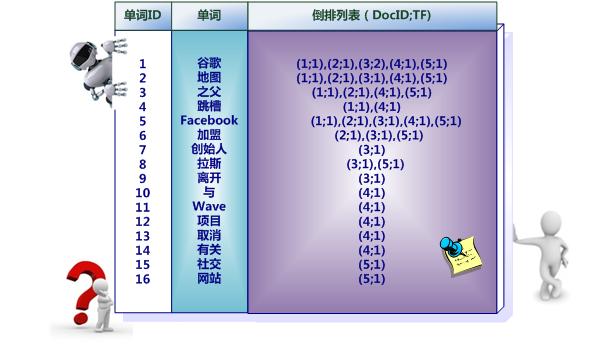
擦,咋有点想协同过滤。
三、思路分析
其实是一个全文检索的数据结构。理论上关键字出现次数越多,那么文章就越靠前。
就是wc的加强版本。wc是统计单词在文章里出现的次数,倒排是统计关键字在各个文章出现的次数。
有时候不能一下子写出来,可能需要多次mr,那么我们首先确定最终的结果形式,然后向上反推。
如果多个mr,考虑使用combiner,不过要考虑combiner是不是可插拔的,也就是combiner和业务逻辑是否和reducer一样。
怎么知道单词出现在那个文章里?从context对象里获取。既然能忘context写东西,那么也能从其中获取信息。
最终结果是
hello "a.txt->5 b.txt->3"
tom "a.txt->2 b.txt->1"
kitty "a.txt->1"
那么reduce的输出
context.write("hello","a.txt->5 b.txt->3");
那么combiner阶段是
<"hello",{"a.txt->5","b.txt->3"}>
那么map的输出
context.write("hello","a.txt->5");
context.write("hello","b.txt->3");
不过考虑到wc,map的输出应该是,路径放在value不好处理,还要廉价呢。
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->a.txt",1);
context.write("hello->b.txt",1);
context.write("hello->b.txt",1);
context.write("hello->b.txt",1);
那么combiner阶段根据就输出
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1>
<"hello->a.txt",1> <"hello->b.txt",1>
<"hello->b.txt",1>
<"hello->b.txt",1> context.write("hello","a.txt->5");
context.write("hello","b.txt->3");
次是不同文件的相同key并没有合并,reducer合并输出皆可。
四、代码实现
4.1 Mapper
public class IIMapper1 extends Mapper<LongWritable, Text, Text, Text> {
private Text k = new Text();
//下面其实是int,不过也可以在接收端Integer.parseInt转了就好
private Text v = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
//从context对象里找到单词属于那个文章
//context.getInputSplit();找到切片 按ctrl找 发现返回时InputSplit
//不过是个抽象类 ctrl + t找他的实现类
//能把数据写入context,繁殖也能从context拿到很多信息
//从下面inputSplit调用get的时候发现没有合适的方法,那么我们找他的实现类,调用实现类的方法
//InputSplit inputSplit = context.getInputSplit();
//inputSplit.get
//他的子类很多 我们处理文件就用File开头的 然后有个getPath
FileSplit inputSplit = (FileSplit)context.getInputSplit();
//文件名是hdfs://hostname:port/a/1.txt
//我们戒掉hdfs://hostname:port 不能戒掉a 应为这是文件夹否则不知道1.txt来自哪 其他文件家下可能也有同名文件
//也可以不接去
String path = inputSplit.getPath().toString();
for(String w:words) {
k.set(w+"->"+path);
v.set("1");
context.write(k, v);
}
}
}
4.2 Combiner
String[] wordAndPath = key.toString().split("->");
String word = wordAndPath[0];
String path = wordAndPath[1];
// process values
int sum = 0;
for (Text val : value) {
sum += Integer.parseInt(val.toString());
}
k.set(word);
v.set(path+"->"+sum);
context.write(k, v);
4.3 Reducer
//不涉及多线程 用StringBuilde即可
StringBuilder sb = new StringBuilder();
// process values
for (Text val : value) {
sb.append(val.toString()).append("\t");
}
context.write(key, new Text(sb.toString()));
四、实验分析

MapReduce实现倒排索引(类似协同过滤)的更多相关文章
- 基于物品的协同过滤ItemCF的mapreduce实现
文章的UML图比较好看..... 原文链接:www.cnblogs.com/anny-1980/articles/3519555.html 基于物品的协同过滤ItemCF 数据集字段: 1. Use ...
- 基于MapReduce的(用户、物品、内容)的协同过滤推荐算法
1.基于用户的协同过滤推荐算法 利用相似度矩阵*评分矩阵得到推荐列表 已经推荐过的置零 2.基于物品的协同过滤推荐算法 3.基于内容的推荐 算法思想:给用户推荐和他们之前喜欢的物品在内容上相似的物品 ...
- 基于协同过滤的个性化Web推荐
下面这是论文笔记,其实主要是摘抄,这片博士论文很有逻辑性,层层深入,所以笔者保留的比较多. 看到第二章,我发现其实这片文章对我来说更多是科普,科普吧…… 一.论文来源 Personalized Web ...
- SimRank协同过滤推荐算法
在协同过滤推荐算法总结中,我们讲到了用图模型做协同过滤的方法,包括SimRank系列算法和马尔科夫链系列算法.现在我们就对SimRank算法在推荐系统的应用做一个总结. 1. SimRank推荐算法的 ...
- MapRedcue的demo(协同过滤)
MapRedcue的演示(协同过滤) 做一个关于电影推荐.你于你好友之间的浏览电影以及电影评分的推荐的协同过滤. 百度百科: 协同过滤简单来说是利用某兴趣相投.拥有共同经验之群体的喜好来推荐用户感兴趣 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:协同过滤算法
实验目的 初步认识推荐系统 学会用mapreduce实现复杂的算法 学会系统过滤算法的基本步骤 实验原理 前面我们说过了qq的好友推荐,其实推荐算法是所有机器学习算法中最重要.最基础.最复杂的算法,一 ...
- [Recommendation System] 推荐系统之协同过滤(CF)算法详解和实现
1 集体智慧和协同过滤 1.1 什么是集体智慧(社会计算)? 集体智慧 (Collective Intelligence) 并不是 Web2.0 时代特有的,只是在 Web2.0 时代,大家在 Web ...
- 【转载】协同过滤 & Spark机器学习实战
因为协同过滤内容比较多,就新开一篇文章啦~~ 聚类和线性回归的实战,可以看:http://www.cnblogs.com/charlesblc/p/6159187.html 协同过滤实战,仍然参考:h ...
- Spark MLlib之协同过滤
原文:http://blog.selfup.cn/1001.html 什么是协同过滤 协同过滤(Collaborative Filtering, 简称CF),wiki上的定义是:简单来说是利用某兴趣相 ...
随机推荐
- 使用dubbo分布式服务框架发布服务及消费服务
什么是DUBBO DUBBO是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案. 准备工作 安装zookeeper ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服 ...
- RMAN-03002, RMAN-06059, ORA-19625 and ORA-27037 When Running RMAN Backup of Archivelogs
RMAN备份数据库时,出现下面错误错误信息: Starting backup at 25-MAY-15 current log archived allocated channel: ORA_DISK ...
- ORA-04063: view "SYS.DBA_REGISTRY" has errors
测试环境做了RMAN还原(从10.2.0.4.0 32bit 还原到 10.2.0.4.0 64bit)后,查询dba_registry系统视图时报如下错误 SQL> select comp_ ...
- 使用jsonp跨域调用百度js实现搜索框智能提示,并实现鼠标和键盘对弹出框里候选词的操作【附源码】
项目中常常用到搜索,特别是导航类的网站.自己做关键字搜索不太现实,直接调用百度的是最好的选择.使用jquery.ajax的jsonp方法可以异域调用到百度的js并拿到返回值,当然$.getScript ...
- git 命令使用总结
聊下 git rebase -i 聊下git merge --squash 聊下git pull --rebase 聊下 git remote prune origin 聊下 git 使用前的一些注意 ...
- .NET项目开发—浅谈面向对象的纵横向关系、多态入口,单元测试(项目小结)
阅读目录: 1.开篇介绍 2.使用委托消除函数串联调用 2.1.使用委托工厂转换两个独立层面的对象 3.多态入口(面向对象继承体系是可被扩展的) 4.多态的受保护方法的单元测试(Protected成员 ...
- 烂泥:智能DNS使用与配置
本文由ilanniweb提供友情赞助,首发于烂泥行天下 想要获得更多的文章,可以关注我的微信ilanniweb 公司的业务现在已经扩展到海外,对外提供的统一接口都是通过域名来解析的,但是海外用户访问国 ...
- js,jq新增元素 ,on绑定事件无效
在jquery1.7之后,建议使用on来绑定事件. $('.upload a').on('click',function(){ $(this).remove(); }) 在DOM渲染的时候,也就是ht ...
- android开发之onCreate( )方法详解
这里我们只关注一句话:This is where you should do all of your normal static set up.其中我们只关注normal static,normal: ...
- android edittext属性说明
将EditText内容转换为字符串: EditText.getText().toString() <EditText android:id="@+id/edt_month" ...