python-使用百度AipOcr实现表格文字图片识别
注:本博客中的代码实现来自百度问答:https://jingyan.baidu.com/article/c1a3101ef9131c9e646deb5c.html
代码运行环境:win10 python3.7
需要aip库,使用pip install baidu-aip即可
(1)目的
通过百度AipOcr库,来实现识别图片中的表格,并输出问表格文件。
(2)实现
仿照百度问答:https://jingyan.baidu.com/article/c1a3101ef9131c9e646deb5c.html,实现了以下代码:
1 # encoding: utf-8
2 import os
3 import sys
4 import requests
5 import time
6 import tkinter as tk
7 from tkinter import filedialog
8 from aip import AipOcr
9
10 # 定义常量
11 APP_ID = 'xxxxxx'
12 API_KEY = 'xxxxxxxxxxxxxxxxxxxxxx'
13 SECRET_KEY = 'xxxxxxxxxxxxxxxxxxxxxxxxx'
14 # 初始化AipFace对象
15 client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
16
17 # 读取图片
18 def get_file_content(filePath):
19 with open(filePath, 'rb') as fp:
20 return fp.read()
21
22
23 #文件下载函数
24 def file_download(url, file_path):
25 r = requests.get(url)
26 with open(file_path, 'wb') as f:
27 f.write(r.content)
28
29
30 if __name__ == "__main__":
31 root = tk.Tk()
32 root.withdraw()
33 data_dir = filedialog.askdirectory(title='请选择图片文件夹') + '/'
34 result_dir = filedialog.askdirectory(title='请选择输出文件夹') + '/'
35 num = 0
36 for name in os.listdir(data_dir):
37 print ('{0} : {1} 正在处理:'.format(num+1, name.split('.')[0]))
38 image = get_file_content(os.path.join(data_dir, name))
39 res = client.tableRecognitionAsync(image)
40 # print ("res:", res)
41 if 'error_code' in res.keys():
42 print ('Error! error_code: ', res['error_code'])
43 sys.exit()
44 req_id = res['result'][0]['request_id'] #获取识别ID号
45
46 for count in range(1, 20): #OCR识别也需要一定时间,设定10秒内每隔1秒查询一次
47 res = client.getTableRecognitionResult(req_id) #通过ID获取表格文件XLS地址
48 print(res['result']['ret_msg'])
49 if res['result']['ret_msg'] == '已完成':
50 break #云端处理完毕,成功获取表格文件下载地址,跳出循环
51 else:
52 time.sleep(1)
53
54 url = res['result']['result_data']
55 xls_name = name.split('.')[0] + '.xls'
56 file_download(url, os.path.join(result_dir, xls_name))
57 num += 1
58 print ('{0} : {1} 下载完成。'.format(num, xls_name))
59 time.sleep(1)
(3)实现效果
识别的表格图片为:

实现的效果为(注:表格的格式人为调整过,但内容没人为修改):
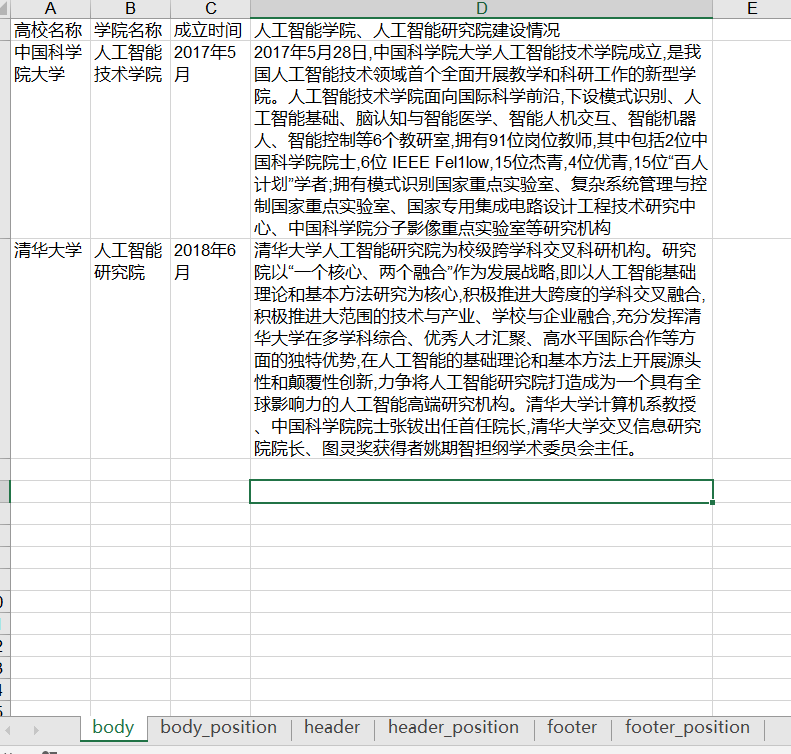
可以看出,识别的精度还是很高的,只有“Fellow”识别为了“Fel1low”。
(4)其它
百度智能云应用创建链接:https://console.bce.baidu.com/ai/?_=1585935093810#/ai/ocr/app/list,创建了一个应用之后,就可以获得APP_ID、API_KEY、SECRET_KEY。
百度智能云文字识别接口说明:https://cloud.baidu.com/doc/OCR/s/3k3h7yeqa。
python-使用百度AipOcr实现表格文字图片识别的更多相关文章
- 小白学Python——用 百度AI 实现 OCR 文字识别
百度AI功能还是很强大的,百度AI开放平台真的是测试接口的天堂,免费接口很多,当然有量的限制,但个人使用是完全够用的,什么人脸识别.MQTT服务器.语音识别等等,应有尽有. 看看OCR识别免费的量 快 ...
- Springboot 结合百度IORC实现自定义模板图片识别
前言: 首先呢,最近再公司的项目当中遇到这样的一个问题,就是需要识别图片,提取图片当中的关键语句,而且识别的语句当然是人家手写体识别,翻来覆去一想,最终还是决定使用百度的OCR帮助我解决这一项需求 话 ...
- python截图+百度ocr(图片识别)+ 百度翻译
一直想用python做一个截图并自动翻译的工具,恰好最近有时间就在网上找了资料,根据资料以及自己的理解做了一个简单的截图翻译工具.整理一下并把代码放在github给大家参考.界面用python自带的G ...
- Python通过百度Ai识别图片中的文字
版本:python3.7 工作中有需要识别图片中的汗字,查看了半天大神们的博客,但没找到完全可以用的源码,经过自己的实践,以下源码可以实现: 创建应用 首先你需要登录百度AI,选择文字识别,创建一个应 ...
- Python使用EasyOCR库对行程码图片进行OCR文字识别介绍与实践
关注「WeiyiGeek」点我,点我 设为「特别关注」,每天带你在B站玩转网络安全运维.应用开发.物联网IOT学习! 希望各位看友[关注.点赞.评论.收藏.投币],助力每一个梦想. 文章目录 0x00 ...
- 使用python爬取百度贴吧内的图片
1. 首先通过urllib获取网页的源码 # 定义一个getHtml()函数 def getHtml(url): try: page = urllib.urlopen(url) # urllib.ur ...
- Python人工智能之图片识别,Python3一行代码实现图片文字识别
1.Python人工智能之图片识别,Python3一行代码实现图片文字识别 2.tesseract-ocr安装包和中文语言包 注意:
- python基于百度AI开发文字识别
很多场景都会用到文字识别,比如app或者网站里都会上传身份证等证件以及财务系统识别报销证件等等 第一步,你需要去百度AI里去注册一个账号,然后新建一个文字识别的应用 然后你将得到一个API Key 和 ...
- python实现百度OCR图片识别
一.直接上代码 import base64 import requests class CodeDemo: def __init__(self,AK,SK,code_url,img_path): se ...
- Python实现图片识别加翻译【高薪必学】
Python使用百度AI接口实现图片识别加翻译 另外很多人在学习Python的过程中,往往因为没有好的教程或者没人指导从而导致自己容易放弃,为此我建了个Python交流.裙 :一久武其而而流一思(数字 ...
随机推荐
- Redis工具类,不用框架时备用
redis.hostName=127.0.0.1 redis.port=6379 redis.database=3 redis.timeout=15000 redis.usePool=true red ...
- 向量数据库Chroma学习记录
一 简介 Chroma是一款AI开源向量数据库,用于快速构建基于LLM的应用,支持Python和Javascript语言.具备轻量化.快速安装等特点,可与Langchain.LlamaIndex等知名 ...
- Oracle邮件发送(内容中带有收件人独有信息)
Oracle邮件发送(内容中带有收件人独有信息) Oracle邮件发送(内容中带有收件人独有信息) Oracle发送邮件最简单的应该就是用smtp,具体使用和参数讲解我这儿没有 简单来说,发送邮件的思 ...
- PolarDB-X 高可用存储服务: 基于 X-Paxos 一致性协议
简介: 摘自刘永平(慕少)阿里云 PolarDB-X 技术专家在PolarDB-X | 新品发布会中的讲解内容. 了解更多PolarDB-X 内容:https://developer.aliyun.c ...
- 龙蜥开源内核追踪利器 Surftrace:协议包解析效率提升 10 倍! | 龙蜥技术
简介:如何将网络报文与内核协议栈清晰关联起来精准追踪到关注的报文行进路径呢? 文/系统运维 SIG Surftrace 是由系统运维 SIG 推出的一个 ftrace 封装器和开发编译平台,让用 ...
- 最佳实践丨构建云上私有池(虚拟IDC)的5种方案详解
简介:云上私有池系列终篇终于来了,本文将重点介绍构建云上的私有池(虚拟IDC)的多种方案和各自的优缺点,并给出相关的性价比优化建议. 本文作者:阿里云技术专家李雨前 摘要 围绕私有池(虚拟IDC)的 ...
- 从操作系统层面分析Java IO演进之路
简介: 本文从操作系统实际调用角度(以CentOS Linux release 7.5操作系统为示例),力求追根溯源看IO的每一步操作到底发生了什么. 作者 | 道坚来源 | 阿里技术公众号 前言 本 ...
- 16.prometheus监控总结
一.监控流程总结 1.需要在被监控的服务器上安装xx_exporter来收集数据(可以是源码安装,最好用docker.docker-compose) 2.添加Prometheus配置,去收集(xx_e ...
- python入门_模块2
0.collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque.defaultdic ...
- 关于Web的欢迎页面的开发设置
关于Web的欢迎页面的开发设置 每博一文案 命运总是不如人愿.但往往是在无数的痛苦中,在重重的矛盾和艰辛中,才是人成熟起来. 一次邂逅,一次目光的交融,就是永远的合二为一,就是与上帝的契约:总是风暴雷 ...