[转帖]SQL Server高级进阶之索引碎片维护
https://www.cnblogs.com/atomy/p/15268589.html
一、产生原因及影响
索引是数据库引擎中针对表(有时候也针对视图)建立的特别数据结构,用来帮助查找和整理数据,它的重要性体现在能够使数据库引擎快速返回查询结果。当对索引所在的基础数据表进行增删改时,若存储的数据进行了不适当的跨页(SQL Server中存储的最小单位是页,页是不可再分的),就会导致索引碎片的产生。随着索引碎片的不断增多,查询响应时间就会变慢,性能也因此而下降。要解决这个问题,可以通过重新生成或重新组织索引来解决。
二、碎片分类
2.1、外部碎片
当索引页不在逻辑顺序上时就会产生外部碎片。索引创建时,索引键按照逻辑顺序放在一组索引页上。当新数据插入索引时,新的键可能放在存在的键之间。为了让新的键按照正确的顺序插入,可能会创建新的索引页来存储需要移动的那些存在的键。这些新的索引页通常物理上不会和那些被移动的键原来所在的页相邻。创建新页的过程会引起索引页偏离逻辑顺序。
2.2、内部碎片
当索引页没有用到最大量时就产生了内部碎片。虽然在一个有频繁数据插入的应用程序里这也许有帮助,然而设置一个fill factor(填充因子)会在索引页上留下空间,服务器内部碎片会导致索引尺寸增加,从而在返回需要的数据时要执行额外的读操作。这些额外的读操作会降低查询的性能。
三、维护方法
1、删除索引并重建。
2、使用DROP_EXISTING语句重建索引。
3、使用ALTER INDEX REBUILD重新生成索引。(推荐)
4、使用ALTER INDEX REORGANIZE重新组织索引。(推荐)
四、注意事项
| 碎片率 | 采用方法 |
| >30% | ALTER INDEX REBUILD WITH(ONLINE = ON) |
| >5% 且 <=30% | ALTER INDEX REORGANIZE |
重新生成索引可以联机执行,也可以脱机执行。
重新组织索引始终联机执行。这些值提供了一个大致指导原则,用于确定应在ALTER INDEX REORGANIZE和ALTER INDEX REBUILD之间进行切换的点。不过,实际值可能会随情况而变化,必须要通过试验来确定最适合您环境的阈值。
非常低的碎片级别(小于5%)不应通过这些命令来解决,因为删除如此少量的碎片所获得的收益始终远低于重新生成或重新组织索引的开销。
切记:所有索引碎片维护一定要在凌晨(非业务高峰期间)进行!!!
五、优化指导原则
5.1、如何知道是否发生了索引碎片?
在SQL Server数据库中,可以通过DBCC SHOWCONTIG WITH ALL_INDEXES或DBCC SHOWCONTIG(表ID或者表名) WITH ALL_INDEXES来检查索引碎片情况。

--方法一
--目标数据库
USE DB_NAME
--创建变量指定要查看的表
DECLARE @TABLE_ID INT
SET @TABLE_ID=OBJECT_ID('TABLE_NAME')
--执行
DBCC SHOWCONTIG(@TABLE_ID) WITH ALL_INDEXES --方法二
USE DB_NAME
DBCC SHOWCONTIG('TABLE_NAME') WITH ALL_INDEXES
5.2、索引碎片判断标准
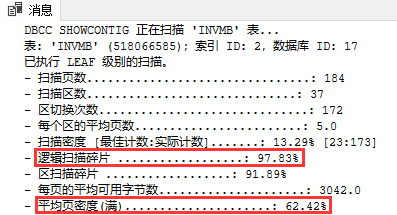
通过对逻辑扫描碎片(过高)、平均页密度(满)(过低)的结果分析,判定是否需要进行索引处理,如下所示:
逻辑扫描碎片 ..................:97.83% 该百分比应该在0%到10%之间,高了则说明有外部碎片。
平均页密度(满) ..................:62.42% 该百分比应该尽可能靠近100%,低了则说明有外部碎片。
六、优化实践
6.1、手动方式
第一步:查询数据库所有表的索引信息。
SELECT OBJECT_NAME(B.OBJECT_ID) 表名,B.NAME 索引名称,A.INDEX_TYPE_DESC 索引类型,
ROUND(A.AVG_FRAGMENTATION_IN_PERCENT,2) 碎片率
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) A
INNER JOIN sys.indexes B ON A.OBJECT_ID=B.OBJECT_ID AND A.INDEX_ID=B.INDEX_ID
WHERE 1=1
AND A.AVG_FRAGMENTATION_IN_PERCENT>30
--AND A.AVG_FRAGMENTATION_IN_PERCENT>5 AND A.AVG_FRAGMENTATION_IN_PERCENT<=30
ORDER BY OBJECT_NAME(B.OBJECT_ID),A.AVG_FRAGMENTATION_IN_PERCENT DESC
注:通过碎片率,依四、注意事项处理方式,也可以逐个对表的索引进行对应的重新生成或重新组织处理。
第二步:生成数据库所有表的索引处理的SQL语句。
SELECT OBJECT_SCHEMA_NAME(B.OBJECT_ID) 架构,OBJECT_NAME(B.OBJECT_ID) 表名,B.NAME 索引名,ROUND(A.AVG_FRAGMENTATION_IN_PERCENT,2) 碎片率,
CASE WHEN A.AVG_FRAGMENTATION_IN_PERCENT>30 THEN N'重新生成索引' ELSE N'重新组织索引' END 处理方式,
'ALTER INDEX '+QUOTENAME(B.NAME)+' ON '+QUOTENAME(OBJECT_SCHEMA_NAME(B.OBJECT_ID))+'.'+QUOTENAME(OBJECT_NAME(B.OBJECT_ID))+' '
+CASE WHEN A.AVG_FRAGMENTATION_IN_PERCENT>30 THEN 'REBUILD' ELSE 'REORGANIZE' END 生成SQL语句
FROM sys.dm_db_index_physical_stats(DB_ID(),NULL,NULL,NULL,NULL) A INNER JOIN sys.indexes B ON A.OBJECT_ID=B.OBJECT_ID AND A.INDEX_ID=B.INDEX_ID
WHERE A.AVG_FRAGMENTATION_IN_PERCENT>5 AND B.INDEX_ID>0
--AND OBJECT_NAME(B.OBJECT_ID) IN ('INVMB') --指定表
ORDER BY CASE WHEN A.AVG_FRAGMENTATION_IN_PERCENT>30 THEN N'重新生成索引' ELSE N'重新组织索引' END,OBJECT_NAME(B.OBJECT_ID),B.INDEX_ID
注:将【生成SQL语句】拷贝出来执行即可。
6.2、自动方式
第一步:在服务中启动SQL Server 代理。

第二步:点击"管理"->右键"维护计划"->"新建维护计划"。
第三步:起个名字,点击"确定"。
第四步:点击左侧"工具箱",将"重新生成索引"及"重新组织索引"拖至右边区域。

第五步:分别对着"重新生成索引"及"重新组织索引"点击右键->"编辑"->在"数据库"项勾选要处理的数据库->点击"确定"。
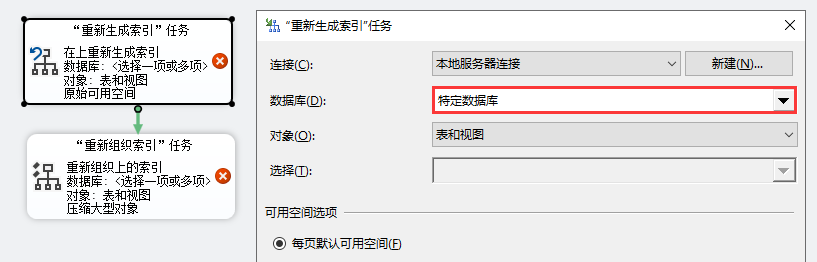
第六步:点击"新建作业计划"按钮->设置频率及执行时间->点击"确定"。

第七步:点击"保存选定项"即可。

七、更新统计信息
作用:UPDATE STATISTICS更新统计信息来提高查询效率。建议放在索引碎片计划任务执行完成之后进行。
查看:查看某个表的统计信息,可以在SSMS下面查看。
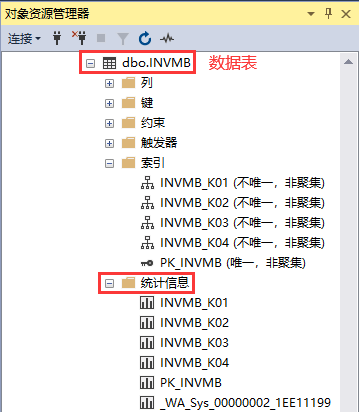
执行:
--方法一:UPDATE STATISTICS 表名
UPDATE STATISTICS INVMB --方法二:执行存储过程SP_UPDATESTATS(更新所有表)
EXEC sp_updatestats
后记:建议不要过于频繁地执行重新生成、重新组织索引以及更新统计信息。另外需要补充的是,非常低数据量与非常低碎片级别一样,通过这些命令来解决,效果甚微。
[转帖]SQL Server高级进阶之索引碎片维护的更多相关文章
- SQL SERVER 查询与整理索引碎片
重建索引 use DATABASE_NAME; ) ) DECLARE @fillfactor INT DECLARE TableCursor CURSOR FOR SELECT OBJECT_SCH ...
- mysql,sql server,oracle 唯一索引字段是否允许出现多个 null 值?
最近一个项目,涉及到sql server 2008,因为业务需求,希望建立一个唯一索引,但是发现在sql server中,唯一索引字段不能出现多个null值,下面是报错信息: CREATE UNIQU ...
- Sql Server专题一:索引(中)
写在前面的废话: 索引这个知识点,我前前后后不知道看了多少边,网上的文章五花八门,搞的我晕头转向,搞的牛逼点的就是测试索引带来的好处,还搞一大堆的测试数据出来,有意思吗?MS自己不会测试吗?这样的测试 ...
- [转帖]sql server版本特性简介、版本介绍简介
sql server版本特性简介.版本介绍简介 https://www.cnblogs.com/gered/p/10986240.html 目录 1.1.sql server的版本信息 1.2.版本重 ...
- SQL Server的非聚集索引中会存储NULL吗?
原文:SQL Server的非聚集索引中会存储NULL吗? SQL Server的非聚集索引中会存储NULL吗? 这是个很有意思的问题,下面通过如下的代码,来说明,到底会不会存储NULL. --1.建 ...
- SQL Server强制使用特定索引 、并行度、锁
SQL Server强制使用特定索引 .并行度 修改或删除数据前先备份,先备份,先备份(重要事情说三遍) 很多时候你或许为了测试.或许为了规避并发给你SQL带来的一些问题,常常需要强制指定目标sql选 ...
- [转帖]SQL Server 索引中include的魅力(具有包含性列的索引)
SQL Server 索引中include的魅力(具有包含性列的索引) http://www.cnblogs.com/gaizai/archive/2010/01/11/1644358.html 上个 ...
- SQL Server高级性能调优策略
论坛里经常有人问“我的数据库很慢,有什么办法提高速度呢?”.这是个古老的话题,又是常见的问题,也是DBA们最想解决的问题之一.我想就SQLServer调优大家一起论一论,如果可以的话尽量发表自己观点, ...
- SQL Server 2012 批量重建索引
关于索引的概念可以看看宋大牛的博客 T-SQL查询高级—SQL Server索引中的碎片和填充因子 整个数据库的索引很多,索引碎片多了,不可能一个个的去重建,都是重复性的工作,所以索性写了个存储过程, ...
- SQL Server性能调优--索引
序言 索引的概念 索引是什么 数据库中的索引类似于一本书的目录,在一本书中使用目录可以快速找到你想要的信息,而不需要读完全书.在数据库中,数据库程序使用索引可以快速查询到表中的数据,而不必扫描整个表. ...
随机推荐
- WPF通用权限平台系统,正在研发中(基本于:VS2019 WPF+WebAPI(.NET 6.0)+SqlSugar +SQLServer2014)
- 9 个让你的 Python 代码更快的小技巧
哈喽大家好,我是咸鱼 我们经常听到 "Python 太慢了","Python 性能不行"这样的观点.但是,只要掌握一些编程技巧,就能大幅提升 Python 的运 ...
- 从VMWare安装到Nginx配置
1.安装VMWare Workstation 16 player,Mac也可使用Parallels Desktop,自己有虚拟主机的跳过: 2.在虚拟机中,安装Centos7操作系统,使用Minima ...
- Word2Vec模型总结
1.Huffman树的构造 解析:给定n个权值作为n个叶子节点,构造一棵二叉树,若它的带权路径长度达到最小,则称这样的二叉树为最优二叉树,也称Huffman树.数的带权路径长度规定为所有叶子节点的带权 ...
- 8种ETL算法汇总大全!看完你就全明白了
摘要:ETL是将业务系统的数据经过抽取.清洗转换之后加载到数据仓库的过程,是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中 ...
- JDK1.6中String类的坑,快让我裂开了…
摘要:JVM优化的目标就是:尽可能让对象都在新生代里分配和回收,尽量别让太多对象频繁进入老年代,避免频繁对老年代进行垃圾回收,同时给系统充足的内存大小,避免新生代频繁的进行垃圾回收. 本文分享自华为云 ...
- 顶会VLDB'22论文解读:多元时序预测算法METRO
摘要:本文提出了一个端到端的MTS预测框架METRO.METRO的核心思想是利用多尺度动态图建模变量之间的依赖关系,考虑单尺度内信息传递和尺度间信息融合. 本文分享自华为云社区<VLDB'22 ...
- CANN 5.0黑科技解密 | 算力虚拟化,让AI算力“物尽其用”
摘要:算力虚拟化技术对消费者而言,可有效降低算力的使用成本,对于设备商或运营商而言,则可极大提升算力资源的利用率,降低设备运营成本. 为什么要做算力虚拟化 近年来,人工智能领域呈井喷式发展,算力就是生 ...
- 解析WeNet云端推理部署代码
摘要:WeNet是一款开源端到端ASR工具包,它与ESPnet等开源语音项目相比,最大的优势在于提供了从训练到部署的一整套工具链,使ASR服务的工业落地更加简单. 本文分享自华为云社区<WeNe ...
- JQuery 弹出模态窗口
index.html <!DOCTYPE html> <html> <head> <!-- Contact Form CSS files --> < ...