基于TensorFlow 2与PaddlePaddle 2预测泰坦尼克号旅客生存概率的比较
目录
AI框架经过大浪淘沙之后,目前真正能够完整用于生产、科研、学术的只剩下了谷歌、脸书、百度三家的框架,本文通过一个泰坦尼克号旅客生存概率预测的经典问题来比较分析一下TensorFlow2与Paddle2。
本项目完整内容已更新至GitHub,后续一些关于PaddlePaddle的项目也会陆续在此项目更新,链接:
为了保证对比的可靠,两者的网络结构、训练配置,激活函数等等都完全相同,只是用两个不同的框架来实现。
1,程序比较
首先给出TensorFlow的程序,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 4 18:36:21 2021 @author: Biao
"""
import numpy as np
import pandas as pd
pd.set_option('display.max_rows', None) # 显示DataFrame的所有行
from sklearn import preprocessing
import tensorflow as tf
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False def prepare_data(selected_data):
# 为缺失Age记灵境和彷设置为平均僮
age_mean_value = selected_data['Age'].mean()
selected_data.loc[:,'Age'] = selected_data.loc[:,'Age'].fillna(age_mean_value)
# 为缺失Fare记灵境究危
fare_mean_value = selected_data['Fare'].mean()
selected_data.loc[:,'Fare'] = selected_data.loc[:,'Fare'].fillna(fare_mean_value)
# 为缺失Embarked记灵境芫僮
selected_data.loc[:,'Embarked'] = selected_data.loc[:,'Embarked'].fillna('S') # sex字符串转痪为数字编码
selected_data.loc[:,'Sex'] = selected_data.loc[:,'Sex'].map({'female': 0, 'male': 1}).astype(int)
# 港口embarked团字母表示转唤为数字编码
selected_data.loc[:,'Embarked'] = selected_data.loc[:,'Embarked'].map({'C': 0, 'Q': 1, 'S': 2}).astype(int) # drop不改变原有的df中的数据,而是返回另一个DataFrame来存放删除后的数据,axis = 1 表示删除列
selected_df_data = selected_data.drop(['Name'], axis=1) # 转挽为ndarray数绢
ndarray_data = selected_df_data.values
# 后7叨悬特征列
features = ndarray_data[:, 1:]
# 第0列是标签列
label = ndarray_data[:, 0] # 特彶詹标淮化
minmax_scale = preprocessing.MinMaxScaler(feature_range=(0, 1))
norm_features = minmax_scale.fit_transform(features) return norm_features, label # 得到处理后的训练集
# 读取数据文件,结果为DataFrame格式
data_file_path = "./train.xlsx"
df_data = pd.read_excel(data_file_path)
# 筛选提取需要的待彶字段,去葆ticket, cabin等
selected_cols = ['Survived', 'Name', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
selected_df_data = df_data[selected_cols] # shuffle, 打刮数据顺序,通过Pandas的拙样函数sample实现frac为百分比
shuffled_df_data = selected_df_data.sample(frac=1)
x_train_data, y_train_data = prepare_data(selected_data = shuffled_df_data) # 得到处理后的测试集
data_file_path = "./train.xlsx"
df_data = pd.read_excel(data_file_path)
selected_cols = ['Survived', 'Name', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
selected_df_data = df_data[selected_cols]
shuffled_df_data = selected_df_data.sample(frac=1)
x_test_data, y_test_data = prepare_data(selected_data = shuffled_df_data) # 建立模型结构
# 建立Keras序判槐型
model = tf.keras.models.Sequential() # 加人第一厉,输入特徙数据是7见构可以厉i'nput_shape= (7, )
model.add(tf.keras.layers.Dense(units=64, input_dim=7, use_bias=True, kernel_initializer='uniform', bias_initializer='zeros',activation='relu'))
model.add(tf.keras.layers.Dense(units=32, activation='sigmoid'))
model.add(tf.keras.layers.Dense(units=1, activation='sigmoid'))
# 模型结构
model.summary()
# 模型设置
model.compile(optimizer=tf.keras.optimizers.Adam(0.0001), loss='binary_crossentropy', metrics=['accuracy'])
# 模型训练
train_history = model.fit(x=x_train_data, y=y_train_data, validation_split=0.2, epochs=500, batch_size=32, verbose=2)
# 训练过程的历史数据:字典模式存储
train_history.history.keys() # 模型训练过程可视化
def visu_train_history(train_history, train_metric, validation_metric):
plt.plot(train_history.history[train_metric])
plt.plot(train_history.history[validation_metric])
plt.title('Train History')
plt.ylabel(train_metric)
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show() visu_train_history(train_history, 'accuracy', 'val_accuracy')
visu_train_history(train_history, 'loss', 'val_loss') # 模型评估
evaluate_result = model.evaluate(x=x_test_data, y=y_test_data)
model_evaluate_names = model.metrics_names
evaluate_result
print('模型的评估结果为:名字{}数据{}'.format(model_evaluate_names,evaluate_result)) # 模型应用
# Jack和Rose的旅客信息
Jack_info = [0, 'Jack', 3, 'male', 23, 1, 0, 5.0000, 'S']
Rose_info = [1, 'Rose', 1, 'female', 20, 1, 0, 100.0000, 'S']
# 测试信息
file_path = "./train.xlsx"
primary_data = pd.read_excel(file_path)
selected_primary_data = primary_data[selected_cols]
shuffled_primary_data = selected_primary_data.sample(frac=1)
new_test = pd.DataFrame([Jack_info, Rose_info],columns=selected_cols)
new_test_data = shuffled_primary_data.append(new_test)
x_verify_data, y_verify_data = prepare_data(selected_data = new_test_data)
Survival_probability = model.predict(x_verify_data)
print('Jack与Rose的生存概率分别为{},{}'.format(Survival_probability[891,0],Survival_probability[892,0]))
PadlePaddle的程序如下:
import paddle
from paddle.nn import Linear
import paddle.nn.functional as F
import numpy as np
from sklearn import preprocessing
import pandas as pd
import matplotlib.pyplot as plt def prepare_data(selected_data):
# 为缺失Age记灵境和彷设置为平均僮
age_mean_value = selected_data['Age'].mean()
selected_data.loc[:,'Age'] = selected_data.loc[:,'Age'].fillna(age_mean_value)
# 为缺失Fare记灵境究危
fare_mean_value = selected_data['Fare'].mean()
selected_data.loc[:,'Fare'] = selected_data.loc[:,'Fare'].fillna(fare_mean_value)
# 为缺失Embarked记灵境芫僮
selected_data.loc[:,'Embarked'] = selected_data.loc[:,'Embarked'].fillna('S') # sex字符串转痪为数字编码
selected_data.loc[:,'Sex'] = selected_data.loc[:,'Sex'].map({'female': 0, 'male': 1}).astype(int)
# 港口embarked团字母表示转唤为数字编码
selected_data.loc[:,'Embarked'] = selected_data.loc[:,'Embarked'].map({'C': 0, 'Q': 1, 'S': 2}).astype(int) # drop不改变原有的df中的数据,而是返回另一个DataFrame来存放删除后的数据,axis = 1 表示删除列
selected_df_data = selected_data.drop(['Name'], axis=1) # 转挽为ndarray数绢
ndarray_data = selected_df_data.values
ndarray_data = ndarray_data.astype(np.float32) # 必须由float64转化为float32
# 特彶詹标淮化
minmax_scale = preprocessing.MinMaxScaler(feature_range=(0, 1))
norm_ndarray_data = minmax_scale.fit_transform(ndarray_data) return norm_ndarray_data # 得到处理后的训练集
# 读取数据文件,结果为DataFrame格式
data_file_path = "./train.xlsx"
df_data = pd.read_excel(data_file_path)
# 筛选提取需要的待彶字段,去葆ticket, cabin等
selected_cols = ['Survived', 'Name', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
selected_df_data = df_data[selected_cols]
# shuffle, 打刮数据顺序,通过Pandas的拙样函数sample实现frac为百分比
shuffled_df_data = selected_df_data.sample(frac=1)
train_data = prepare_data(selected_data = shuffled_df_data) # 得到处理后的测试集
data_file_path = "./train.xlsx"
df_data = pd.read_excel(data_file_path)
selected_cols = ['Survived', 'Name', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
selected_df_data = df_data[selected_cols]
shuffled_df_data = selected_df_data.sample(frac=1)
test_data = prepare_data(selected_data = shuffled_df_data) # 加载数据
training_data, test_data = train_data, test_data class Regressor(paddle.nn.Layer):
# self代表类的实例自身
def __init__(self):
# 初始化父类中的一些参数
super(Regressor, self).__init__() # 定义一层全连接层,输入维度是13,输出维度是1
self.fc1 = Linear(in_features=7, out_features=64)
self.fc2 = Linear(in_features=64, out_features=32)
self.fc3 = Linear(in_features=32, out_features=1) # 网络的前向计算
def forward(self, inputs):
x = self.fc1(inputs)
x = F.relu(x)
x = self.fc2(x)
x = F.sigmoid(x)
x = self.fc3(x)
x = F.sigmoid(x)
return x # 声明定义好的线性回归模型
model = Regressor()
# 定义评估过程
def train(model):
paddle.set_device('gpu:0')
print('start training .......')
# 开启模型训练模式
model.train()
# 定义优化算法,使用随机梯度下降SGD
# 学习率设置为0.01
opt = paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters()) EPOCH_NUM = 300 # 设置外层循环次数
BATCH_SIZE = 32 # 设置batch大小
epoch = 0
epochs = []
train_losses = []
train_losses_set = []
# 定义外层循环
for epoch_id in range(EPOCH_NUM):
# 将训练数据进行拆分,每个batch包含10条数据
mini_batches = [training_data[k:k + BATCH_SIZE] for k in range(0, len(training_data), BATCH_SIZE)]
# 定义内层循环
for iter_id, mini_batch in enumerate(mini_batches):
x = mini_batch[:, 1:] # 后7叨悬特征列,二维数组
y = mini_batch[:, 0] # 第0列是标签列,一维数组
y = y.reshape(len(y),1) #最后一个批次可能不是BATCH_SIZE大小
# 将numpy数据转为飞桨动态图tensor形式
Survival_features = paddle.to_tensor(x)
Survival_probability = paddle.to_tensor(y)
# 前向计算
predicts = model(Survival_features) # 计算损失,采用二元交叉熵损失
loss = F.binary_cross_entropy(predicts, label=Survival_probability)
avg_loss = paddle.mean(loss)
train_losses.append(avg_loss.numpy())
if iter_id % 20 == 0:
print("epoch: {}, iter: {}, loss is: {}".format(epoch_id, iter_id, avg_loss.numpy())) # 反向传播
avg_loss.backward()
# 最小化loss,更新参数
opt.step()
# 清除梯度
opt.clear_grad() # 求平均精度
train_losses_mean = np.array(train_losses).mean()
train_losses_set.append(train_losses_mean)
epoch = epoch + 1
epochs.append(epoch) # 保存模型参数,文件名为LR_model.pdparams
paddle.save(model.state_dict(), 'LR_model.pdparams')
print("模型保存成功,模型参数保存在LR_model.pdparams中") return epochs, train_losses_set # 定义训练过程
def evaluation(model):
paddle.set_device('gpu:0')
print('start evaluation .......')
# 参数为保存模型参数的文件地址
model_dict = paddle.load('LR_model.pdparams')
model.load_dict(model_dict)
model.eval() BATCH_SIZE = 32 # 设置batch大小
# 在每轮迭代开始之前,将训练数据的顺序随机的打乱
np.random.shuffle(test_data)
# 将训练数据进行拆分,每个batch包含10条数据
mini_batches = [test_data[k:k + BATCH_SIZE] for k in range(0, len(test_data), BATCH_SIZE)]
# 定义内层循环
acc_set = []
avg_loss_set = []
for iter_id, mini_batch in enumerate(mini_batches):
x = mini_batch[:, 1:] # 后7叨悬特征列,二维数组
y = mini_batch[:, 0] # 第0列是标签列,一维数组
y = y.reshape(len(y),1) #最后一个批次可能不是BATCH_SIZE大小 y = y.astype(np.int64)
# 将numpy数据转为飞桨动态图tensor形式
Survival_features = paddle.to_tensor(x)
Survival_probability_int64 = paddle.to_tensor(y)
# 计算预测和精度
prediction = model(Survival_features)
acc = paddle.metric.accuracy(prediction, Survival_probability_int64)
# 计算损失,采用二元交叉熵损失
y = y.astype(np.float32)
Survival_probability_float32 = paddle.to_tensor(y)
loss = F.binary_cross_entropy(prediction, label=Survival_probability_float32)
avg_loss = paddle.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
# 求平均精度
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean() print('模型在测试集的评估结果为:loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean)) model = Regressor()
# 模型训练
Epochs, Train_loss = train(model)
# 模型评估
evaluation(model) # 画出训练过程中Loss的变化曲线
plt.figure()
plt.title("Train loss", fontsize=24)
plt.xlabel("Epochs", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(Epochs, Train_loss, color='red', label='train loss')
plt.grid()
plt.show() Jack_Rose = np.array(([0, 3, 1, 23, 1, 0, 5.0000, 2],[1, 1, 0, 20, 1, 0, 100.0000, 2]),dtype=np.float32)
verify_data = np.append(training_data,Jack_Rose,axis=0)
minmax_scale = preprocessing.MinMaxScaler(feature_range=(0, 1))
verify_data = minmax_scale.fit_transform(verify_data)
verify_data = verify_data[:, 1:]
verify_data = paddle.to_tensor(verify_data)
model = Regressor()
model_dict = paddle.load('LR_model.pdparams')
model.load_dict(model_dict)
model.eval()
Survival_prediction = model(verify_data)
Survival_prediction = np.array(Survival_prediction) # 将tensor格式转化为numpy格式
print('Jack与Rose的生存概率分别为{},{}'.format(Survival_prediction[891,0],Survival_prediction[892,0]))
2,训练过程对比:
TensorFlow的训练过程可视化如下:
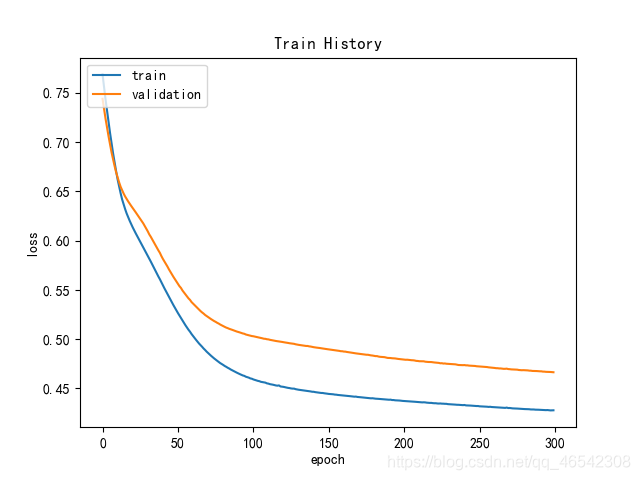
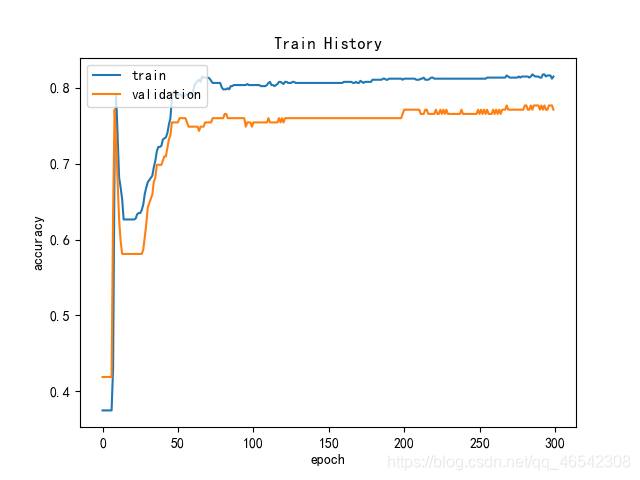

PaddlePaddle的训练过程可视化如下:
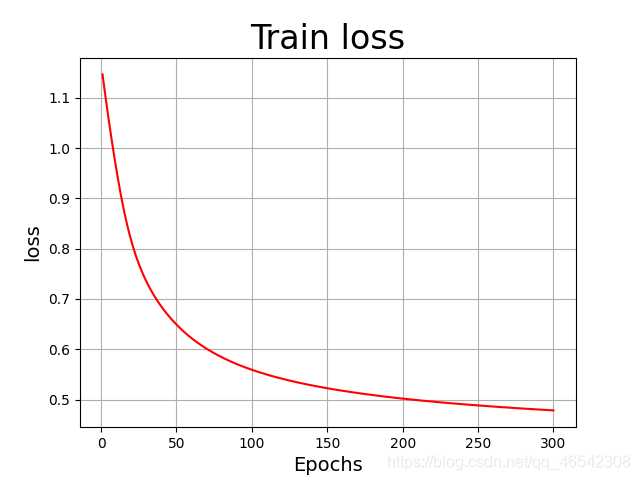
3,训练结果对比
TensorFlow对电影主角Jack与Rose的生存概率预测结果为:

PaddlePaddle对电影主角Jack与Rose的生存概率预测结果为:

对比二者的预测结果,都很符合实际的结果,只是对比而言, TensorFlow对Rose的生存概率预测的更加准确,而PaddlePaddle对Jack的生存概率预测的更加准确,二者各有千秋吧。
总的来说,PaddlePaddle与TensorFlow处在了同一水平,风格与PyTorch很像,也很值得尝试一下,在国内的支持也比TF与PyTorch要好。
注:本文的TensorFlow代码参考了浙大慕课,链接如下:
深度学习应用开发-TensorFlow实践_中国大学MOOC(慕课) (icourse163.org)
基于TensorFlow 2与PaddlePaddle 2预测泰坦尼克号旅客生存概率的比较的更多相关文章
- TensorFlow-Bitcoin-Robot:一个基于 TensorFlow LSTM 模型的 Bitcoin 价格预测机器人
简介 TensorFlow-Bitcoin-Robot:一个基于 TensorFlow LSTM 模型的 Bitcoin 价格预测机器人. 文章包括一下几个部分: 1.为什么要尝试做这个项目? 2.为 ...
- TensorFlow-Bitcoin-Robot:一个基于 TensorFlow LSTM 模型的 Bitcoin 价格预测机器人。
简介 TensorFlow-Bitcoin-Robot:一个基于 TensorFlow LSTM 模型的 Bitcoin 价格预测机器人. 文章包括一下几个部分: 1.为什么要尝试做这个项目? 2.为 ...
- 基于tensorflow的MNIST手写数字识别(二)--入门篇
http://www.jianshu.com/p/4195577585e6 基于tensorflow的MNIST手写字识别(一)--白话卷积神经网络模型 基于tensorflow的MNIST手写数字识 ...
- 基于TensorFlow解决手写数字识别的Softmax方法、多层卷积网络方法和前馈神经网络方法
一.基于TensorFlow的softmax回归模型解决手写字母识别问题 详细步骤如下: 1.加载MNIST数据: input_data.read_data_sets('MNIST_data',one ...
- 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(二)
前言 已完成数据预处理工作,具体参照: 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(一) 设置配置文件 新建目录face_faster_rcn ...
- 基于TensorFlow的MNIST手写数字识别-初级
一:MNIST数据集 下载地址 MNIST是一个包含很多手写数字图片的数据集,一共4个二进制压缩文件 分别是test set images,test set labels,training se ...
- 基于tensorflow的文本分类总结(数据集是复旦中文语料)
代码已上传到github:https://github.com/taishan1994/tensorflow-text-classification 往期精彩: 利用TfidfVectorizer进行 ...
- 基于Tensorflow + Opencv 实现CNN自定义图像分类
摘要:本篇文章主要通过Tensorflow+Opencv实现CNN自定义图像分类案例,它能解决我们现实论文或实践中的图像分类问题,并与机器学习的图像分类算法进行对比实验. 本文分享自华为云社区< ...
- 基于深度学习的建筑能耗预测01——Anaconda3-4.4.0+Tensorflow1.7+Python3.6+Pycharm安装
基于深度学习的建筑能耗预测-2021WS-02W 一,安装python及其环境的设置 (写python代码前,在电脑上安装相关必备的软件的过程称为环境搭建) · 完全可以先安装anaconda(会自带 ...
- FaceRank-人脸打分基于 TensorFlow 的 CNN 模型
FaceRank-人脸打分基于 TensorFlow 的 CNN 模型 隐私 因为隐私问题,训练图片集并不提供,稍微可能会放一些卡通图片. 数据集 130张 128*128 张网络图片,图片名: 1- ...
随机推荐
- 王道oj/problem21
网址:oj.lgwenda.problem/21 思路:先序遍历,中序遍历,后序遍历用递归实现:层序遍历用一个链队实现,出队一个元素,顺序入队他的左孩子和右孩子 代码: #define _CRT_SE ...
- Unity的BuildPlayerProcessor:深入解析与实用案例
Unity BuildPlayerProcessor Unity BuildPlayerProcessor是Unity引擎中的一个非常有用的功能,它可以让开发者在构建项目时自动执行一些操作.这个功能可 ...
- searchsploit用法
kali里面自带这个工具,用来搜索www.exploit-db.com上面的漏洞库,在由于是提前内置了数据库所以不联网也可以用. 使用之前先更新一下确保是最新的漏洞库 searchsploit --u ...
- 微信的 h5 支付和 jsapi 支付
目录 申请商户号 申请商户证书 设置APIv3密钥 下载 SDK 开发包 下载平台证书 关联 AppID 账号 开通 H5 支付 H5支付流程 开通 JSAPI 支付 JSAPI 支付流程 通用微信支 ...
- Ubuntu关机卡死解决办法
sync && sudo syncsudo shutdwon -h now
- 7、Mybatis之特殊SQL
7.1 创建接口.映射文件和测试类 ++++++++++++++++++++++++++分割线++++++++++++++++++++++++++ 注意namespace属性值为对应接口的全限定类名 ...
- 解放双手!ChatGPT助力编写JAVA框架
亲爱的Javaer们,在平时编码的过程中,你是否曾想过编写一个Java框架去为开发提效?但是要么编写框架时感觉无从下手,不知道从哪开始.要么有思路了后对某个功能实现的技术细节不了解,空有想法而无法实现 ...
- 发布策略:蓝绿部署、金丝雀发布(灰度发布)、AB测试、滚动发布、红黑部署的概念与区别
蓝绿发布(Blue-Green Deployment) 蓝绿发布提供了一种零宕机的部署方式.不停老版本,部署新版本进行测试,确认OK,将流量切到新版本,然后老版本同时也升级到新版本.始终有两个版本同时 ...
- iframe子窗口调用父窗口方法
//一个iframe页面调用另一个iframe页面的方法self.parent.frames["sort_bottom"].mapp($("#id").val( ...
- 使用GPU训练Pytorch模型
如何使用GPU训练Pytorch模型 这两天的深度学习实验真实让人头疼,传说中的"猫狗大战",对模型的训练用CPU的话9h起步,12h是常态,大学生哪耗得起,因此查找资料搭建了GP ...