利用python分析pdf数据,分析上市公司财报
import re
import os.path
import matplotlib
import matplotlib.pyplot as plt
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
from IPython.display import display, HTML
from pandas import DataFrame
# from adjustText import adjust_text # 解析PDF文本,并保存到TXT文件中
def parse(pdf_path):
TEXT = ''
fp = open(pdf_path, 'rb')
# 用文件对象创建一个PDF文档分析器
parser = PDFParser(fp)
# 创建一个PDF文档
doc = PDFDocument()
# 连接分析器,与文档对象
parser.set_document(doc)
doc.set_parser(parser) # 提供初始化密码,如果没有密码,就创建一个空的字符串
doc.initialize() # 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建PDF,资源管理器,来共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释其对象
interpreter = PDFPageInterpreter(rsrcmgr, device) # 循环遍历列表,每次处理一个page内容
# doc.get_pages() 获取page列表
startIndex = 0
isEnd = False for page in doc.get_pages():
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
# 想要获取文本就获得对象的text属性, for x in layout:
if(isinstance(x, LTTextBoxHorizontal)):
text = x.get_text()
if(text.find('公司简介和主要财务指标')) > 0:
startIndex += 1
if(startIndex == 2):
TEXT += text if(text.find('主要会计数据和财务指标')) > 0:
isEnd = True
if(isEnd):
break return TEXT dir_path = os.path.abspath('.') + '\\pdf_files'
files = os.listdir(dir_path)
# print(files) pdfList = []
for file in files:
pdf_path = dir_path + '\\' + file
pdfList.append(parse(pdf_path)) comInfoList = [] for pdf in pdfList:
comInfo = {}
r = r'(?<=股票简称)\s*[^\n]+'
comInfo['股票简称'] = re.findall(r, pdf)[0].strip() if re.search(r, pdf) else '' r = r'(?<=股票代码)\s*[^\n]+'
comInfo['股票代码'] = re.findall(r, pdf)[0].strip() if re.search(r, pdf) else '' r = r'(?<=公司的法定代表人)\s*[^\n]+'
comInfo['公司的法定代表人'] = re.findall(r, pdf)[0].strip() if re.search(r, pdf) else '' r = r'(?<=办公地址)\s*[^\n]+'
comInfo['办公地址'] = re.findall(r, pdf)[0].strip() if re.search(r, pdf) else '' r = r'(?<=公司国际互联网网址)\s*[^\n]+'
comInfo['公司网址'] = re.findall(r, pdf)[0].strip() if re.search(r, pdf) else '' r = r'(?<=电子信箱)\s*[^\n]+'
comInfo['电子信箱'] = re.findall(r, pdf)[0].strip() if re.search(r, pdf) else '' r = r'(?<=营业收入(元))\s*(([^\n]+\n){4})' m = re.findall(r, pdf)[0]
s = ''.join(m).replace(' ', '').split('\n') comInfo['2019年营业收入元'] = s[0]
comInfo['2018年营业收入元'] = s[1]
comInfo['2017年营业收入元'] = s[3] comInfoList.append(comInfo) # print(comInfoList)
data = {'股票简称': [], '股票代码': [], '公司的法定代表人': [], '办公地址': [], '公司网址': [], '电子信箱': []}
data2 = {'股票简称': [], '股票代码': [], '2019': [], '2018': [], '2017': []} for comInfo in comInfoList:
data['股票简称'].append(comInfo['股票简称'])
data['股票代码'].append(comInfo['股票代码'])
data['公司的法定代表人'].append(comInfo['公司的法定代表人'])
data['办公地址'].append(comInfo['办公地址'])
data['公司网址'].append(comInfo['公司网址'])
data['电子信箱'].append(comInfo['电子信箱']) data2['股票简称'].append(comInfo['股票简称'])
data2['股票代码'].append(comInfo['股票代码'])
data2['2019'].append(comInfo['2019年营业收入元'])
data2['2018'].append(comInfo['2018年营业收入元'])
data2['2017'].append(comInfo['2017年营业收入元']) print('1. 提取:股票简称、股票代码、公司的法定代表人、办公地址、公司网址、电子信箱')
df = DataFrame(data)
display(HTML(df.to_html())) print('2. 提取:主要会计数据和财务指标——第01-10位:最近三年营业收入(元)')
df2 = DataFrame(data2)
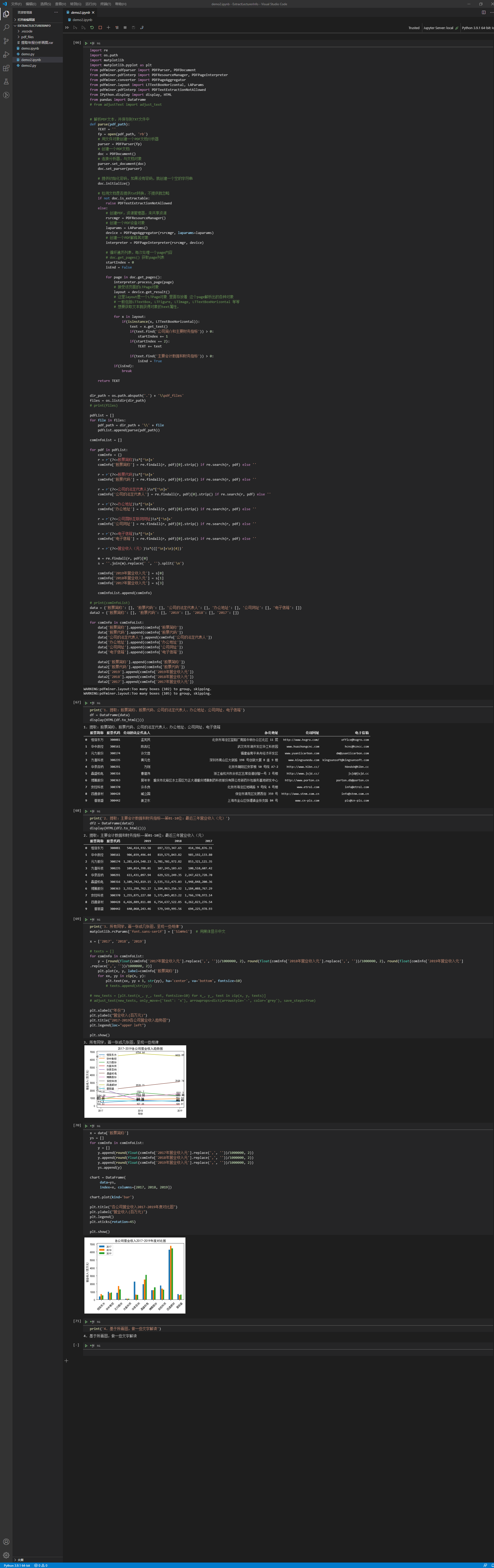
display(HTML(df2.to_html())) print('3. 所有同学,画一张或几张图,呈现一些规律')
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 用黑体显示中文 x = ['2017', '2018', '2019'] # texts = []
for comInfo in comInfoList:
y = [round(float(comInfo['2017年营业收入元'].replace(',', ''))/1000000, 2), round(float(comInfo['2018年营业收入元'].replace(',', ''))/1000000, 2), round(float(comInfo['2019年营业收入元'].replace(',', ''))/1000000, 2)]
plt.plot(x, y, label=comInfo['股票简称'])
for xx, yy in zip(x, y):
plt.text(xx, yy + 1, str(yy), ha='center', va='bottom', fontsize=10)
# texts.append(str(yy)) # new_texts = [plt.text(x_, y_, text, fontsize=10) for x_, y_, text in zip(x, y, texts)]
# adjust_text(new_texts, only_move={'text': 'x'}, arrowprops=dict(arrowstyle='-', color='grey'), save_steps=True) plt.xlabel("年份")
plt.ylabel("营业收入(百万元)")
plt.title("2017-2019各公司营业收入趋势图")
plt.legend(loc="upper left") plt.show() x = data['股票简称']
ys = []
for comInfo in comInfoList:
y = []
y.append(round(float(comInfo['2017年营业收入元'].replace(',', ''))/1000000, 2))
y.append(round(float(comInfo['2018年营业收入元'].replace(',', ''))/1000000, 2))
y.append(round(float(comInfo['2019年营业收入元'].replace(',', ''))/1000000, 2))
ys.append(y) chart = DataFrame(
data=ys,
index=x, columns=[2017, 2018, 2019]) chart.plot(kind='bar') plt.title("各公司营业收入2017-2019年度对比图")
plt.ylabel("营业收入(百万元)")
plt.legend()
plt.xticks(rotation=45) plt.show() print('4. 基于所画图,做一些文字解读')
利用python分析pdf数据,分析上市公司财报的更多相关文章
- 利用python将excel数据解析成json格式
利用python将excel数据解析成json格式 转成json方便项目中用post请求推送数据自定义数据,也方便测试: import xlrdimport jsonimport requests d ...
- 利用python进行微信好友分析
欢迎python爱好者加入:学习交流群 667279387 本文主要利用python对个人微信好友进行分析并把结果输出到一个html文档当中,主要用到的python包为itchat,pandas,py ...
- 利用Python读取外部数据文件
不论是数据分析,数据可视化,还是数据挖掘,一切的一切全都是以数据作为最基础的元素.利用Python进行数据分析,同样最重要的一步就是如何将数据导入到Python中,然后才可以实现后面的数据分析.数 ...
- 利用python设计PDF报告,jinja2,whtmltopdf,matplotlib,pandas
转自:https://foofish.net/python-crawler-html2pdf.html 工具准备 弄清楚了网站的基本结构后就可以开始准备爬虫所依赖的工具包了.requests.beau ...
- 利用Python将PDF文档转为MP3音频
1. 转语音工具 微信读书有一个功能,可以将书里的文字转换为音频,而且声音优化的不错,比传统的机械朗读听起来舒服很多. 记得之前看到过Python有一个工具包,可以将文字转换为语音,支持英文和中文,而 ...
- 利用Python进行数据分析——数据规整化:清理、转换、合并、重塑(七)(1)
数据分析和建模方面的大量编程工作都是用在数据准备上的:载入.清理.转换以及重塑.有时候,存放在文件或数据库中的数据并不能满足你的数据处理应用的要求.很多人都选择使用通用编程语言(如Python.Per ...
- 利用python基于微博数据打造一颗“心”
一年一度的虐狗节将至,朋友圈各种晒,晒自拍,晒娃,晒美食,秀恩爱的.程序员在晒什么,程序员在加班.但是礼物还是少不了的,送什么好?作为程序员,我准备了一份特别的礼物,用以往发的微博数据打造一颗&quo ...
- 利用python将excel数据导入mySQL
主要用到的库有xlrd和pymysql, 注意pymysql不支持python3 篇幅有限,只针对主要操作进行说明 连接数据库 首先pymysql需要连接数据库,我这里连接的是本地数据库(数据库叫ld ...
- 利用Python读取json数据并求数据平均值
要做的事情:一共十二个月的json数据(即12个json文件),json数据的一个单元如下所示.读取这些数据,并求取各个(100多个)城市年.季度平均值. { "time_point&quo ...
- 一例tornado框架下利用python panda对数据进行crud操作
get提交部分 <script> /* $("#postbtn").click(function () { $.ajax({ url:'/loaddata', data ...
随机推荐
- liquibase初始化sql
1.使用liquibase 集成依赖 <liquibase.version>4.1.1</liquibase.version> <dependency> <g ...
- 快速上手Linux核心命令(五):文本处理三剑客
@ 目录 前言 正则表达式 第一剑客 grep 第二剑客 sed 第三 剑客 awk 小结 剑仙镇楼~ O(∩_∩)O 前言 上一篇中已经预告,我们这篇主要说Linux文本处理三剑客.他们分别是gre ...
- windows下MinGW编译ffmpeg
windows下MinGW编译ffmpeg 1.官网下载MinGW并安装 1)下载 ,下载网址: https://sourceforge.net/projects/mingw/files/ ...
- 快速上手Linux核心命令(八):网络相关命令
目录 前言 测试主机之间网络是否联通 ifconfig 配置或显示网络信息 route 显示或管理路由表 netstat 查看网络状况 telnet 远程登录主机 ssh 安全的远程登录主机 wget ...
- 咚咚咚,你的王国之泪已上线「GitHub 热点速览」
本周最大的热点,莫过于 Mojo 语言了,几大媒体均有报道这门兼顾 Python 优点和性能的新语言.当然还有凭借 Switch 游戏<塞尔达传说·王国之泪>登上热榜,获得 3,500+ ...
- Node + Express 后台开发 —— 上传、下载和发布
上传.下载和发布 前面我们已经完成了数据库的增删改查,在弄一个上传图片.下载 csv,一个最简单的后台开发就已完成,最后部署即可. 上传图片 需求 需求:做一个个人简介的表单提交,有昵称.简介和头像. ...
- 2020-09-26:请问rust中的&和c++中的&有哪些区别?
福哥答案2020-09-26:#福大大架构师每日一题# 变量定义:c++是别名.rust是指针.取地址和按位与,c++和rust是相同的. c++测试代码如下: #include <iostre ...
- 2020-10-29:使用redis实现分布式限流组件,要求高并发场景同一IP一分钟内只能访问100次,超过限制返回异常,写出实现思路或伪代码均可。
福哥答案2020-10-29: 简单回答:固定窗口:string.key存ip,value存次数.滑动窗口:list.key存ip,value=list,存每次访问的时间. 中级回答:固定窗口:用re ...
- 2021-01-23:LFU手撸,说下时间复杂度和空间复杂度。
福哥答案2021-01-23:这道题复杂度太高,短时间内很难写出来.面试的时候不建议手撕代码.一个存节点的map+一个存桶的map+一个存桶的双向链表.桶本身也是一个双向链表.存节点的map:key是 ...
- 使用 MRKL 系统跨越神经符号鸿沟
本文展示了自然语言处理的下一步发展--模块化推理.知识和语言( the Modular Reasoning, Knowledge and Language,简称为MRKL)系统以及LangChain和 ...