【赵渝强老师】Kubernetes平台中日志收集方案

一、K8s整体日志收集方案
整体的日志收集方案,如下图所示:

- Filebeat是本地文件的日志数据采集器,可监控日志目录或特定日志文件(tail file),并将它们转发给Elasticsearch或Logstatsh进行索引、kafka等。带有内部模块(auditd,Apache,Nginx,System和MySQL),可通过一个指定命令来简化通用日志格式的收集,解析和可视化。
- ELK是Elasticsearch、Logstash、Kibana的简称,这三者是核心套件,但并非全部。
- Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上。
- Logstash是一个用来搜集、分析、过滤日志的工具。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch。
- Kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据。它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据
二、针对不同组件的日志收集
- Node上部署一个日志收集程序:DaemonSet方式部署日志收集程序。对本节点/var/log和/var/lib/docker/containers/ 两个目录下的日志进行采集.
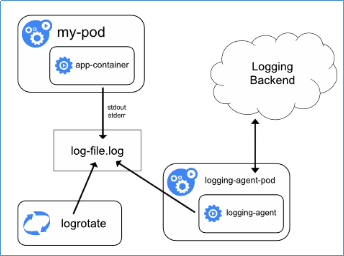
- Pod中附加专用日志收集的容器:每个运行应用程序的Pod中增加一个日志收集容器,使用emtyDir共享日志目录让日志收集程序读取到。
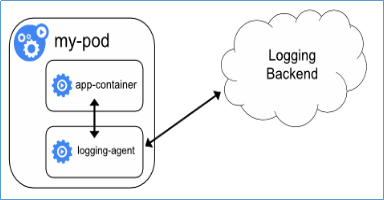
- 应用程序直接推送日志:不属于Kubernetes范围。

三、安装ELK
- 安装JDK:这里我们使用的是jdk-8u181-linux-x64.tar.gz(安装过程省去,非常简单)
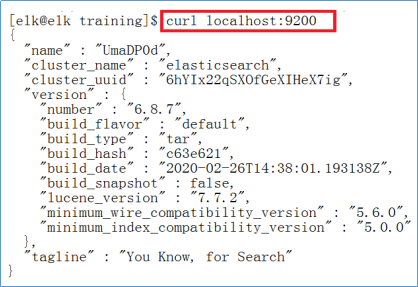
- 安装Elasticsearch:直接解压启动,即可,执行下面的语句测试ES。
- 安装Kibana:核心配置文件config/kibana.yml
server.port: 5601
server.host: "192.168.79.110"
elasticsearch.hosts: ["http://localhost:9200"] 启动:bin/kibana,访问Web Console:http://192.168.79.110:5601
- 安装logstash:核心配置文件config/logstash.conf
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "k8s-log-%{+YYYY-MM-dd}"
}
}
启动:bin/logstash -f config/logstash.conf
四、收集k8s组件日志
filebeat的配置文件filebeat.yml使用ConfigMap管理,k8s组件日志记录在node节点本机/var/log/messages目录下,所以将node节点/var/log/messages目录挂载到pod中。创建收集k8s 组件日志/var/log/messages资源。创建yaml文件如下:k8s-logs.yaml,并执行kubectl create -f k8s-logs.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: k8s-logs-filebeat-config
namespace: kube-system
data:
filebeat.yml: |-
filebeat.prospectors:
- type: log
paths:
- /messages
fields:
app: k8s
type: module
fields_under_root: true output.logstash:
hosts: ['192.168.79.110:5044'] --- apiVersion: apps/v1
kind: DaemonSet
metadata:
name: k8s-logs
namespace: kube-system
spec:
selector:
matchLabels:
project: k8s
app: filebeat
template:
metadata:
labels:
project: k8s
app: filebeat
spec:
containers:
- name: filebeat
image: collenzhao/filebeat:6.5.4
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 500Mi
securityContext:
runAsUser: 0
volumeMounts:
- name: filebeat-config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
- name: k8s-logs
mountPath: /messages
volumes:
- name: k8s-logs
hostPath:
path: /var/log/messages
type: File
- name: filebeat-config
configMap:
name: k8s-logs-filebeat-config
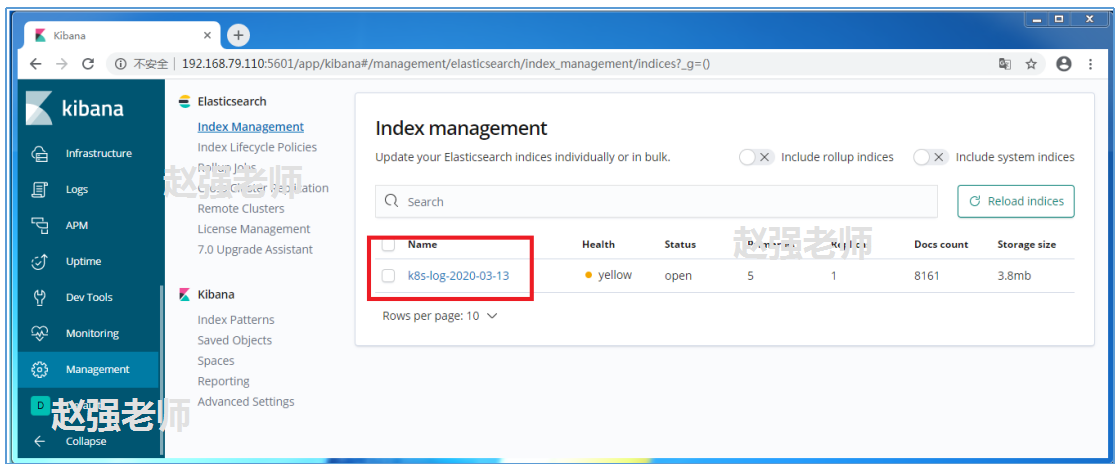
下图是Kibana的生成的信息。

【赵渝强老师】Kubernetes平台中日志收集方案的更多相关文章
- Kubernetes 平台中的日志收集
准备 关于容器日志 Docker 的日志分为两类,一类是 Docker 引擎日志:另一类是容器日志.引擎日志一般都交给了系统日志,不同的操作系统会放在不同的位置. 本文主要介绍容器日志,容器日志可以理 ...
- Kubernetes 常用日志收集方案
Kubernetes 常用日志收集方案 学习了 Kubernetes 集群中监控系统的搭建,除了对集群的监控报警之外,还有一项运维工作是非常重要的,那就是日志的收集. 介绍 应用程序和系统日志可以帮助 ...
- docker容器日志收集方案汇总评价总结
docker日志收集方案有太多,下面截图罗列docker官方给的日志收集方案(详细请转docker官方文档).很多方案都不适合我们下面的系列文章没有说. 经过以下5篇博客的叙述简单说下docker容器 ...
- k8s日志收集方案
k8s日志收集方案 三种收集方案的优缺点: 下面我们就实践第二种日志收集方案: 一.安装ELK 下面直接采用yum的方式安装ELK(源码包安装参考:https://www.cnblogs.com/De ...
- docker容器日志收集方案(方案N,其他中间件传输方案)
由于docker虚拟化的特殊性导致日志收集方案的多样性和复杂性下面接收几个可能的方案 这个方案各大公司都在用只不过传输方式大同小异 中间件使用kafka是肯定的,kafka的积压与吞吐能力相当强悍 ...
- golang日志收集方案之ELK
每个系统都有日志,当系统出现问题时,需要通过日志解决问题 当系统机器比较少时,登陆到服务器上查看即可满足 当系统机器规模巨大,登陆到机器上查看几乎不现实 当然即使是机器规模不大,一个系统通常也会涉及到 ...
- 轻量级日志收集方案Loki
先看看结果有多轻量吧 官方文档:https://grafana.com/docs/loki/latest/ 简介 Grafana Loki 是一个日志聚合工具,它是功能齐全的日志堆栈的核心. Loki ...
- docker容器日志收集方案(方案四,目前使用的方案)
先看数据流图,然后一一给大家解释 这个方案是将日志直接从应用代码中将日志输出到redis中(注意,是应用直接连接redis进行日志输出),redis充当一个缓存中间件有一定的缓存能力,不过有限,因 ...
- docker容器日志收集方案(方案二 filebeat+syslog本地日志收集)
与方案一一样都是把日志输出到本地文件系统使用filebeat进行扫描采集 不同的是输出的位置是不一样的 我们对docker进行如下设置 sudo docker service update --lo ...
- docker容器日志收集方案(方案一 filebeat+本地日志收集)
filebeat不用多说就是扫描本地磁盘日志文件,读取文件内容然后远程传输. docker容器日志默认记录方式为 json-file 就是将日志以json格式记录在磁盘上 格式如下: { " ...
随机推荐
- DASCTF 2023 & 0X401七月暑期挑战赛【PWN】(FileEditor篇)
DASCTF 2023 & 0X401七月暑期挑战赛[PWN](FileEditor篇) 题目保护情况(保护全家桶) 64位ida逆向 模拟了一个类似vim的功能,有打开文件,打印内容,插入行 ...
- 人工智能时代,前端全栈成就独立开发工程师 next.js 开发实战
next 可以服务端渲染,可以客户端渲染,让前端同事更有性价比,让我们做得可以更多 由于next.js 是基础于react 所以在正式学习next.js 之前我们了解一下react 什么叫模块 ,就 ...
- OneFlow计算框架的OneAgent是不是一个子虚乌有的东西?
自己是搞强化学习的,今天看了些OneFlow计算框架的一些资料,发现OneFlow官方一直有宣传自己的强化学习框架--OneAgent,但是十分诡异的是从了OneFlow的官方宣传可以看到这个词,但是 ...
- 内网穿透之实践记录,使用花生壳进行内外穿透,场景:在家远程ssh连接到公司电脑或学校服务器
今天在网上闲逛的时候看到这样一个内网穿透的软件,ngrok, https://gitee.com/kxwinxp/ngrok 记得10多年前自己在读大学的时候曾经好一段时间在研究内网穿透技术,最后发现 ...
- 推荐一款界面优雅、功能强大的 .NET + Vue 权限管理系统
前言 今天推荐一款用 .NET 和 Vue3 实现的开源权限管理系统.它的界面清爽干净,功能强大,还具备灵活的角色权限分配功能,能够满足不同规模企业的管理需求.无论你是开发新手还是大神,都能轻松上手, ...
- 解决Perforce lua文件utf-8 with bom
设置typemap,将lua文件定义为unicode
- 高级工程师面试大全- java基础篇
1.什么是java虚拟机 JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功 ...
- 存储过程中调用EXECUTE IMMEDIATE的“权限不足”
EXECUTE IMMEDIATE是Oracle中使用动态SQL的一种方法,可以直接执行,也可以在存储过程中调用.然而在存储过程中调用可能会遇到权限不足的问题,如在存储过程中执行重建索引语句: sql ...
- 记一次解决OTA死机重启bug,如何分析与解决措施?!
背景: 平台:stm32mp151平台 什么是OTA? 说起OTA我们应该都不陌生,它是一种可以为设备无损失升级系统的方式,能将新功能远程部署到产品上. 我们不仅可以通过网络下载OTA升级包,也可以通 ...
- Linux驱动小技巧 | 利用DRIVER_ATTR实现调用内核函数
1. 前言 很多朋友在调试驱动的时候,都会遇到这样一个场景: 修改一个参数,然后调用某个内核中的函数. 比如将某个gpio的值拉高/拉低,修改某个寄存器的值等等. 如果每一个参数都通过字符设备的ioc ...