docker容器日志收集方案(方案一 filebeat+本地日志收集)
filebeat不用多说就是扫描本地磁盘日志文件,读取文件内容然后远程传输。
docker容器日志默认记录方式为 json-file 就是将日志以json格式记录在磁盘上
格式如下:
"log": "2018-11-16 01:24:30.372 INFO [demo1,786a42d3b893168f,786a42d3b893168f,false] 1 --- [hystrix-test1-2] demo1.demo1.TestRest : 我收到了其他服务调用\n",
"stream": "stdout",
"time": "2018-11-16T01:24:30.37454385Z"
}

docker日志记录位置默认(centos7)为:
这个目录下面就是以各个容器命名的文件夹,文件夹下面就是日志如下图:
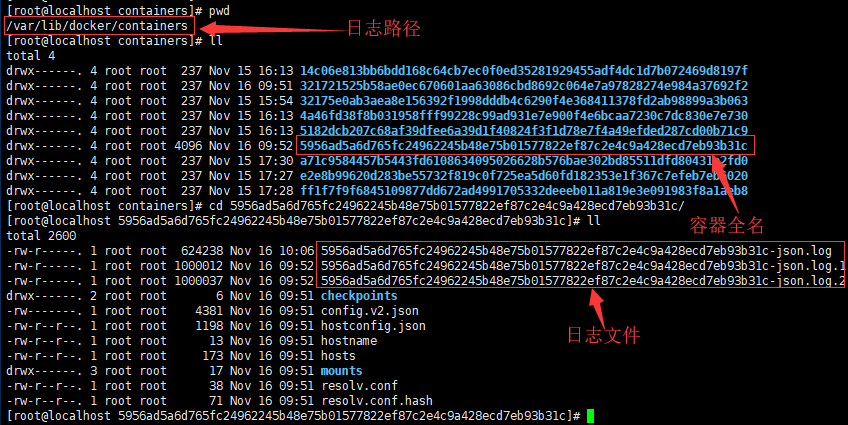
那这个时候我们针对每个容器进行参数设置就可以了,设置参数如下示例(这里只给出docker swarm集群的一个语句,单机可以看docker官网):
--log-driver 为日志驱动类型
--log-opt 为日志驱动参数,可以是多个具体可以查看docker官方文档(https://docs.docker-cn.com/engine/admin/logging/json-file/#usage)
--log-opt max-size=1m 设置日志文件每个大小
--log-opt max-file=3 设置日志文件最多几个
这样我们就可以设置filebeat进行目录扫描然后传输到ES(elasticsearch)搜索因引擎中。
不过很遗憾有个潜在的问题,这个参数里面没有按时间进行滚动删除日志文件的策略,所以上面的数字要设计好,以免还没有吧日志传输出去就被删掉的情况。
下面是所有配置参数(也可官方查看):

这个方案有一个麻烦的问题,每个文件夹代表一个容器,如果要区分索引的话就需要设置,或解析日志,多个容器副本在多个宿主机上运行,需要拿到对应的服务名称等关键字段。
如果大锅烩或一起全部收集可能会造成日志混乱,搜索排除条件增多,性能不佳等(ES服务器配置牛逼除外)
docker容器日志收集方案(方案一 filebeat+本地日志收集)的更多相关文章
- Docker容器内Mysql大小写敏感方案解决
Docker容器内Mysql大小写敏感方案解决 一.(lower_case_table_names)参数说明 二.Docker 部署 MySql 并修改为大小写不敏感 2.1直接在Docker启动的时 ...
- docker容器下tomcat 不向catalina.out输出日志解决以及支持中文字符集
docker容器下tomcat 不向catalina.out输出日志解决 去掉 & 符号,直接 使用 ENTRYPOINT ["/data/tomcat/bin/startup.sh ...
- docker容器日志收集方案汇总评价总结
docker日志收集方案有太多,下面截图罗列docker官方给的日志收集方案(详细请转docker官方文档).很多方案都不适合我们下面的系列文章没有说. 经过以下5篇博客的叙述简单说下docker容器 ...
- Docker容器日志清理方案
Docker容器在运行过程中会产生很多日志,久而久之,磁盘空间就被占满了,以下分享docker容器日志清理的几种方法 删除日志 在linux上,容器日志一般存放在 /var/lib/docker/co ...
- docker容器日志查看
日志分两类,一类是 Docker 引擎日志:另一类是 容器日志. Docker 引擎日志 Docker 引擎日志 一般是交给了 Upstart(Ubuntu 14.04) 或者 systemd (Ce ...
- 实时查看docker容器日志
实时查看docker容器日志 $ sudo docker logs -f -t --tail 行数 容器名 例:实时查看docker容器名为s12的最后10行日志 $ sudo docker logs ...
- 通过Filebeat把日志传入到Elasticsearch
学习的地方:配置文件中预先处理字段数据的用法 通过Filebeat把日志传入到Elasticsearch Elastic Stack被称之为ELK (Elasticsearch,Logstash an ...
- docker容器修改时区(java应用log信息与标准容器时间有八个小时时间差)
在docker容器中运行的java应用打出的日志时间和通过date -R方式获取的容器标准时间有八个小时时间差- 因为docker容器的原生时区为0时区,为了和国内时区保持一致,需要把容器时区调为东八 ...
- docker容器启动几分钟之后自动退出
2018-11-06 问题: docker容器启动几分钟之后自动退出 log日志报错 WARNING: overlay2: the backing xfs filesystem is formatte ...
随机推荐
- ES 02 - 部署Elasticsearch单机服务 + 部署中的常见问题
目录 1 准备工作 1.1 安装JDK 1.2 下载安装包 1.3 创建elastic用户 2 启动ES服务 2.1 修改配置文件 2.2 启动服务 3 验证ES服务是否可用 4 关闭与重启服务 4. ...
- 如何判断DataSet里有多少个DataTable
dataset.table.count sda.fill(ds,"table"); //这里是在ds里新建了一个表,叫table,注意是新建,多次执行会报错,实际使用时,可以用co ...
- CPU的load和使用率傻傻分不清
1. 什么是Cpu的Load 使用uptime.top或者查看/proc/loadavg都可以看到CPU的load统计,这里有三个值,分别代表1分钟.5分钟和15分钟的CPU Load情况.大部分人认 ...
- nodejs接收get参数和post参数
get请求用query //http://localhost:3000?a=3&b=4&c=5 router.get('/', function (req, res, next) { ...
- Spring Boot 2.x(七):优雅的处理异常
前言 异常的处理在我们的日常开发中是一个绕不过去的坎,在Spring Boot 项目中如何优雅的去处理异常,正是我们这一节课需要研究的方向. 异常的分类 在一个Spring Boot项目中,我们可以把 ...
- 小程序开发笔记【一】,查询用户参与活动列表 left join on的用法
今天在做一个用户活动查询功能的时候,查询参与的活动.正常,使用egg-mysql查询数据一般会这么写 result = await this.app.mysql.select('tb_activity ...
- C#实现以太仿DApp合约编译、部署
在网上找了一些关于C#开发以太仿的资料,大概了解了以太仿常用名词,后续可能需要根据资料查看开源的源码进一步熟悉一下. 一.准备合约 这里准备了一个EzToken.sol合约,目前还不会solidity ...
- 如何正确使用Java序列化?
前言 什么是序列化:将对象编码成一个字节流,这样一来就可以在通信中传递对象了.比如在一台虚拟机中被传递到另一台虚拟机中,或者字节流存储到磁盘上. “关于Java的序列化,无非就是简单的实现Serial ...
- YYModel底层解析- Runtime
这段时间一直在忙新的需求,没有时间来整理代码,发表自己技术博客,今天我们来看一下YYModel的底层解析以及如何使用,希望对大家有所帮助! 一 概述 概括 YYModel是一个轻量级的JSON模型转换 ...
- [转]Chrome 错误代码:ERR_UNSAFE_PORT
本文转自:https://blog.csdn.net/testcs_dn/article/details/39186225 最近在用Nginx发布多个站点测试,使用了87.88端口, 88端口访问正常 ...