聊聊Llama2-Chinese中文大模型
基本简述
Llama2-Chinese 大模型:由清华、交大以及浙大博士团队领衔开发;基于200B中文语料库结合Llama2基座模型训练。
Llama中文社区:国内最领先的开源大模型中文社区。
Atom大模型:为了区别于原始的Llama2模型,后续中文Llama2大模型,改名为Atom大模型。
模型获取地址:Huggingface
GITHUB地址:GITHUB
模型信息
Huggingface上Llama-Chinese大模型集合:
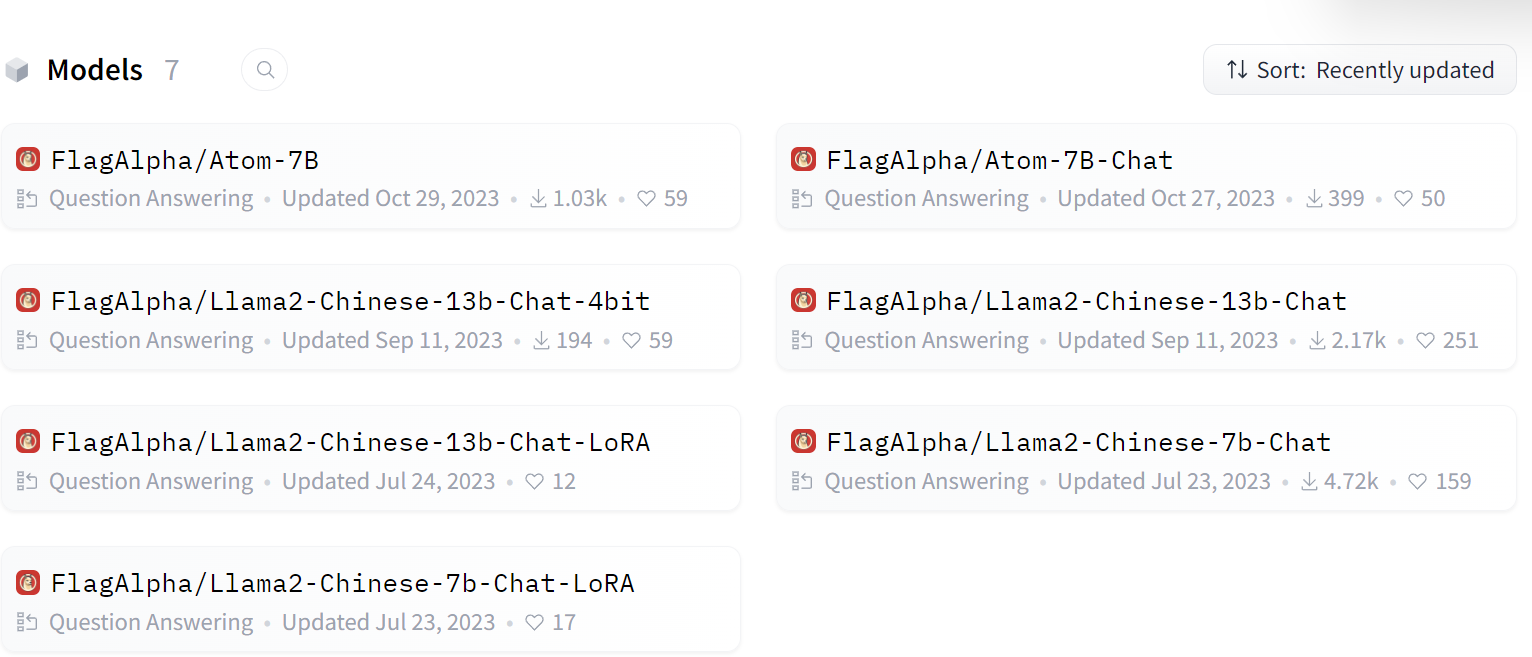
查看下Llama2-Chinese-7b-Chat模型的config.json:
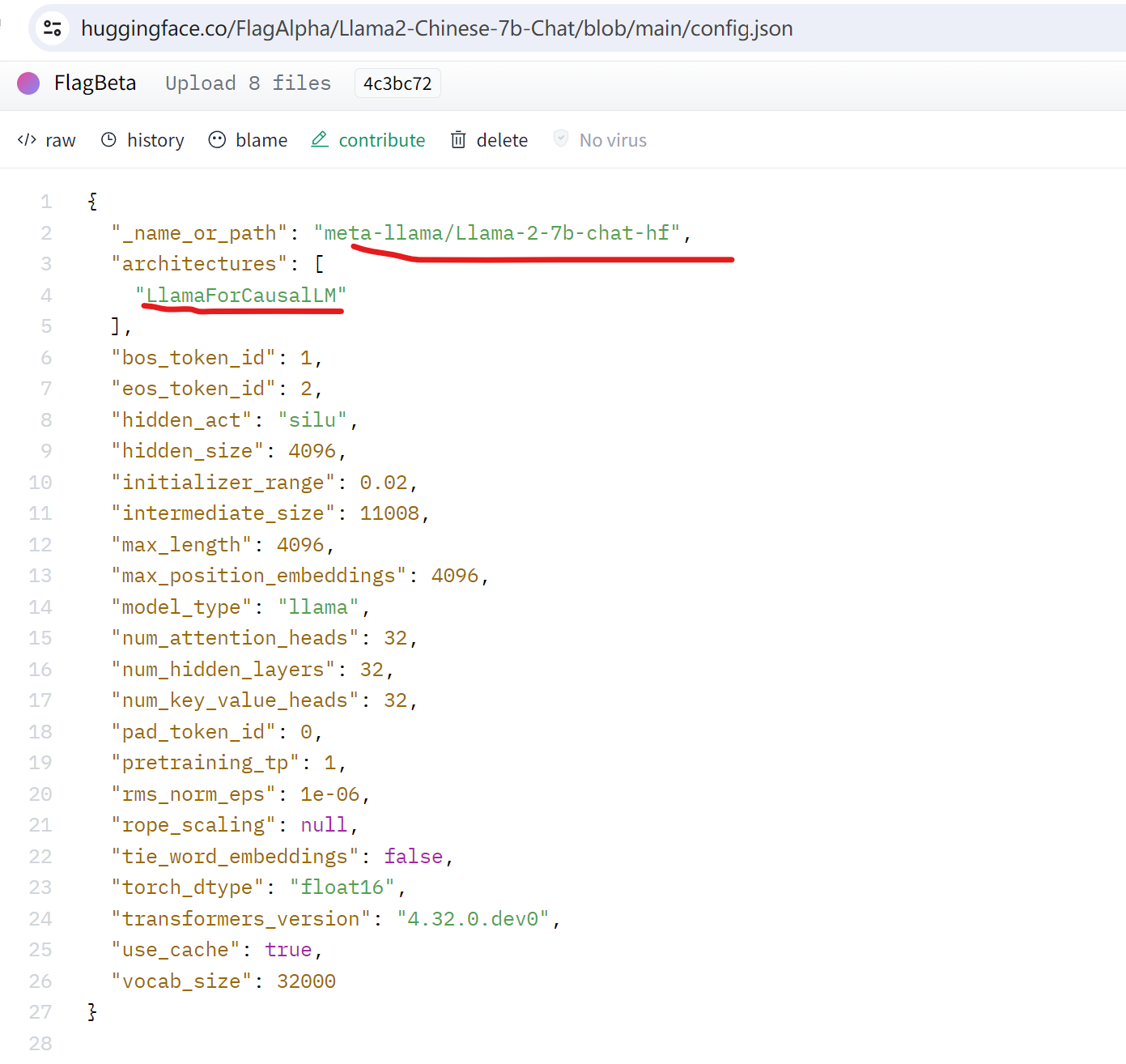
查看下Atom-7B-Chat的config.json:
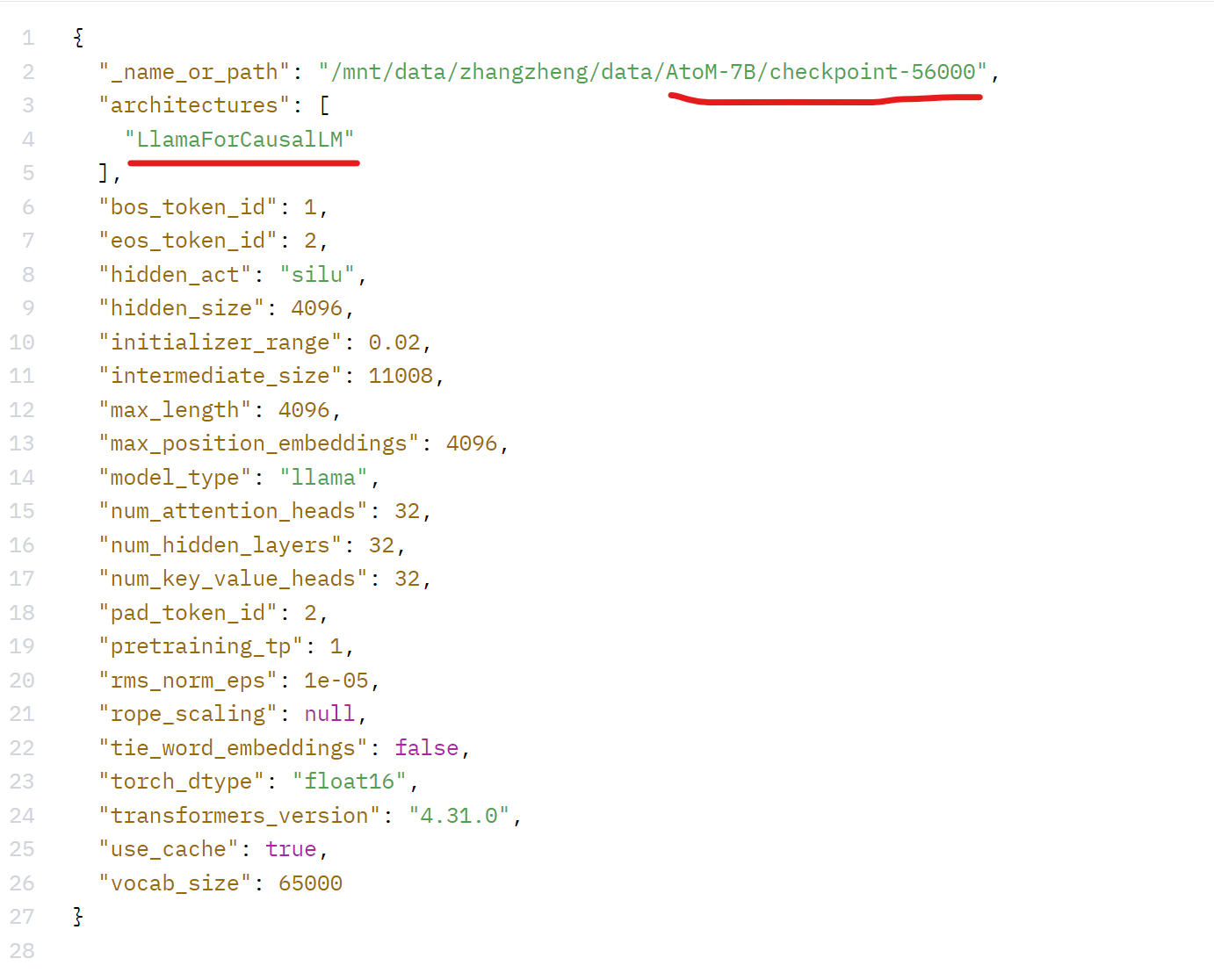
简单看看区别,官方说明:
- Atom模型:基于Llama2-7B采用大规模的中文数据进行了继续预训练。
- Llama2-Chinese:由于Llama2本身的中文对齐较弱,我们采用中文指令集,对meta-llama/Llama-2-7b-chat-hf进行LoRA微调,使其具备较强的中文对话能力。
总结来说,Atom模型时重新预训练的;而Llama2-Chinese模型是微调后的。因此如果想要比较完善更全面的中文模型,建议是用Atom模型。
调用说明
根据 官方文档 在命令行调用API:
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('meta-llama/Llama-2-7b-chat-hf',device_map='auto',torch_dtype=torch.float16,load_in_8bit=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('meta-llama/Llama-2-7b-chat-hf',use_fast=False)
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
分析来看,调用的是基于Llama2微调后的模型,而不是预训练的模型。暂时也没有看到Atom预训练模型调用的资料。在这里补一下:
# 转载请注明出处:https://www.cnblogs.com/zhiyong-ITNote
from transformers import AutoTokenizer, LlamaForCausalLM
model = LlamaForCausalLM.from_pretrained('mnt/data/zhangzheng/data/AtoM-7B/checkpoint-56000',device_map='auto',torch_dtype=torch.float16,load_in_8bit=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained('mnt/data/zhangzheng/data/AtoM-7B/checkpoint-56000',use_fast=False)
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
其实就是根据huggingface上的模型config.json文件的_name_or_path属性值重新配置模型名称即可。
LlamaForCausalLM
这个类是Llama2模型对接到transformers库的衔接类。由config.json的architectures属性值指定了。而且在官方文档有API说明.
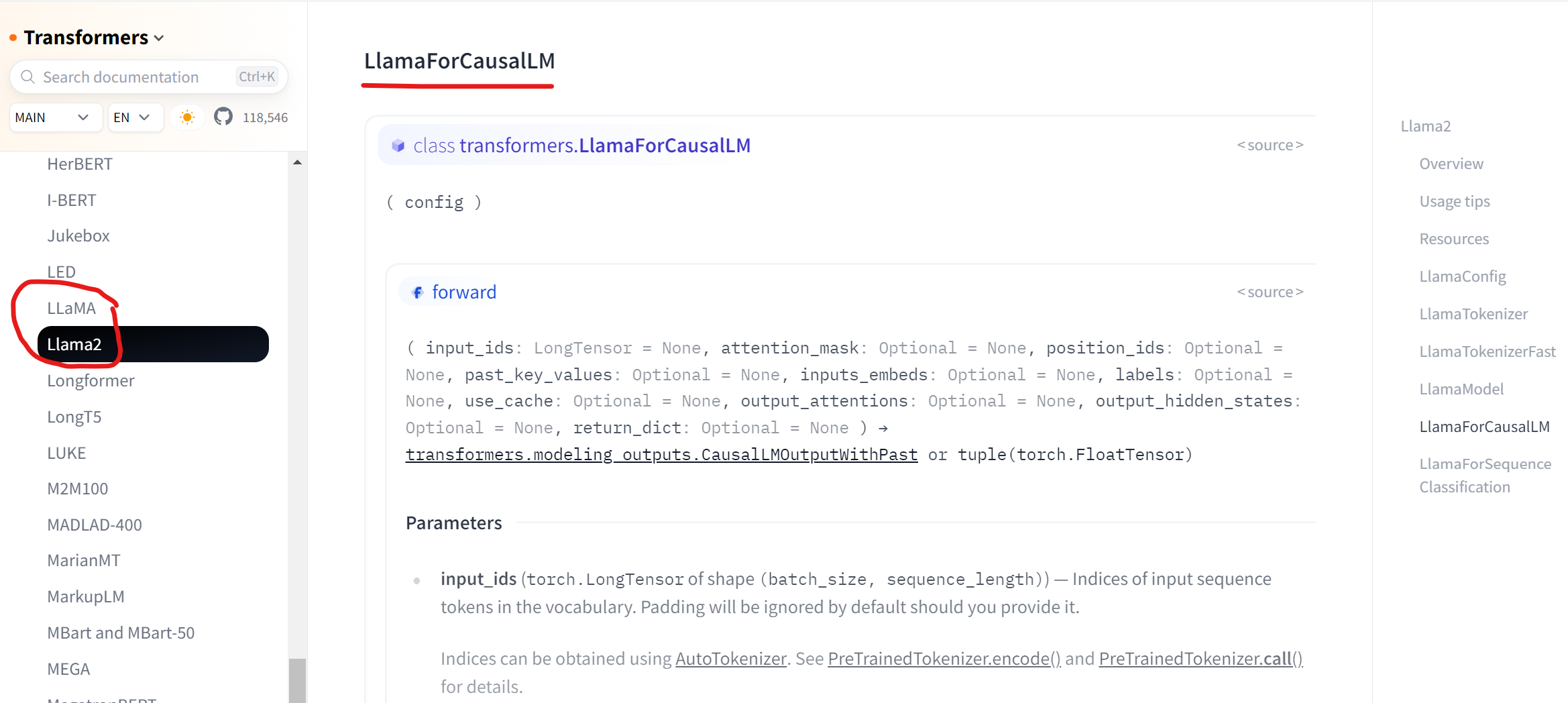
对应在github上的实现:
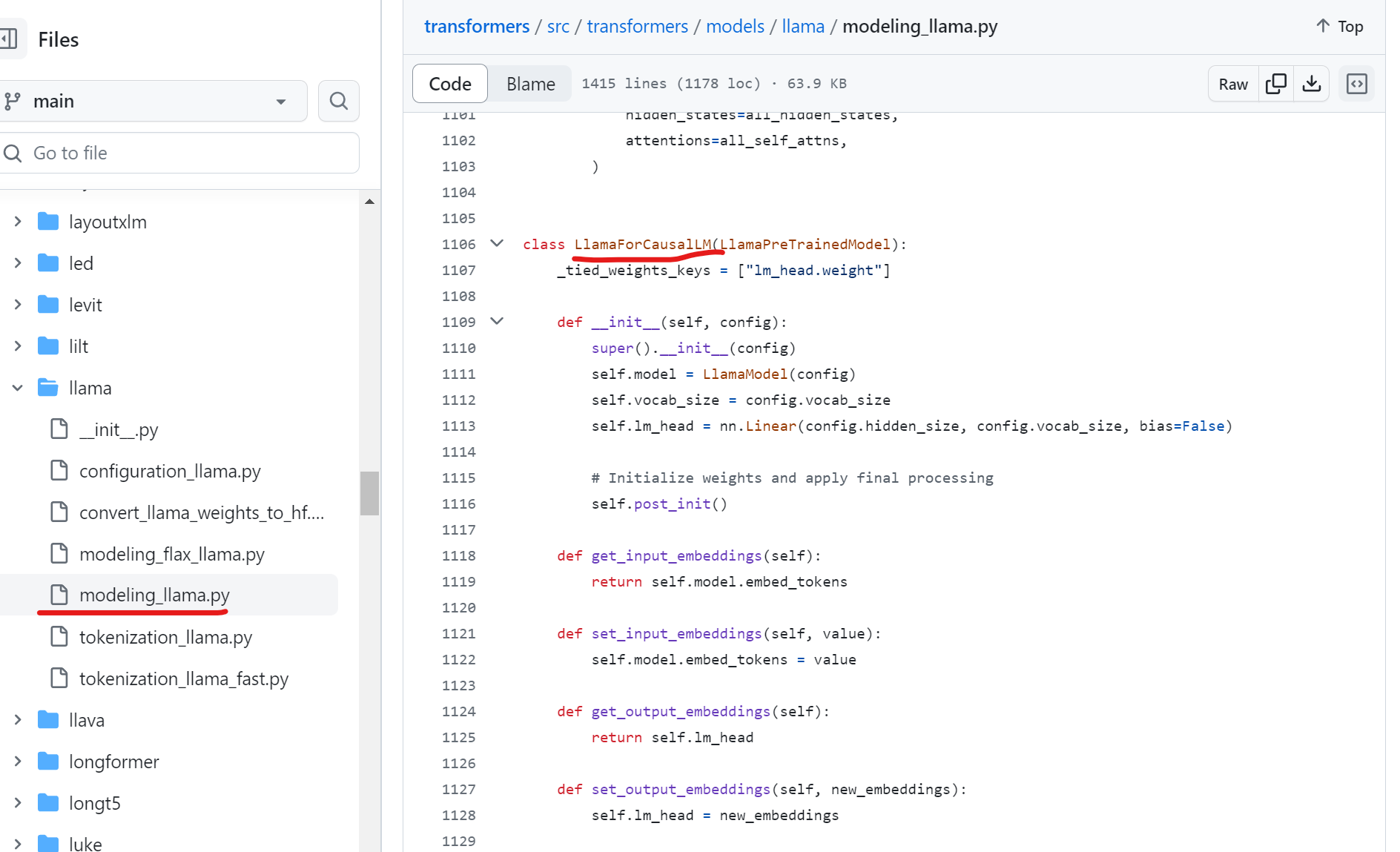
从之前ChatGLM-6B的源码结构分析来看,Llama2的关键源码也是这个llama文件夹下的这些文件,尤其是modeling_llama.py文件。
总结
从目前官方提供的文档等信息来看,资料还是比较少的,尤其是Atom模型的信息及示例等。这也需要我们在自身学习的过程中帮助社区不断地完善相关信息,反哺社区和中文大模型的发展。
聊聊Llama2-Chinese中文大模型的更多相关文章
- 无插件的大模型浏览器Autodesk Viewer开发培训-武汉-2014年8月28日 9:00 – 12:00
武汉附近的同学们有福了,这是全球第一次关于Autodesk viewer的教室培训. :) 你可能已经在各种场合听过或看过Autodesk最新推出的大模型浏览器,这是无需插件的浏览器模型,支持几十种数 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- AI大模型学习了解
# 百度文心 上线时间:2019年3月 官方介绍:https://wenxin.baidu.com/ 发布地点: 参考资料: 2600亿!全球最大中文单体模型鹏城-百度·文心发布 # 华为盘古 上线时 ...
- PowerDesigner 学习:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- PowerDesigner 15学习笔记:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- 文心大模型api使用
文心大模型api使用 首先,我们要获取硅谷社区的连个key 复制两个api备用 获取Access Token 获取access_token示例代码 之后就会输出 作文创作 作文创作:作文创作接口基于文 ...
- 千亿参数开源大模型 BLOOM 背后的技术
假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,"一朝看尽长安花"似乎近在眼前 -- 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- Familia:百度NLP开源的中文主题模型应用工具包
参考:Familia的Github项目地址.百度NLP专栏介绍 Familia 开源项目包含文档主题推断工具.语义匹配计算工具以及基于工业级语料训练的三种主题模型:Latent Dirichlet A ...
- 图神经网络之预训练大模型结合:ERNIESage在链接预测任务应用
1.ERNIESage运行实例介绍(1.8x版本) 本项目原链接:https://aistudio.baidu.com/aistudio/projectdetail/5097085?contribut ...
随机推荐
- 关于Word转PDF的几种实现方案
在.NET中,你可以使用Microsoft.Office.Interop.Word库来进行Word到PDF的转换.这是一个示例代码,但请注意这需要在你的系统上安装Microsoft Office. 在 ...
- Django框架项目之上线——docker、部署上线
文章目录 Docker CentOS安装Docker 设置管理Docker的仓库 安装Docker Engine-Community Docker基础命令 开启关闭 镜像操作 容器操作 Docker安 ...
- 算法修养--A*寻路算法
A*寻路算法 广度优先算法 广度优先算法搜索以广度做未优先级进行搜索. 从起点开始,首先遍历起点周围邻近的点,然后再遍历已经遍历过的点邻近的点,逐步的向外扩散,直到找到终点. 这种算法就像洪水(Flo ...
- 从零用VitePress搭建博客教程(4) – 如何自定义首页布局和主题样式修改?
接上一节:从零用VitePress搭建博客教程(3) - VitePress页脚.标题logo.最后更新时间等相关细节配置 六.首页样式修改 有时候觉得自带的样式不好看,想自定义,首先我们在docs/ ...
- PTA乙级1039(C++)散列表解法
题目 1039 到底买不买 小红想买些珠子做一串自己喜欢的珠串.卖珠子的摊主有很多串五颜六色的珠串,但是不肯把任何一串拆散了卖. 于是小红要你帮忙判断一下,某串珠子里是否包含了全部自己想要的珠子?如 ...
- webview是什么?作用是什么?和浏览器有什么关系?
Webview 是一个基于webkit的引擎,可以解析DOM 元素,展示html页面的控件,它和浏览器展示页面的原理是相同的,所以可以把它当做浏览器看待.(chrome浏览器也是基于webkit引擎开 ...
- 飞码LowCode前端技术:如何便捷配置出页面
简介 飞码是京东科技平台研发部研发的低代码产品,可使营销运营域下web页面快速搭建.本文将从三个方面来讲解如何便捷配置出页面,第一部分从数据.事件.业务支持三个方面进行分析,第二部分从模板与页面收藏与 ...
- 文心一言 VS 讯飞星火 VS chatgpt (128)-- 算法导论11.1 3题
三.用go语言,试说明如何实现一个直接寻址表,表中各元素的关键字不必都不相同,且各元素可以有卫星数据.所有三种字典操作(INSERT.DELETE和SEARCH)的运行时间应为O(1)(不要忘记 DE ...
- SHA256算法加密工具类
代码如下,请自取 /** * @description: SHA256算法加密 * @author: luolei * @Date: 2022-10-31 17:16 */ public class ...
- pbootcms 后台内容列表搜索功能扩展及增加显示字段功能
应项目要求,一个内容模型下栏目不宜分的层级过多,如新闻模块,分2022.2023.2024年度,每年度下分12个月,这样就是2层栏目,再依类别(科技.动漫.电影...)划分层级,栏目数量较多,而且不易 ...