CMU DLSys 课程笔记 2 - ML Refresher / Softmax Regression
CMU DLSys 课程笔记 2 - ML Refresher / Softmax Regression
这一节课是对机器学习内容的一个复习,以 Softmax Regression 为例讲解一个典型的有监督机器学习案例的整个流程以及其中的各种概念。预期读者应当对机器学习的基本概念有一定的了解。
目录
机器学习基础
针对于手写数字识别这一问题,传统的图像识别算法可能是首先找到每个数字的特征,然后手写规则来识别每个数字。这种方式的问题在于,当我们想要识别的对象的种类很多时,我们需要手动设计的规则就会变得非常复杂,而且这些规则很难设计得很好,因为我们很难找到一个完美的特征来区分所有的对象。
而机器学习方法则是让计算机自己学习如何区分这些对象,我们只需要给计算机一些数据,让它自己学习如何区分这些数据,这样的方法就可以很好地解决这个问题。
具体到有监督机器学习方法,我们需要给计算机一些数据,这些数据包含了我们想要识别的对象的一些特征,以及这些对象的标签,计算机需要从这些数据中学习到如何区分这些对象,如下图
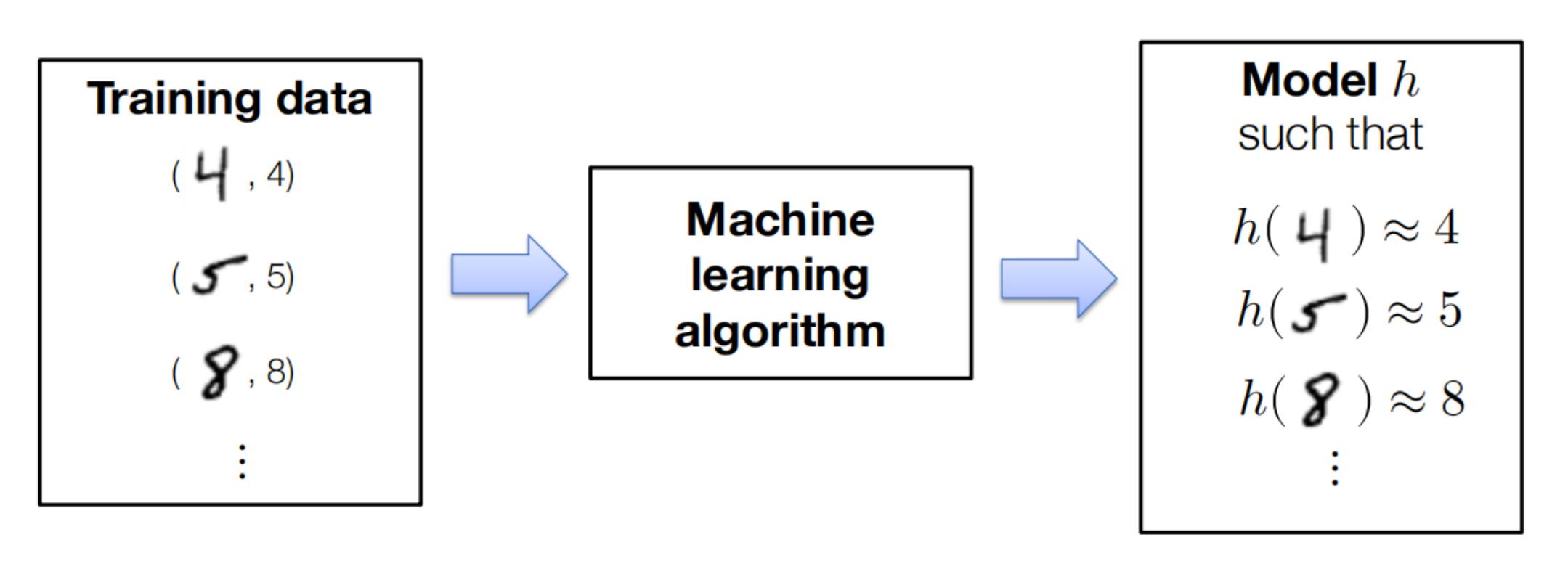
图里中间部分即为我们需要建立的机器学习模型,通常由以下内容组成:
- 模型假设:描述我们如何将输入(例如数字的图像)映射到输出(例如类别标签或不同类别标签的概率)的“程序结构”,通过一组参数进行参数化。
- 损失函数:指定给定假设(即参数选择)在所关注任务上的表现“好坏”的函数。
- 优化方法:确定一组参数(近似)最小化训练集上损失总和的过程。
Softmax Regression 案例
问题定义
让我们考虑一个 k 类分类问题,其中我们有:
- 训练数据:\(x^{(i)} \in \R^n\), \(y^{(i)} \in {1,\dots, k}\) for \(i = 1, … , m\)
- 其中 \(n\) 为输入数据的维度,\(m\) 为训练数据的数量,\(k\) 为分类类别的数量
- 针对 28x28 的 MNIST 数字进行分类,\(n = 28 \cdot 28 = 784\), \(k = 10\), \(m = 60,000\)
模型假设
我们的模型假设是一个线性模型,即
\]
其中 \(\theta \in \R^{n\times k}\) 是我们的模型参数,\(x \in \R^n\) 是输入数据。
机器学习中,经常使用的形式是多个输入叠加在一起的形式,即
\]
然后线性模型假设可以写为
\]
损失函数
最简单的损失函数就是根据是否预测正确,如
0 & \text { if } \operatorname{argmax}_{i} h_{i}(x)=y \\
1 & \text { otherwise }
\end{array}\right.
\]
我们经常用这个函数来评价分类器的质量。但是这个函数有一个重大的缺陷是非连续,因此我们无法使用梯度下降等优化方法来优化这个函数。
取而代之,我们会用一个连续的损失函数,即交叉熵损失函数
\]
\]
这个损失函数是连续的,而且是凸的,因此我们可以使用梯度下降等优化方法来优化这个损失函数。
优化方法
我们的目标是最小化损失函数,即
\]
我们使用梯度下降法来优化这个损失函数,针对函数\(f:\R^{n\times k} \rightarrow \R\),其梯度为
\]
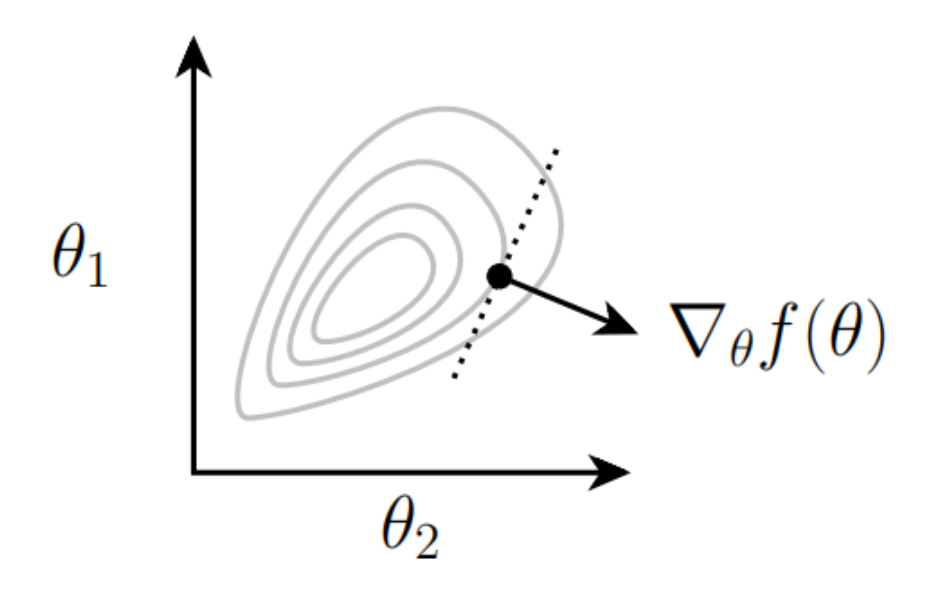
梯度的几何含义为函数在某一点的梯度是函数在该点上升最快的方向,如下图
我们可以使用梯度下降法来优化这个损失函数,即
\]
其中 \(\alpha \gt 0\) 为学习率,即每次更新的步长。学习率过大会导致无法收敛,学习率过小会导致收敛速度过慢。
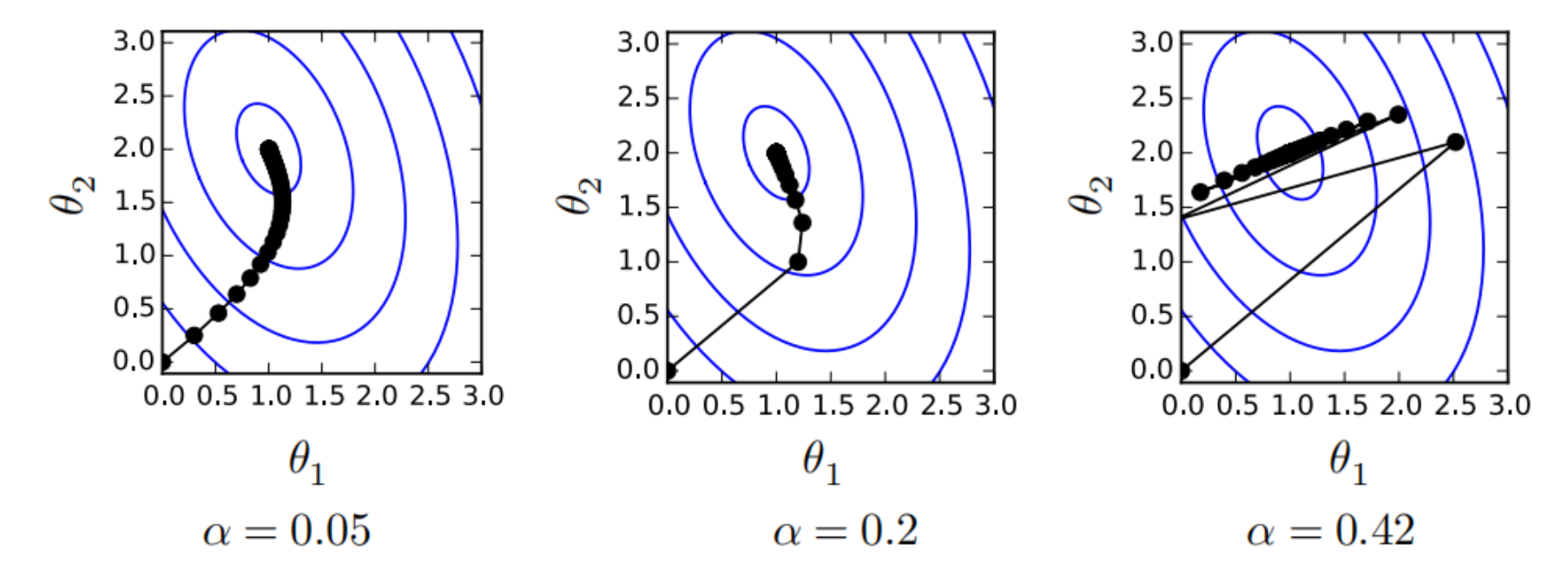
我们不需要针对每个样本都计算一次梯度,而是可以使用一个 batch 的样本来计算梯度,这样可以减少计算量,同时也可以减少梯度的方差,从而加快收敛速度,这种方法被称为随机梯度下降法(Stochastic Gradient Descent, SGD)。该方法的算法描述如下
\begin{array}{l}
\text { Repeat:} \\
\text { \quad Sample a batch of data } X \in \R^{B\times n}, y \in \{1, \dots, k\}^B \\
\text { \quad Update parameters } \theta \leftarrow \theta-\alpha \nabla_{\theta} \frac{1}{B} \sum_{i=1}^{B} \ell_{ce}\left(h_{\theta}\left(x^{(i)}\right), y^{(i)}\right)
\end{array}
\right.
\]
前面都是针对 SGD 的描述,但是损失函数的梯度还没有给出,我们一般使用链式法则进行计算,首先计算 softmax 函数本身的梯度
\]
写成矩阵形式即为
\]
然后计算损失函数对模型参数的梯度
\]
写成矩阵形式即为
\]
完整算法描述
最终算法描述为
\begin{array}{l}
\text { Repeat:} \\
\text { \quad Sample a batch of data } X \in \R^{B\times n}, y \in \{1, \dots, k\}^B \\
\text { \quad Update parameters } \theta \leftarrow \theta-\alpha X^T (\operatorname{softmax}(X\theta) - \mathbb{I}_y)
\end{array}
\right.
\]
以上就是完整的 Softmax Regression 的算法描述,最终在 hw0 中我们会实现这个算法,其分类错误率将低于 8 %。
CMU DLSys 课程笔记 2 - ML Refresher / Softmax Regression的更多相关文章
- 学习笔记TF024:TensorFlow实现Softmax Regression(回归)识别手写数字
TensorFlow实现Softmax Regression(回归)识别手写数字.MNIST(Mixed National Institute of Standards and Technology ...
- 斯坦福CS229机器学习课程笔记 Part1:线性回归 Linear Regression
机器学习三要素 机器学习的三要素为:模型.策略.算法. 模型:就是所要学习的条件概率分布或决策函数.线性回归模型 策略:按照什么样的准则学习或选择最优的模型.最小化均方误差,即所谓的 least-sq ...
- ML:吴恩达 机器学习 课程笔记(Week1~2)
吴恩达(Andrew Ng)机器学习课程:课程主页 由于博客编辑器有些不顺手,所有的课程笔记将全部以手写照片形式上传.有机会将在之后上传课程中各个ML算法实现的Octave版本. Linear Reg ...
- 深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing 2018-02-02 21:21:09 Paper: https://openreview.net/pdf ...
- 深度学习课程笔记(十一)初探 Capsule Network
深度学习课程笔记(十一)初探 Capsule Network 2018-02-01 15:58:52 一.先列出几个不错的 reference: 1. https://medium.com/ai% ...
- ng-深度学习-课程笔记-0: 概述
课程概述 这是一个专项课程(Specialization),包含5个独立的课程,学习这门课程后做了相关的笔记记录. (1) 神经网络和深度学习 (2) 改善深层神经网络:超参数调试,正则化,优化 ( ...
- CS231n课程笔记翻译9:卷积神经网络笔记
译者注:本文翻译自斯坦福CS231n课程笔记ConvNet notes,由课程教师Andrej Karpathy授权进行翻译.本篇教程由杜客和猴子翻译完成,堃堃和李艺颖进行校对修改. 原文如下 内容列 ...
- CS231n课程笔记翻译8:神经网络笔记 part3
译者注:本文智能单元首发,译自斯坦福CS231n课程笔记Neural Nets notes 3,课程教师Andrej Karpathy授权翻译.本篇教程由杜客翻译完成,堃堃和巩子嘉进行校对修改.译文含 ...
- CS231n课程笔记翻译7:神经网络笔记 part2
译者注:本文智能单元首发,译自斯坦福CS231n课程笔记Neural Nets notes 2,课程教师Andrej Karpathy授权翻译.本篇教程由杜客翻译完成,堃堃进行校对修改.译文含公式和代 ...
- CS231n课程笔记翻译6:神经网络笔记 part1
译者注:本文智能单元首发,译自斯坦福CS231n课程笔记Neural Nets notes 1,课程教师Andrej Karpathy授权翻译.本篇教程由杜客翻译完成,巩子嘉和堃堃进行校对修改.译文含 ...
随机推荐
- FreeSWITCH容器化问题之rtp端口占用
操作系统 :CentOS 7.6_x64.debian 11 (bullseye,docker) FreeSWITCH版本 :1.10.9 Docker版本:23.0.6 FreeSWITCH容器化带 ...
- c语言代码练习4
#define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h> #include <string.h> int main() { /* ...
- [GXYCTF 2019]BabyUpload
看到题目是一个文件上传 就先随便传的东西试试,看有什么过滤之类的 上传一个一句话木马,提示后缀名不能为ph 随便上传了带有一句话木马的图片,发现上传成功,但这个图片不能直接利用,要先上传一个.htac ...
- 一次考试的T3
啊这感觉不太可做观察性质,发现这个字符串只由ABC构成这个性质必须利用仅仅由3种字符组成意味着什么呢?这个字符串只有种可能性这个有什么用呢?只是说明暴力枚举的时间复杂度会小一些而已.不止是这些. 首先 ...
- 随身wifi 救砖过程记录
7,8块钱买了个随身wifi,准备刷机玩的,后来不知道刷错了boot还是啥,加电后灯都不亮了,前期没备份,于是网上找了各种教程,下面记录下: 变砖后有个底层的9008驱动协议可以刷机,下面的过程都是基 ...
- 【matplotlib 实战】--雷达图
雷达图(Radar Chart),也被称为蛛网图或星型图,是一种用于可视化多个变量之间关系的图表形式.雷达图是一种显示多变量数据的图形方法.通常从同一中心点开始等角度间隔地射出三个以上的轴,每个轴代表 ...
- JVM-JVM是如何执行方法调用的
重载.重写 void invoke(Object obj, Object... args) { ... } void invoke(String s, Object obj, Object... ar ...
- JUC并发编程学习笔记(十四)异步回调
异步回调 Future设计的初衷:对将来的某个事件的结果进行建模 在Future类的子类中可以找到CompletableFuture,在介绍中可以看到这是为非异步的请求使用一些异步的方法来处理 点进具 ...
- Java SPI机制总结系列之万字详细图解SPI源码分析
原创/朱季谦 我在<Java SPI机制总结系列之开发入门实例>一文当中,分享了Java SPI的玩法,但是这只是基于表面的应用.若要明白其中的原理实现,还需深入到底层源码,分析一番. 这 ...
- upload—labs
首先 常见黑名单绕过 $file_name = deldot($file_name);//删除文件名末尾的点上传 shell.php. $file_ext = strtolower($file_ext ...