数据湖探索DLI新功能:基于openLooKeng的交互式分析
摘要:基于华为开源openLooKeng引擎的交互式分析功能,将重磅发布便于用户构建轻量级流、批、交互式全场景数据湖。
在这个“信息爆炸”的时代,大数据已经成为这个时代的关键词之一!随着云计算、物联网、移动计算、智慧城市、人工智能等领域日新月异的发展,人类社会已经步入了“信息高速路”的行驶轨道,数据量增长迅速,各类应用对大数据处理的需求也发生着变化。
与此同时,“久经沙场”的数据仓库不再一统江湖,而以实时分析、离线分析、交互式分析等为代表的计算引擎势头迅猛。
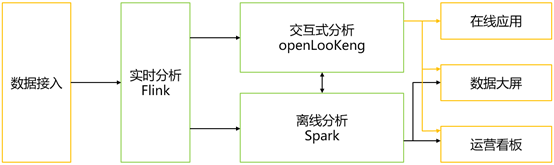
华为云3年前发布的Serverless大数据分析服务 - 数据湖探索DLI,经过这几年的迭代升级,已经包含用于实时分析的Flink引擎,用于离线分析的Spark引擎。今年基于华为开源openLooKeng引擎的交互式分析功能,也将于Q4重磅发布,便于用户构建轻量级流、批、交互式全场景数据湖。
openLooKeng使用了业界著名的开源SQL引擎Presto来提供交互式查询分析基础能力,并继续在融合场景查询、跨数据中心/云、数据源扩展、性能、可靠性、安全性等方面发展,让数据治理、使用更简单。
关键特性
1. 毫秒级查询性能
DLI使用的openLooKeng引擎在内存计算框架的基础上,还利用许多查询优化技术来满足高性能毫秒级的交互式分析的需要。
1.1 索引
openLooKeng提供基于Bitmap Index、Bloom Filter以及Min-max Index等索引。通过在现有数据上创建索引,并且把索引结果存储在数据源外部,在查询计划编排时便利用索引信息过滤掉不匹配的文件,减少需要读取的数据规模,从而加速查询过程。
1.2 Cache
openLooKeng提供丰富多样的Cache,包括元数据cache、执行计划cache、ORC行数据cache等。通过这些多样的cache,可加速用户多次对同一SQL或者同一类型SQL的查询时延响应。
1.3 动态过滤
所谓的动态过滤是指是在运行时(run time)将join一侧表的过滤信息的结果应用到另一侧表的过滤器的优化方法,openLooKeng不仅提供了多种数据源的动态过滤优化特性,还将这一优化特性应用到了DataCenter Connector,从而加速不同场景关联查询的性能。
1.4 算子下推
openLooKeng通过Connector框架连接到RDBMS等数据源时,由于RDBMS具有较强的计算能力,一般情况下将算子下推到数据源进行计算可以获取到更好的性能。openLooKeng目前支持多种数据源的算子下推,包括Oracle、HANA等,特别地,针对DC Connector也实现了算子下推,从而实现了更快的查询时延响应。
2. 高可用
2.1 HA AA双活
openLooKeng引入了高可用的AA特性,支持coordinator AA双活机制,能够保持多个coordinator之间的负载均衡,同时也保证了openLooKeng在高并发下的可用性。
2.2 Auto-scaling
openLooKeng的弹性伸缩特性支持将正在执行任务的服务节点平稳退服,同时也能将处于不活跃状态的节点拉起并接受新的任务。openLooKeng通过提供“已隔离”与“隔离中”等状态接口供外部资源管理者(如Yarn、Kubernetes等)调用,从而实现对coordinator和worker节点的弹性扩缩容。
3. 融合场景
实时分析、离线分析、交互式分析这三种场景中在很多实际业务中都是同时存在的,DLI引入openLooKeng引擎之初就考虑了如何跟已有的Spark引擎进行元数据层面的互通,从而实现离线分析结果,免数据搬迁直接就可以用openLooKeng引擎进行交互式分析。Spark和openLooKeng都支持Hive的建表方式,通过这种方式,实现了元数据层面的互通。
4. 统一目录,跨域跨DC查询
DLI老用户使用比较多的功能是跨多种数据源的联合查询,用于更全面地对数据进行关联分析,释放数据价值。这次引入openLooKeng引擎将跨源查询的能力进一步延伸,开发了跨域跨DC查询的DataCenter Connector。通过这个新Connector可以连接到远端另外的openLooKeng集群,从而提供在不同数据中心间协同计算的能力。 其中的关键技术如下:
4.1 并行数据访问
worker可以并发访问数据源以提高访问效率, 客户端也可以并发从服务端获取数据以加快数据获取速度。
4.2 数据压缩
在数据传输期间进行序列化之前,先使用GZIP压缩算法对数据进行压缩,以减少通过网络传输的数据量。
4.3 跨DC动态过滤
过滤数据以减少从远端提取的数据量,从而确保网络稳定性并提高查询效率。
总结展望
这次加入交互式查询能力,弥补了数据湖探索DLI在毫秒级场景下的短板,构建起从实时分析、到离线分析再到交互式分析整个链路完整的技术栈。
未来,DLI还将探索如何根据业务场景自动识别计算引擎,用户只需要下发SQL,无需关心最终的计算引擎,让大数据真正变成“像使用数据库一样”,“会SQL就会大数据分析”。
数据湖探索DLI新功能:基于openLooKeng的交互式分析的更多相关文章
- 博客主题皮肤探索-添加新功能和fiddler的css/js替换
还有前言 使用了主题之后,发现还差了一点功能.最新评论没有了,导致读者回复需要一点时间去找到底回复了哪条博客.于是就有了添加功能的想法. 如何调试CSS/JS 打开f12,可以看见加载的js资源都是混 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- COS 数据湖最佳实践:基于 Serverless 架构的入湖方案
01 前言 数据湖(Data Lake)概念自2011年被推出后,其概念定位.架构设计和相关技术都得到了飞速发展和众多实践,数据湖也从单一数据存储池概念演进为包括 ETL 分析.数据转换及数据处理的下 ...
- 数据湖应用解析:Spark on Elasticsearch一致性问题
摘要:脏数据对数据计算的正确性带来了很严重的影响.因此,我们需要探索一种方法,能够实现Spark写入Elasticsearch数据的可靠性与正确性. 概述 Spark与Elasticsearch(es ...
- OpenStack Q版本新功能以及各核心组件功能对比
OpenStack Q版本已经发布了一段时间了.今天, 小编来总结一下OpenStack Q版本核心组件的各项主要新功能, 再来汇总一下最近2年来OpenStack N.O.P.Q各版本核心组件的主要 ...
- JuiceFS 在数据湖存储架构上的探索
大家好,我是来自 Juicedata 的高昌健,今天想跟大家分享的主题是<JuiceFS 在数据湖存储架构上的探索>,以下是今天分享的提纲: 首先我会简单的介绍一下大数据存储架构变迁以及它 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
- 基于Apache Hudi构建分析型数据湖
为了有机地发展业务,每个组织都在迅速采用分析. 在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能. 通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特 ...
- 基于 DataLakeAnalytics 的数据湖实践
随着软硬件各方面条件的成熟,数据湖(Data Lake)已经越来越受到各大企业的青睐, 与传统的数仓实践不一样的是,数据湖不需要专门的“入仓”的过程,数据在哪里,我们就从哪里读取数据进行分析.这样的好 ...
随机推荐
- js各种宽高的总结
1.clientWidth和clientHeight指元素的可视部分宽度和高度,就是padding+content如果没有滚动条,就是设定的宽度和高度 如果有滚动条,就是设定的宽度和高度减去滚动条的宽 ...
- ES6入门(一)
1.let声明的变量只在let命令所在的代码块内有效 2.不存在变量提升,先使用变量,后定义变量,就会报错. 3.let不允许在相同作用域内,重复声明同一个变量.
- 读写分离-mycat
读写分离-mycat: 安装mycat: http://dl.mycat.io/1.6.7.1/Mycat-server-1.6.7.1-release-20190627191042-linux.ta ...
- 源码搭建zabbix平台
1.基于lnmp部署zabbix监控平台; zabbix优点: 1.支持自动发现服务器和网络设备: 2.分布式的监控体系和集中式的WEB管理: 3.支持主动监控和被动监控模式: 4.基于SNMP.IP ...
- 20.3 OpenSSL 对称AES加解密算法
AES算法是一种对称加密算法,全称为高级加密标准(Advanced Encryption Standard).它是一种分组密码,以128比特为一个分组进行加密,其密钥长度可以是128比特.192比特或 ...
- openwrt ping: sendto: Network unreachable解决办法
root@OpenWrt:/# ping zhihu.com PING zhihu.com (103.41.167.234): 56 data bytes ping: sendto: Network ...
- Java 7之基础 - 强引用、弱引用、软引用、虚引用(转)
载自:http://blog.csdn.net/mazhimazh/article/details/19752475 1.强引用(StrongReference) 强引用是使用最普遍的引用.如果一个对 ...
- 3种web会话管理的方式(session)
阅读目录 https://www.cnblogs.com/lyzg/p/6067766.html 1. 基于server端session的管理 2. cookie-based的管理方式 3. tok ...
- 重学Java(一):什么是对象
前言 本系列文章内容来自于<Thinking in Java>作者的最新续作<On Java>基础卷,作者根据最新 Java 8.11.17的内容,重讲了Java的编程思想,值 ...
- Net 高级调试之一:开始认识一些调试工具
当进行网络高级调试时,使用合适的工具可以帮助我们更深入地了解问题所在,并提供有效的解决方案.下面是一些常用的网络调试工具,以及它们的功能和用法. 1. Wireshark:Wireshark是一个流行 ...