线性判别分析(LDA):降维与分类的完美结合
在机器学习领域,线性判别分析(Linear Discriminant Analysis,简称LDA)是一种经典的算法,它在降维和分类任务中都表现出色。
LDA通过寻找特征空间中能够最大化类间方差和最小化类内方差的方向,实现数据的降维和分类。
本文主要介绍LDA的基本原理,展示其如何解决分类问题,以及在高维度数据降维中的应用。
1. 基本原理
简单来说,线性判别分析(LDA)旨在找到一个线性组合,将数据投影到低维空间,使得不同类别的数据尽可能地分开,同一类别的数据尽可能地紧凑。
它通过寻找一个投影方向,使得投影后不同类别之间的方差最大,而同一类别内部的方差最小。
寻找投影方向时,LDA基于费舍尔判别准则,该准则通过最大化类间散度与类内散度的比值来寻找最佳投影方向。
LDA基本的计算步骤如下:
- 计算类内散度矩阵:衡量同一类别内数据点的分布
- 计算类间散度矩阵:衡量不同类别之间的分布
- 求解广义特征值问题:找到最大化类间距离与类内距离比值的投影方向
- 选择最优投影方向:将数据投影到低维空间,同时保留分类信息
2. 如何有效降维数据
LDA在处理高维数据时具有显著优势,它通过将数据投影到低维空间,同时保持类别之间的分离度,来实现降维。
下面的示例演示如何使用LDA来实现数据的降维。
首先选择scikit-learn库中经典的鸢尾花数据集,这个数据集中每个数据有4个维度:花瓣的长度和宽度,花萼的长度和宽度。
整个数据集包含3个类别的鸢尾花。
下面通过LDA把数据集降低为2维,然后看看3个类别的鸢尾花在2维空间中是否能区分开来。
from sklearn.datasets import load_iris
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 创建LDA模型,指定降维后的特征数量为2
lda = LinearDiscriminantAnalysis(n_components=2)
# 训练模型并降维
X_lda = lda.fit_transform(X, y)
# 绘制降维后的数据
plt.scatter(X_lda[:, 0], X_lda[:, 1], c=y, cmap='viridis', edgecolors='k')
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.title('LDA 降低到2维')
plt.show()
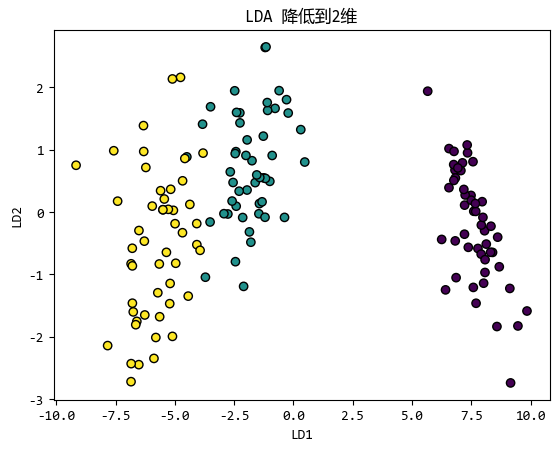
从图中我们可以看出,虽然鸢尾花数据集从四个特征降维到两个维度。
但是,通过可视化降维后的数据,可以看到不同类别的数据点在新的二维空间中仍然保持了良好的分离度。
下面再试试一个更高维度数据的降维,使用scikit-learn库中的手写数字数据集(MNIST)。
这个数据集中的每个数字图片是一个28x28的矩阵,也就是一个784维的数据。
我们将其降维到2维,看看效果如何。
from sklearn.datasets import load_digits
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt
# 加载手写数字数据集
digits = load_digits()
X = digits.data
y = digits.target
# 创建LDA模型,降维到2维
lda = LinearDiscriminantAnalysis(n_components=2)
# 训练并投影数据
X_lda = lda.fit_transform(X, y)
# 可视化降维后的数据
plt.figure()
ten_colors = plt.get_cmap("tab10")(range(10))
for c, i, target_name in zip(ten_colors, [0, 1, 2, 3, 4, 5, 6,7,8,9], ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']):
plt.scatter(X_lda[y == i, 0], X_lda[y == i, 1], color=c, label=target_name)
plt.title('LDA降维后的手写数字数据')
plt.xlabel('LDA 1')
plt.ylabel('LDA 2')
plt.legend()
plt.show()
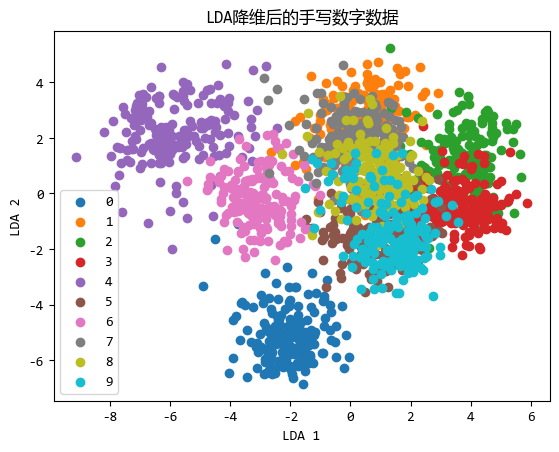
从图中可以看出,0,2,3,4,6分离的还不错,但是1,5,8,9这几个数字映射到2维时重合的比较多。
不过,从784维降低到2维,还能有这样的区分度,LDA已经算是比较厉害了。
3. 如何处理分类问题
除了进行数据降维,LDA也可以处理分类问题,同样上面的鸢尾花数据集,这次不降维直接训练模型进行分类。
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
data = load_iris()
X = data.data
y = data.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建LDA模型
lda = LinearDiscriminantAnalysis()
# 训练模型
lda.fit(X_train, y_train)
# 预测
y_pred = lda.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"分类准确率: {accuracy:.2f}")
## 输出结果:
# 分类准确率: 1.00
从结果来看,LDA分类的准确率高达100%。
再试试高维度的手写数字数据集(MNIST)。
from sklearn.datasets import load_digits
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt
# 加载手写数字数据集
digits = load_digits()
X = digits.data
y = digits.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建LDA模型
lda = LinearDiscriminantAnalysis()
# 训练模型
lda.fit(X_train, y_train)
# 预测
y_pred = lda.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"分类准确率: {accuracy:.2f}")
## 输出结果:
# 分类准确率: 0.95
效果还不错,也有95%的准确率。
4. 总结
线性判别分析(LDA)是一种经典的线性模型,它在降维和分类任务中都表现出色。
LDA的主要特点如下:
- 监督学习:
LDA是一种监督学习方法,它需要利用标签信息来训练模型。 - 线性投影:
LDA通过寻找特征空间中的线性组合,将数据投影到低维空间。 - 最大化类间方差和最小化类内方差:LDA的目标是最大化不同类别之间的分离度,同时最小化同一类别内部的差异。
- 适用于高维数据:
LDA可以有效地处理高维数据,通过降维来降低计算复杂度。 - 分类和降维双重功能:
LDA不仅可以用于分类,还可以用于降维。
LDA在线性模型中具有重要的地位,它结合了降维和分类的优点,是一种非常实用的算法。
然而,LDA也有一些局限性,例如它假设数据服从正态分布,并且类内方差相等。
在实际应用中,我们需要根据数据的特点选择合适的算法。
线性判别分析(LDA):降维与分类的完美结合的更多相关文章
- 机器学习理论基础学习3.2--- Linear classification 线性分类之线性判别分析(LDA)
在学习LDA之前,有必要将其自然语言处理领域的LDA区别开来,在自然语言处理领域, LDA是隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),是一种处理文档的主题 ...
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
- 运用sklearn进行线性判别分析(LDA)代码实现
基于sklearn的线性判别分析(LDA)代码实现 一.前言及回顾 本文记录使用sklearn库实现有监督的数据降维技术——线性判别分析(LDA).在上一篇LDA线性判别分析原理及python应用(葡 ...
- 线性判别分析LDA原理总结
在主成分分析(PCA)原理总结中,我们对降维算法PCA做了总结.这里我们就对另外一种经典的降维方法线性判别分析(Linear Discriminant Analysis, 以下简称LDA)做一个总结. ...
- 线性判别分析LDA详解
1 Linear Discriminant Analysis 相较于FLD(Fisher Linear Decriminant),LDA假设:1.样本数据服从正态分布,2.各类得协方差相等.虽然 ...
- 主成分分析(PCA)与线性判别分析(LDA)
主成分分析 线性.非监督.全局的降维算法 PCA最大方差理论 出发点:在信号处理领域,信号具有较大方差,噪声具有较小方差 目标:最大化投影方差,让数据在主投影方向上方差最大 PCA的求解方法: 对样本 ...
- 线性判别分析 LDA
点到判决面的距离 点\(x_0\)到决策面\(g(x)= w^Tx+w_0\)的距离:\(r={g(x)\over \|w\|}\) 广义线性判别函数 因任何非线性函数都可以通过级数展开转化为多项式函 ...
- 机器学习中的数学-线性判别分析(LDA)
前言在之前的一篇博客机器学习中的数学(7)——PCA的数学原理中深入讲解了,PCA的数学原理.谈到PCA就不得不谈LDA,他们就像是一对孪生兄弟,总是被人们放在一起学习,比较.这这篇博客中我们就来谈谈 ...
- SIGAI机器学习第十集 线性判别分析
讲授LDA基本思想,寻找最佳投影矩阵,PCA与LDA的比较,LDA的实际应用 前边讲的数据降维算法PCA.流行学习都是无监督学习,计算过程中没有利用样本的标签值.对于分类问题,我们要达到的目标是提取或 ...
- LDA线性判别分析(转)
线性判别分析LDA详解 1 Linear Discriminant Analysis 相较于FLD(Fisher Linear Decriminant),LDA假设:1.样本数据服从正态分布,2 ...
随机推荐
- 用领域驱动DDD的方式实现购物车-基于abp一代6.2
废话 之前七七八八看了些DDD相关概念,充血模型.领域事件.领域服务.应用服务等,大致能理解但从未实践.最近在用ABP做个电商模块,尝试用DDD方式来实现购物车功能,感觉还行,下面做个记录. 业务分析 ...
- Kubernetes Pod状态和生命周期管理
Pod是kubernetes中你可以创建和部署的最小也是最简的单位.Pod代表着集群中运行的进程. Pod中封装着应用的容器(有的情况下是好几个容器),存储.独立的 ...
- 如何快速的开发一个完整的iOS直播app(推流篇)
开发一款直播app,肯定需要流媒体服务器,本篇主要讲解直播中流媒体服务器搭建,并且讲解了如何利用FFMPEG编码和推流,并且介绍了FFMPEG常见命令. 效果 一.安装Homebrew Homebre ...
- C#添加log4日志
第一步导入log4net 在vs的程序包管理器控制台中执行命令 NuGet\Install-Package log4net -Version 2.0.0 第二步加帮助类HttpHelper using ...
- 常用的MySQL备份/还原 的方法
mysql备份数据库 mysql备份单个数据库 #mysql备份某个库格式: mysqldump -h主机名 -P端口 -u用户名 -p"密码" --database 数据库名 & ...
- Mac安装NTL库
Mac安装NTL库 NTL是一个高性能.可移植的C++库,为任意长度的整数提供数据结构和算法:用于整数和有限域上的向量.矩阵和多项式:以及任意精度的浮点运算. 具有以下功能: 任意长度整数运算和任意精 ...
- linux:搭建 WordPress 个人站点
参考:链接 介绍 WordPress 是一款使用 PHP 语言开发的博客平台,您可使用通过 WordPress 搭建属于个人的博客平台.本文以 CentOS 6.5 操作系统为例,手动搭建 WordP ...
- 闲话 6.30 -JL 引理
参考了 https://spaces.ac.cn/archives/8679/comment-page-1,有一些增删. JL 引理 首先下面需要应用马尔可夫不等式的另一个形式: \[\newcomm ...
- NOIp 2024 考试策略
无论简不简单,都要在前 30min 浏览所有题面,思考哪题可做.哪题不可做,思考能打哪些部分分,9:00 再开始写 T1. 题目简单时 9:00 开写后,30min 以内切完 T1. 9:30 开 T ...
- 用脚本采用wget方式直接下载谷歌云盘里面的文件实操
今天在工作中遇到了一个挑战,在这里和大家分享一下我的解决过程.突然接到一个紧急需求,需要在服务器上部署一个模型文件,而这个文件存储在谷歌云盘里.摆在面前有两个选择: 方案一:先在本地下载,然后再上传到 ...