机器学习理论基础学习3.2--- Linear classification 线性分类之线性判别分析(LDA)
在学习LDA之前,有必要将其自然语言处理领域的LDA区别开来,在自然语言处理领域, LDA是隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),是一种处理文档的主题模型。本文只讨论线性判别分析,因此后面所有的LDA均指线性判别分析。
线性判别分析 LDA: linear discriminant analysis
一、LDA思想:类间小,类间大 (‘高内聚,松耦合’)
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的,这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”,如下图所示。 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。

可能还是有点抽象,先看看最简单的情况。
假设有两类数据,分别为红色和蓝色,如下图所示,这些数据特征是二维的,希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。
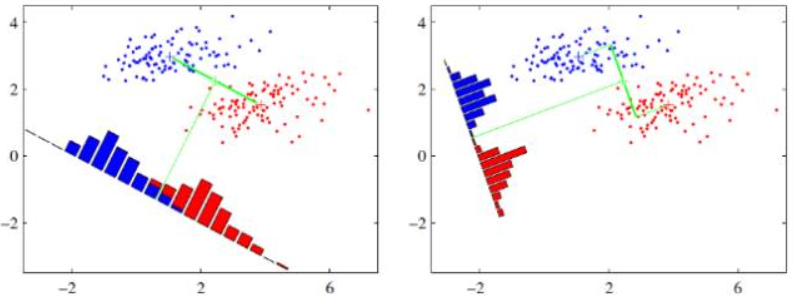
上图中提供了两种投影方式,哪一种能更好的满足我们的标准呢?从直观上可以看出,右图要比左图的投影效果好,因为右图的黑色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。以上就是LDA的主要思想了,当然在实际应用中,数据是多个类别的,我们的原始数据一般也是超过二维的,投影后的也一般不是直线,而是一个低维的超平面。
二、LDA原理与流程



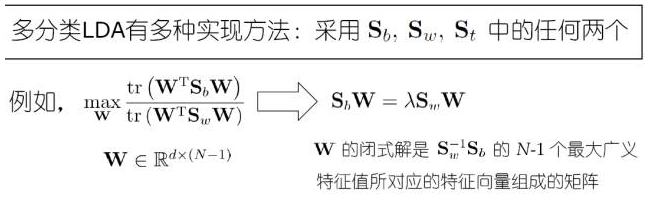
三、LDA分类

四、LDA降维

五、LDA与PCA的相同点和不同点
LDA用于降维,和PCA有很多相同,也有很多不同的地方
相同点
- 1)两者均可以对数据进行降维。
- 2)两者在降维时均使用了矩阵特征分解的思想。
- 3)两者都假设数据符合高斯分布。
不同点
- 1)LDA是有监督的降维方法,而PCA是无监督的降维方法
- 2)LDA降维最多降到类别数k-1的维数,而PCA没有这个限制。
- 3)LDA除了可以用于降维,还可以用于分类。
- 4)LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。这点可以从下图形象的看出,在某些数据分布下LDA比PCA降维较优。


四、LDA的优缺点
LDA算法既可以用来降维,又可以用来分类,但是目前来说,主要还是用于降维。在进行图像识别相关的数据分析时,LDA是一个有力的工具。下面总结下LDA算法的优缺点。
优点
- 1)在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
- 2)LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
缺点
- 1)LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
- 2)LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
- 3)LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
- 4)LDA可能过度拟合数据。
参考文献:
机器学习理论基础学习3.2--- Linear classification 线性分类之线性判别分析(LDA)的更多相关文章
- 机器学习理论基础学习12---MCMC
作为一种随机采样方法,马尔科夫链蒙特卡罗(Markov Chain Monte Carlo,以下简称MCMC)在机器学习,深度学习以及自然语言处理等领域都有广泛的应用,是很多复杂算法求解的基础.比如分 ...
- 机器学习理论基础学习3.1--- Linear classification 线性分类之感知机PLA(Percetron Learning Algorithm)
一.感知机(Perception) 1.1 原理: 感知机是二分类的线性模型,其输入是实例的特征向量,输出的是事例的类别,分别是+1和-1,属于判别模型. 假设训练数据集是线性可分的,感知机学习的目标 ...
- 机器学习理论基础学习3.3--- Linear classification 线性分类之logistic regression(基于经验风险最小化)
一.逻辑回归是什么? 1.逻辑回归 逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数,来达到将数据二分类的目的. logistic回归也称为逻辑回归,与线性回归这样输出 ...
- 机器学习理论基础学习3.5--- Linear classification 线性分类之朴素贝叶斯
一.什么是朴素贝叶斯? (1)思想:朴素贝叶斯假设 条件独立性假设:假设在给定label y的条件下,特征之间是独立的 最简单的概率图模型 解释: (2)重点注意:朴素贝叶斯 拉普拉斯平滑 ...
- 机器学习理论基础学习3.4--- Linear classification 线性分类之Gaussian Discriminant Analysis高斯判别模型
一.什么是高斯判别模型? 二.怎么求解参数?
- 机器学习理论基础学习17---贝叶斯线性回归(Bayesian Linear Regression)
本文顺序 一.回忆线性回归 线性回归用最小二乘法,转换为极大似然估计求解参数W,但这很容易导致过拟合,由此引入了带正则化的最小二乘法(可证明等价于最大后验概率) 二.什么是贝叶斯回归? 基于上面的讨论 ...
- 机器学习理论基础学习4--- SVM(基于结构风险最小化)
一.什么是SVM? SVM(Support Vector Machine)又称为支持向量机,是一种二分类的模型.当然如果进行修改之后也是可以用于多类别问题的分类.支持向量机可以分为线性和非线性两大类. ...
- 机器学习理论基础学习5--- PCA
一.预备知识 减少过拟合的方法有:(1)增加数据 (2)正则化(3)降维 维度灾难:从几何角度看会导致数据的稀疏性 举例1:正方形中有一个内切圆,当维度D趋近于无穷大时,圆内的数据几乎为0,所有的数据 ...
- 机器学习理论基础学习13--- 隐马尔科夫模型 (HMM)
隐含马尔可夫模型并不是俄罗斯数学家马尔可夫发明的,而是美国数学家鲍姆提出的,隐含马尔可夫模型的训练方法(鲍姆-韦尔奇算法)也是以他名字命名的.隐含马尔可夫模型一直被认为是解决大多数自然语言处理问题最为 ...
随机推荐
- WEB服务器控件对应生成的HTML标签 及最常应用事例
首先得了解WEB服务器控件对应生成的HTML标签 label----------<span/>button---------<input type="submit" ...
- Android 使用tomcat搭建HTTP文件下载服务器
上一篇: Android 本地搭建Tomcat服务器供真机测试 1.假设需要下载的文件目录是D:\download1(注意这里写了个1,跟后面的名称区分) 2.设置 tomcat 的虚拟目录.在 {t ...
- Sencha Touch 实战开发培训 视频教程 第二期 第四节
2014.4.14 晚上8:10分开课. 本节课耗时没有超出一个小时,主要讲解了list的一些扩展用法. 本期培训一共八节,前两节免费,后面的课程需要付费才可以观看. 本节内容: List的高级应用 ...
- 2555: SubString[LCT+SAM]
2555: SubString Time Limit: 30 Sec Memory Limit: 512 MB Submit: 2601 Solved: 780 [Submit][Status][ ...
- Artech的MVC4框架学习——第八章View的呈现
总结:定义在controller中的action方法一般会返回actionResult的对象对请求给予 响应.viewResult是最常见也是最重要的ActionView的一种(p411).view模 ...
- JSPatch - 基本使用和学习
介绍 JSPatch是2015年由bang推出的能实现热修复的工具,只要在项目中引入极小的JSPatch引擎,就可以用 JavaScript 调用和替换任何 Objective-C 的原生方法,获得脚 ...
- React Native ——入门环境搭配以及简单实例
一.Homebrew 是OS X 的套件管理器. 首先我们需要获取 Homebrew ruby -e "$(curl -fsSL https://raw.githubusercontent. ...
- [转]Android Activity的加载模式和onActivityResult方法之间的冲突
前言 今天在调试程序时,发现在某一Activity上点击返回键会调用该Activity的onActivityResult()方法.我一开始用log,后来用断点跟踪调试半天,还是百思不得其解.因为之前其 ...
- 基于pandas python的美团某商家的评论销售数据分析(可视化)
基于pandas python的美团某商家的评论销售数据分析 第一篇 数据初步的统计 本文是该可视化系列的第二篇 第三篇 数据中的评论数据用于自然语言处理 导入相关库 from pyecharts i ...
- ubuntu16.04下安装Eigen
请输入以下命令进行安装: sudo apt-get install libeigen3-dev 一个库由头文件和库文件组成.Eigen头文件的默认位置在 “usr/include/eigen3” 中. ...