05 过拟合(over-fitting)与正则化(regularization)
1. 什么是Overfitting
我们希望神经网络模型能够找到数据集中的一般规律,从而帮助我们预测未知数据。这个过程是通过不断地迭代优化损失函数(也就是预测值和实际值的误差)而实现的。然而随着误差进一步缩小,模型的“走势”过于“贴合”我们的训练数据,对训练数据中的噪声也过于趋近,把这些噪声数据也学进了模型当中。这时候,该模型承载的就不再是“一般规律”,而是把所有数据几乎“记忆”了下来。当我们用这种模型去预测未知数据时,会发现误差非常大。这种模型过于“贴合”训练数据的情况,就叫做过拟合(Overfitting)。
下图展示了回归任务和分类任务的三种不同拟合情况:
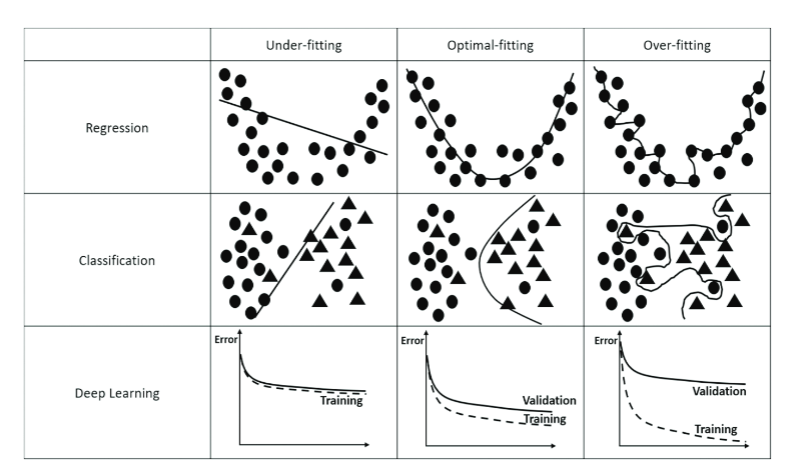
(Meedeniya, Dulani. Deep Learning: A Beginners’ Guide. 1st ed. New York: Chapman and Hall/CRC, 2023.)
Overfitting的表现,一般是在训练数据上表现优异,但在未见过的新数据上表现显著下降。因此,我们通常将所有数据集分成训练集和测试集,用训练集训练模型,用测试集验证模型是否发生过拟合。
上图中,在Underfitting时,模型几乎没有学习到数据的一般规律,此时训练集的误差和测试集的误差都很大;在Overfitting时,模型过于“贴合”训练数据,导致把噪声内容也学习到模型当中,此时模型虽然在训练集上误差很小,但在测试集上表现很差;理想情况应该是模型学习到数据的一般规律,在训练集和测试集上表现良好。
2. Overfitting的原因
模型过于复杂
当模型的参数增多,层数加深时,模型表达能力也在提升,但当表达能力远超数据真实规律时,就更容易学习到训练数据中的噪声、异常值或特定细节,而非学习到数据背后的通用规律。
数据量不足 质量低劣
当训练样本过少时,模型难以捕捉数据的整体分布,反而把局部的噪声当作规律。
训练策略不当
在模型训练时,训练集的误差随着优化过程不断地缩小,如果训练迭代次数过多,就会使得模型过于“贴合”训练数据,导致在测试集上误差加大。
3. 如何处理overfitting
正则化(Regularization)的定义
正则化是一类提升模型泛化能力的技术,其核心目标是抑制模型对训练数据中噪声、异常值或局部特征的过度依赖,从而缓解过拟合现象。所谓泛化能力,是把在已知数据中学习到的潜在规律(知识)迁移到未知数据上的能力。泛化能力好,则模型应用到未知数据上也能进行很好的预测;泛化能力差,则模型不能很好的对未知数据进行预测。一切提升模型泛化能力的方法都可以称为正则化方法。
通过上文中Overfitting原因介绍,我们很容易对症下药,从调整训练策略、降低模型复杂度、增强数据三个面找到处理Overfitting的方法:
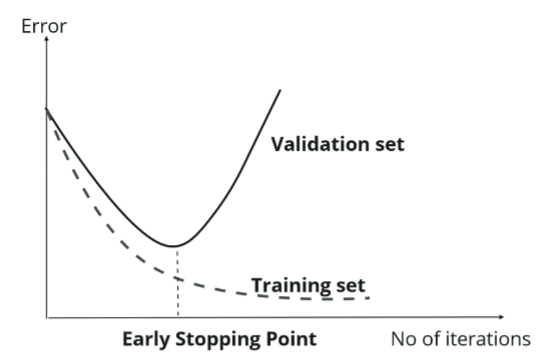
early stopping
正则化最简单的方式,就是提前结束训练。在优化迭代的进行过程中,训练集数据的误差会持续降低,而验证集上的误差则会经历一个初始的下降阶段后达到一个转折点。过了这个转折点,模型开始出现过拟合现象,导致验证集上的误差转而上升。因此,我们在这个拐点处就停止迭代,以此来有效避免模型的过拟合问题。
dropout
在训练时随机“丢弃”(临时屏蔽)一部分神经元,迫使网络不依赖特定神经元,增强泛化能力。这本质上是一种降低模型复杂度的方法。这种随机的丢弃是指在每次迭代均屏蔽不同的神经元,确保模型在不同训练批次中接触不同的子网络结构。
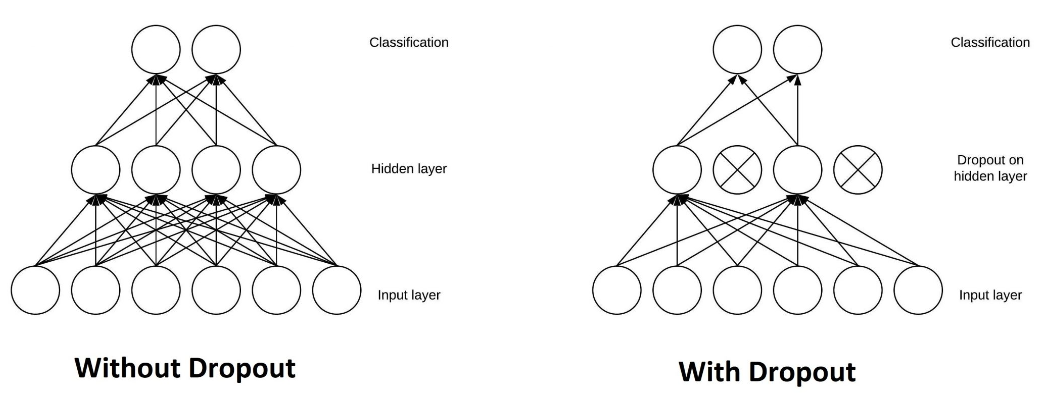
具体实现方法是:在训练阶段,每个神经元以概率p被保留,以1-p的概率被临时屏蔽(输出置零)。屏蔽过程通过生成与神经元输出维度相同的随机掩码矩阵实现,矩阵元素以概率p取1,其余取0。保留的神经元输出乘以1/p,这是为了保证整体流入下一层的信号强度不变。
示例:若某层有1000个神经元,保留概率p=0.7,则每次迭代约300个神经元被屏蔽,剩余700个输出放大至1/0.7≈1.428倍
在反向传播时,该层神经元的梯度也要乘以这个掩码矩阵,保证其对应的权重不得到更新。
在测试时,将所有神经元保留,来测试整体模型能力。
L1,L2正则化
L1正则化(Lasso):在损失函数中添加参数的绝对值之和作为惩罚项:
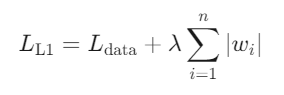
其中,\(L_{data}\)为原始损失函数(如均方误差),λ为正则化强度参数。
L2正则化(Ridge):在损失函数中添加参数的平方和作为惩罚项:
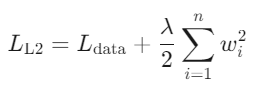
注意L2正则化常包含系数1/2以简化梯度计算。
我们看损失函数添加了正则项之后对梯度的影响:
L1的梯度更新:
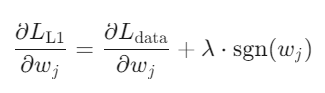
符号函数\(sgn(w_j)\)导致参数每次更新固定步长(如±λ),当w为正时,更新后w会变小;w为负时,更新后w会变大。w最终可能收敛到0,从而降低模型复杂度。
L2的梯度更新:
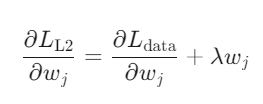
参数更新幅度与当前值成正比,参数逐渐衰减但不会归零。通过限制权重幅度,L2正则化实质降低了模型的“容量”,使其无法过度关注训练数据中的细微波动,从而更关注主要规律。
L1、L2对比:
L1正则化鼓励模型参数稀疏化(即产生很多零值参数),通过稀疏性自动筛选重要特征,适用于高维数据(如基因数据、文本分类)。而L2正则化则使模型参数趋近于零,但并不产生完全稀疏的模型。
L1正则化倾向于将无关特征权重设置为零,对于异常值较为鲁棒;而L2正则化则对所有参数进行平滑处理,防止模型对单一特征过度敏感,有一定的抑制噪声作用。
从计算角度来看,L2正则化由于目标函数可导,优化过程更稳定。
数据增强
增加训练数据量,或通过对训练数据进行随机变换(如旋转、缩放、平移等)来增加数据多样性。
05 过拟合(over-fitting)与正则化(regularization)的更多相关文章
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- zzL1和L2正则化regularization
最优化方法:L1和L2正则化regularization http://blog.csdn.net/pipisorry/article/details/52108040 机器学习和深度学习常用的规则化 ...
- 7、 正则化(Regularization)
7.1 过拟合的问题 到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fittin ...
- 数据的平面拟合 Plane Fitting
数据的平面拟合 Plane Fitting 看到了一些利用Matlab的平面拟合程序 http://www.ilovematlab.cn/thread-220252-1-1.html
- 斯坦福第七课:正则化(Regularization)
7.1 过拟合的问题 7.2 代价函数 7.3 正则化线性回归 7.4 正则化的逻辑回归模型 7.1 过拟合的问题 如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集( ...
- [笔记]机器学习(Machine Learning) - 03.正则化(Regularization)
欠拟合(Underfitting)与过拟合(Overfitting) 上面两张图分别是回归问题和分类问题的欠拟合和过度拟合的例子.可以看到,如果使用直线(两组图的第一张)来拟合训,并不能很好地适应我们 ...
- 防止过拟合:L1/L2正则化
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- [C3] 正则化(Regularization)
正则化(Regularization - Solving the Problem of Overfitting) 欠拟合(高偏差) VS 过度拟合(高方差) Underfitting, or high ...
随机推荐
- 直播系统聊天技术(八):vivo直播系统中IM消息模块的架构实践
本文由vivo互联网技术团队LinDu.Li Guolin分享,有较多修订和改动. 1.引言 IM即时消息模块是直播系统的重要组成部分,一个稳定.有容错.灵活的.支持高并发的消息模块是影响直播系统用户 ...
- kubernetes系列(二) - kubectl的入门操作
目录 1. 安装 / 卸载 1 .1 前提条件 1.2 安装方式 1.3 卸载 2. 通过 minikube 学习 k8s 实操基础 2.1 创建集群 2.2 部署应用 2.3 探索当前应用[故障排除 ...
- snpEff安装
下载安装包: wget http://sourceforge.net/projects/snpeff/files/snpEff_v3_6_core.zip 解压安装包: unzip snpEff_v3 ...
- 如何监控Linux服务器资源使用情况
--- 好的方法很多,我们先掌握一种 --- [背景] 在做性能验证时(其他情况通用),需要监控服务器资源的使用情况,例如cpu,内存等信息 我们就可以简单通过shell脚本后台运行,持续监控需要 ...
- Solution -「CTSC 2017」「洛谷 P3772」游戏
\(\mathscr{Description}\) 有 \(n\) 个随机真值 \(x_{1..n}\), 已知 \(P(x_1=1)=p_1\), 对于 \(2\le i\le n\), \(P ...
- 化繁为简、性能提升 -- 在WPF程序中,使用Freetype库心得
本人使用WPF开发了一款OFD阅读器,显示字体是阅读器中最重要的功能.处理字体显示有多种方案,几易其稿,最终选用Freetype方案.本文对WPF中如何使用Freetype做简单描述. OFD中有两种 ...
- .NET 9.0 使用 Vulkan API 编写跨平台图形应用
前言 大家好,这次我来分享一下我自己实现的一个 Vulkan 库,这个库是用 C# 实现的,主要是为了学习 Vulkan 而写的. 在学习 Vulkan 的过程中,我主要参考 veldrid,它是一个 ...
- IDEA配置Maven(详细版)
https://blog.csdn.net/qq_42057154/article/details/106114515 IDEA配置MavenIDEA创建Maven工程第一节 IDEA集成Maven插 ...
- 深入理解ReentrantLock的实现原理
文章目录ReentrantLock简介AQS回顾ReentrantLock原理ReentrantLock结构非公平锁的实现原理lock方法获取锁tryRelease锁的释放公平锁的实现原理lock方法 ...
- python教程合集(更新中)
python教程目录 基础 hello world 变量 输入输出