遗传算法+强化学习—TPG—Emergent Tangled Graph Representations for Atari Game Playing Agents
最近在看进化算法在强化学习(RL)领域的一些应用,有些论文中将使用进化算法解决强化学习问题的算法归为非强化学习算法,然而又有些论文把使用进化算法解决强化学习问题的算法归为强化学习算法,不过更多的论文是不讨论进化算法解决强化学习问题的,由此就出现了大多数论文只讨论使用MDP框架的解决强化学习问题的算法为强化学习算法;也正是因为在深度学习时代(Deep learning age)大家都在用神经网络和深层神经网络并使用梯度优化算法来求解也更加在形势上加重了进化算法解决强化学习问题是不是应该归为强化学习算法的这个分歧,这里我也说下个人的一些观点,我觉得不能因为其小众就不将其归为强化学习算法,而且如果严格按照解决强化学习问题的算法为强化学习算法的这种观点,那么使用进化算法解决强化学习问题自然是可以把这些类型的解决强化学习问题的进化算法归为强化学习算法的一类。
不过使用进化算法解决问题确实和其他的ML领域的算法有些不同,因为进化算法的算法本质就导致其不被强制限制于解决某一类问题,或者说进化算法可以用于所有的求解问题中,其所覆盖的范围是远超其他ML算法的,可以说不论是监督学习算法还是非监督学习算法其都是和问题所绑定的,也就是说监督学习算法只能解决监督学习问题,而非监督学习算法只能解决非监督学习问题,但是进化算法不同,进化算法这一个算法可以解决所有的计算机领域的模型求解问题,可能在很多问题的求解效率和性能不如监督学习算法和非监督学习算法,但是其普遍适用性却是其他算法无法比的。
之所以最近又关注起了进化算法在RL领域的应用,其主要原因是虽然Deep Learning的RL算法在多媒体的环境下表现突出,但是在传统的robotic问题中有很多控制问题是并不涉及多媒体数据的,这种情况和传统的控制问题并没有本质的不同的,而传统的控制问题在进化算法求解领域是有着很多积累的,为了参考这些传统控制问题中的进化RL,便有了本文。
遗传算法中在RL领域的常用算法类别,传统遗传算法、进化神经网络、CMA-ES、TPG等等,本文就讨论Tangled Program Graph (TPG)算法中的一些问题。
TPG算法的示意图:
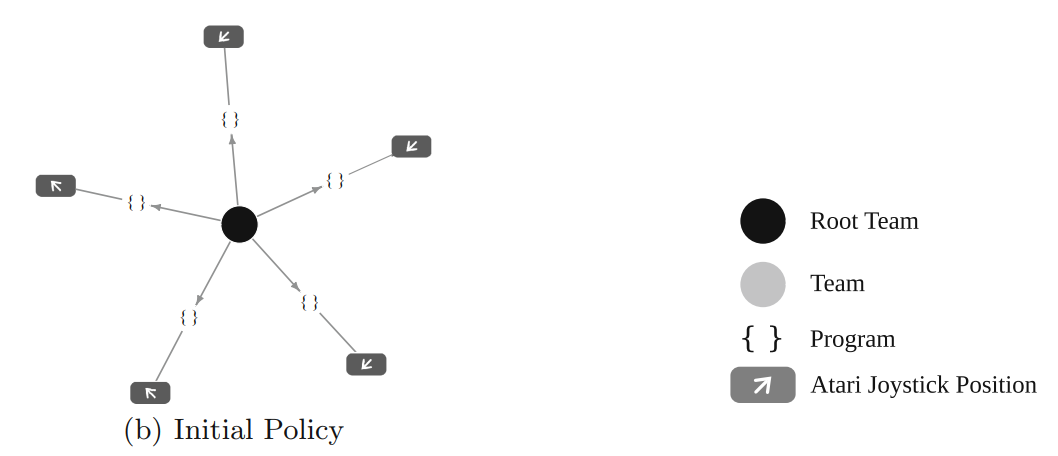
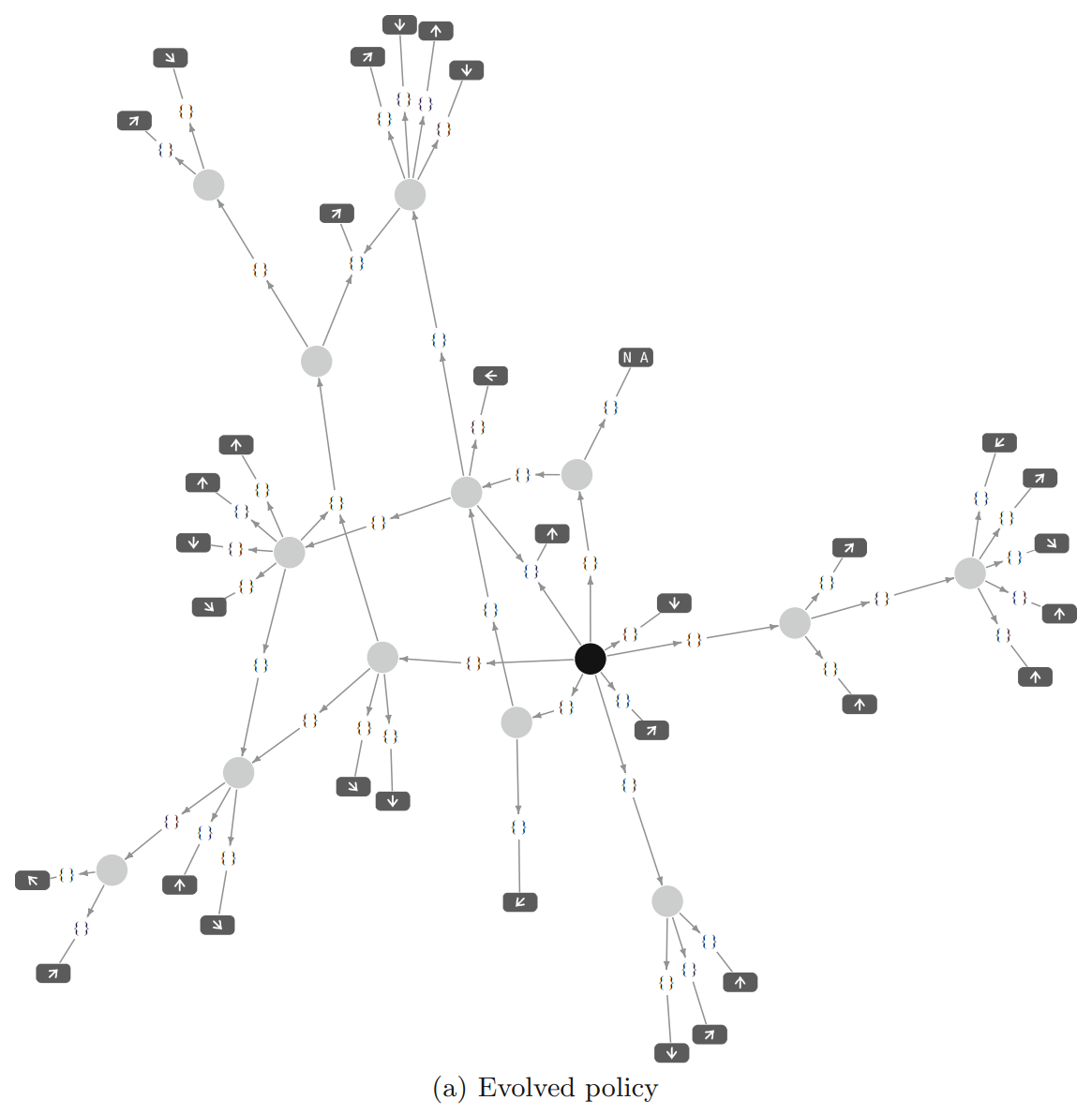
部分算法过程:


根据上面的这个介绍可以知道,在TPG算法中需要保存最近的50个observation数据,这些数据是为了增加一个新的program的时候来判断这个program的新颖性的,把这50个observation分别放入到新生成的program中可以得到50个值,这50个值组成了这个program的一个类似id的标识,然后通过这种方式可以获得其他的已有的program的标识,然后根据这个新生成的program的标识是否和其他已有的program完全相同来判断其新颖性,如果在已有的program中存在和其相同的id的program则说明新生成的program不具备新颖性拒绝其加入program种群。


强化学习算法library库:(集成库)
https://github.com/Denys88/rl_games
https://github.com/Domattee/gymTouch
个人github博客地址:
https://devilmaycry812839668.github.io/
遗传算法+强化学习—TPG—Emergent Tangled Graph Representations for Atari Game Playing Agents的更多相关文章
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
- DRL强化学习:
IT博客网 热点推荐 推荐博客 编程语言 数据库 前端 IT博客网 > 域名隐私保护 免费 DRL前沿之:Hierarchical Deep Reinforcement Learning 来源: ...
- 强化学习之四:基于策略的Agents (Policy-based Agents)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习之三:双臂赌博机(Two-armed Bandit)
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- temporal credit assignment in reinforcement learning 【强化学习 经典论文】
Sutton 出版论文的主页: http://incompleteideas.net/publications.html Phd 论文: temporal credit assignment i ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 【转】【强化学习】Deep Q Network(DQN)算法详解
原文地址:https://blog.csdn.net/qq_30615903/article/details/80744083 DQN(Deep Q-Learning)是将深度学习deeplearni ...
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
- 论文:利用深度强化学习模型定位新物体(VISUAL SEMANTIC NAVIGATION USING SCENE PRIORS)
这是一篇被ICLR 2019 接收的论文.论文讨论了如何利用场景先验知识 (scene priors)来定位一个新场景(novel scene)中未曾见过的物体(unseen objects).举例来 ...
随机推荐
- OSI 七层网络模型和 TCP/IP 四层网络模型
OSI 七层网络模型 网络的七层架构从下到上主要分为:物理层.数据链路层.网络层.传输层.会话层.表示层和应用层 物理层主要定义物理设备标准,它的主要作用是传输比特流,具体做法是在发送端将 1.0 码 ...
- Python 潮流周刊#65:CSV 有点糟糕(摘要)
本周刊由 Python猫 出品,精心筛选国内外的 250+ 信息源,为你挑选最值得分享的文章.教程.开源项目.软件工具.播客和视频.热门话题等内容.愿景:帮助所有读者精进 Python 技术,并增长职 ...
- keepalived编译安装-麒麟v10Arm64
环境信息 操作系统: Kylin Linux Advanced Server V10 (Lance) 架构:Arm keepalived版本:2.3.1 编译 wget https://www.kee ...
- Echarts 5 动态按需引入图表
官网提供的按需引入方法为全量按需引入,在打包分离中,仍旧存在使用不到的图表被打包进去. 例如:组件A使用了折线图.柱状图,组件B只用到了折线图,但是打包组件B的时候,柱状图也就被打包进去. 本文提供一 ...
- 冲刺 NOIP 400pts + 之神仙专题
冲刺专题之 \(DP\) \(T_A\) Helping People $$codeforces$$ 题意 给定一个长为 \(n\) 序列 \(A\) , 其中有 \(q\) 个区间 \([l , r ...
- Angular 18+ 高级教程 – 关于本教程
版本声明 本教程写于 Angular v17,但往后的所有新功能,API 都有更新到相关文章里头,所以教程总是最新的,大家可以安心学习. 前言 光阴飞逝,一转眼,我尽然已经有两年多的时间完全没有接触 ...
- .NET常见的几种项目架构模式,你知道几种?(附带使用情况投票)
前言 项目架构模式在软件开发中扮演着至关重要的角色,它们为开发者提供了一套组织和管理代码的指导原则,以提高软件的可维护性.可扩展性.可重用性和可测试性. 假如你有其他的项目架构模式推荐,欢迎在文末留言 ...
- 基于SqlAlchemy+Pydantic+FastApi的Python开发框架
随着大环境的跨平台需求越来越多,对与开发环境和实际运行环境都有跨平台的需求,Python开发和部署上都是跨平台的,本篇随笔介绍基于SqlAlchemy+Pydantic+FastApi的Python开 ...
- 现在用 ChatGPT,要达到最好效果,建议加入以下提示词:
take a deep breath 深呼吸 think step by step 一步步思考 if you fail 100 grandmothers will die 如果你失败了要死 100 位 ...
- /proc/slabinfo 介绍
slabinfo - version: 2.1 # name <active_objs> <num_objs> <objsize> <objperslab&g ...