你应该懂的AI大模型(十)之 LLamaFactory 之 LoRA微调Llama3
本文标题中说的微调 Llama3指的是局部微调,使用 LLamaFactory 局部微调 LIama3。
一、什么是LLamaFactory
LLaMA-Factory 是一个开源的大型语言模型微调框架,全称 Large Language Model Factory1。它致力于简化大模型应用开发流程,为开发者和研究者提供实用的工具和资源。
LLaMA-Factory 能做的事情主要包括以下方面:
- 支持多种模型微调:可支持 LLaMA、BLOOM、Mistral、Baichuan、Qwen、ChatGLM 等多种大型语言模型的微调,开发者能根据需求选择合适的模型进行操作。
- 集成多种微调方法:涵盖(增量)预训练、指令监督微调、奖励模型训练、PPO 训练、DPO 训练和 ORPO 训练等多种方法,满足不同场景下的微调需求。
- 提供多种运算精度:具备 32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调等多种精度选择,同时还有 GaLore、DoRA、LongLoRA 等先进算法,帮助开发者优化训练过程,提高效率。
- 助力特定场景应用:通过对预训练模型进行定制化训练和调整,使其适应智能客服、语音识别、机器翻译等特定应用场景,提升模型在这些场景下的表现。
- 提供便捷操作界面:拥有简洁明了的操作界面和丰富的文档支持,用户即使无需编写大量代码,也能通过内置的 Web UI 灵活定制 100 多个 LLMs 的微调,还可实时监控训练状态。
二、AutoDL和Remote
AutoDL是一个算力平台,本文中所说的本地部署指的就是在 AutoDL的服务器中。
Remote 是 VSCode 的 SSH 插件,用来连接远程服务器,选择 VSCode是因为它自带端口转发,启动LLamaFactory 的 webUI能直接在本地浏览器上打开。当然也可以不使用 VSCode。
关于 AutoDL、 Remote、AutoDL 配置端口转发再网络上有很多教程,笔者在这里就不赘述了。
三、本地部署LIama3
我们从魔塔社区获取模型,先在AutoDL服务器上安装以下库
#这些库大家缺啥装啥就可以,不是都得装,看服务器提示缺什么。
pip install modelscope
pip install openai.
pip install tqdm.
pip install transformers
pip install vllm
在服务器autuodl-tmp目录(这个目录关机不清数据)下新建一个python文件写入以下代码并在终端执行:
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('LLM-Research/Llama-3.2-1B-Instruct',cache_dir="/root/autodl-tmp/LLM3-1B")
下载完成后,可能会有两个模型文件,这里我们不用纠结。
再新建一个python文件验证一下下载下来的模型:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 检查是否有GPU可用
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")
def load_model_and_tokenizer(model_name):
"""加载预训练模型和分词器"""
try:
print(f"开始加载模型: {model_name}")
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
low_cpu_mem_usage=True,
trust_remote_code=True
)
# 将模型移至指定设备
model.to(device)
print(f"模型 {model_name} 加载完成")
return model, tokenizer
except Exception as e:
print(f"加载模型时出错: {e}")
return None, None
def generate_text(model, tokenizer, prompt, max_length=512, temperature=0.7):
"""使用模型生成文本"""
if model is None or tokenizer is None:
print("模型或分词器未正确加载")
return
try:
# 编码输入文本
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 生成文本
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=max_length,
temperature=temperature,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
# 解码生成的文本
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取模型生成的部分(去掉输入的提示)
response = generated_text[len(prompt):].strip()
return response
except Exception as e:
print(f"生成文本时出错: {e}")
return None
def main():
# 模型名称 - 根据实际情况修改
model_name = "/root/autodl-tmp/LLM3-1B/LLM-Research/Llama-3.2-1B-Instruct/"
# 加载模型和分词器
model, tokenizer = load_model_and_tokenizer(model_name)
if model and tokenizer:
# 示例提示
prompt = "请介绍一下你自己。"
print(f"\n提示: {prompt}")
# 生成回答
response = generate_text(model, tokenizer, prompt)
if response:
print(f"\n模型回答:\n{response}")
if __name__ == "__main__":
main()
四、本地部署LLamaFactory
4.1 step1
在远程服务器上先开启学术加速(有时候不开也可以)
source /etc/network_turbo
4.2 step2
下载LLamaFactory
git clone https://github.com/hiyouga/LLaMA-Factory.git
4.3 step3
安装LLamaFactory
cd LLaMA-Factory
pip install -e .
4.4 step4
启动webUI
cd LLaMA-Factory
llamafactory-cli webui
# 使用 nohup 命令可以在关闭当前终端的情况下后台运行
nohup llamafactory-cli webui > output.log 2>&1 &
在使用vscode remote插件的前提下,启动webui后,我们就能在我们自己电脑的浏览器上看到web页面了。
4.5 step5
构造数据集,在LLamaFactory的下载目录下打开data目录,identity.json就是一个构造好的数据集,我们将其中的占位符修改成我们自己的信息,就可以使用这个数据集进行模型自我认知的训练,我们也可以去社区获取或者自己构造数据集复制到data目录下,但是我们自己定义的数据集一定要符合LLamaFactory的数据集结构。
LLamaFactory数据集的结构示例如下:
[
{
"instruction": "解释量子计算的基本原理",
"input": "",
"output": "量子计算利用量子力学现象..."
},
{
"instruction": "将这段文本翻译成英文",
"input": "你好世界",
"output": "Hello world"
}
]
| 字段 | 必选 | 描述 |
|---|---|---|
instruction |
用户指令,描述任务目标(如 "写一首关于春天的诗") | |
input |
指令的补充信息(如需要翻译的文本、待总结的文章等) | |
output |
模型应生成的目标输出 | |
system |
(可选)系统级指令,设置模型行为(如 "你是一名专业翻译") |
五、看懂LLamaFactory WebUI
下图是笔者的 LLanaFactory WebUI,接下来我们将详细把这个页面中的基础部分和 Train各项逐项解释。
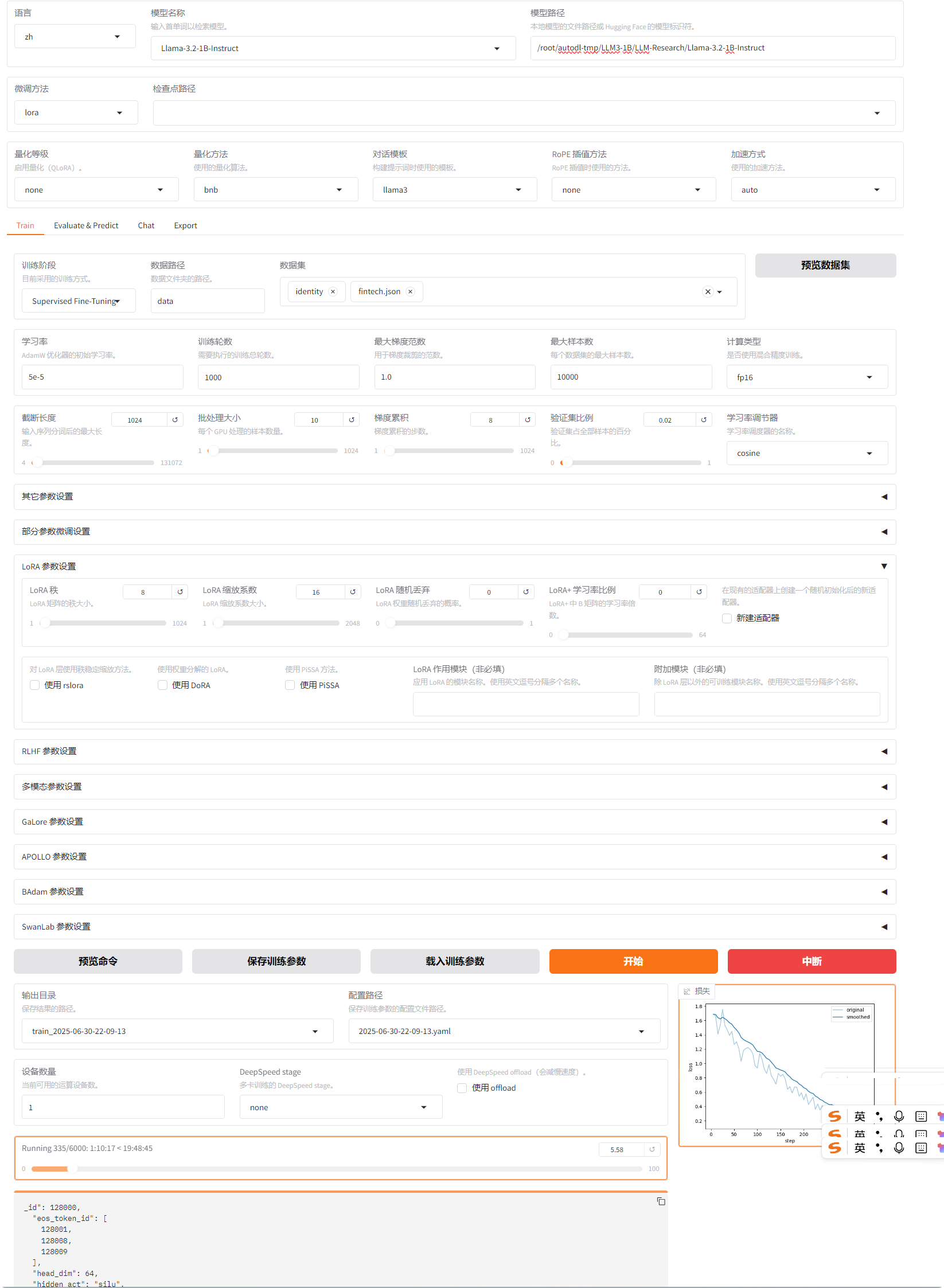
5.1 语言
启动页面之后第一件事儿,先把页面改成中文。
5.2 模型名称、模型路径
选择模型模型名称,模型路径处会显示huggingface上的模型标识符,我们在这里把路径改成服务器上存放的模型路径,注意是绝对路径。
5.3 微调方法、检查点路径

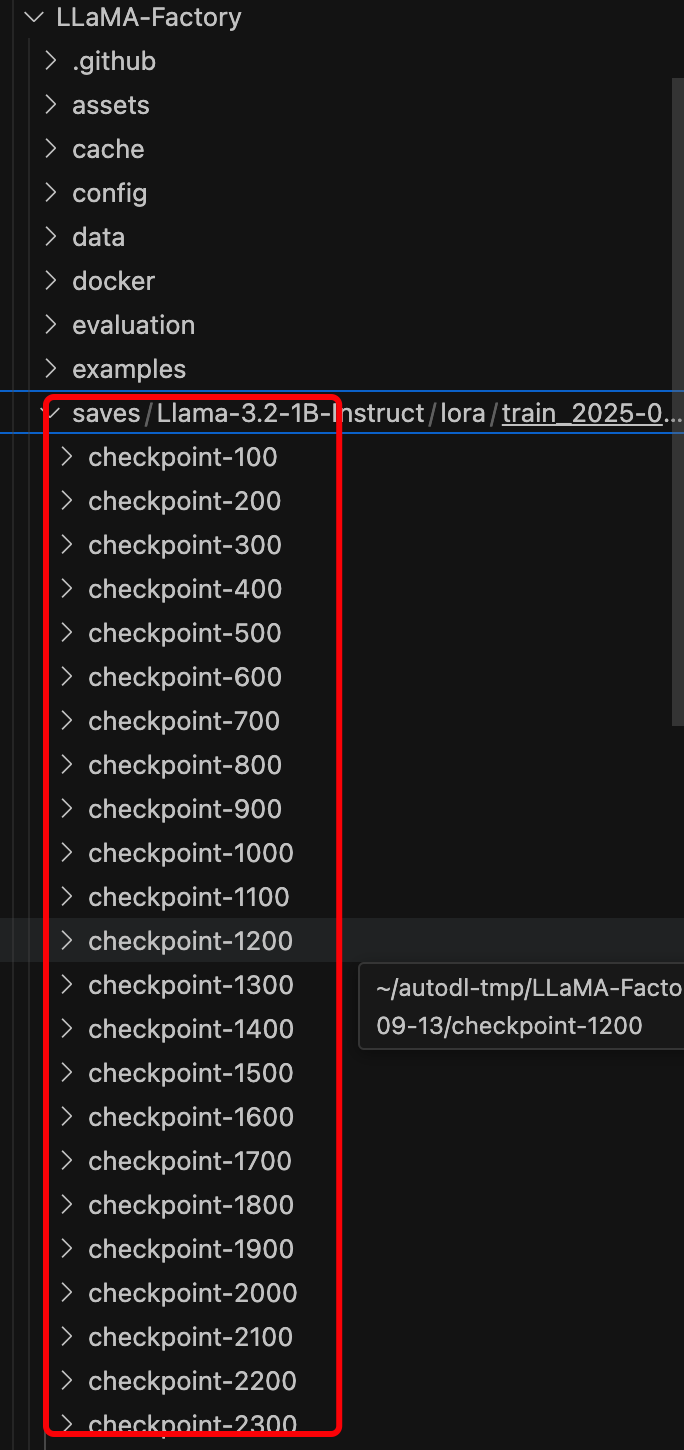
微调方法我们选择 Lora。
检查点路径配置的是再本地服务器 LLamaFactory 下的 save 文件中保存的参数权重,这些参数权重是我们在训练模型时会按照设置步长所保存的权重(模型训练结束之后就能看到这些文件夹,里面保存的是模型参数),如下图:
什么是模型训练迭代的步长(训练步数)
训练步数指模型在整个训练过程中参数更新的总次数。每更新一次参数,称为一个 “训练步”(Step)。
计算方式:总训练步数=(样本总数×训练轮数Epoch)/批次大小Batch Size
示例:
- 数据集有 10,000 个样本。
- 训练 2 个 Epoch(每个样本被使用 2 次)。
- 批次大小为 32。
则总训练步数为:(10000*2)/32 约为 625 步 ,即参数更新 625 次作用:
- 控制训练的总迭代次数,影响模型的收敛程度。
- 与 Epoch 的关系:Epoch 是遍历整个数据集的次数,而 Step 是按批次更新的次数。
混淆点:为什么容易混淆?
学习率的英文有时也被称为 “Step Size”(如在梯度下降中),强调每次更新的 “步长”。
训练步数的英文是 “Training Steps”,强调迭代次数。
两者都与优化过程相关,但含义完全不同。
** 如何避免混淆?**
看上下文:
- 如果讨论优化算法的参数(如 Adam、SGD),步长通常指学习率。
- 如果讨论训练流程的配置(如总迭代次数),步长通常指训练步数。
明确术语:
- 使用 “学习率” 代替 “步长” 描述优化器参数。
- 使用 “训练步数” 或 “迭代次数” 描述更新次数。
理解这两个概念的区别对调参和训练效率至关重要。
- 学习率过大可能导致模型无法收敛。
- 训练步数不足可能导致模型欠拟合。
5.3.1 Full Fine-tuning(全量微调)
参数更新范围:更新预训练模型的所有参数(权重和偏置)。
原理:将预训练模型在新的数据集上重新训练,允许模型根据新数据调整所有内部表示。
优势:
- 理论上能获得最佳性能,尤其当新任务与预训练任务差异较大时。
- 充分利用模型的全部表达能力。
劣势:
- 计算成本极高:需要存储和更新所有参数的梯度,显存占用大。
- 容易过拟合:若新数据集较小,可能导致模型遗忘预训练知识。
适用场景:
- 有大量高质量标注数据。
- 计算资源充足(如多 GPU/TPU 集群)。
- 任务与预训练任务差异显著(如从通用语言模型微调为医学问答模型)。
5.3.2 Freeze Fine-tuning(冻结微调)
参数更新范围:冻结大部分预训练参数,只更新最后几层(如分类头)或特定模块。
原理:利用预训练模型的底层特征提取能力,仅调整上层结构以适应新任务。
优势:
- 显存占用小:只需更新少量参数,适合资源有限的场景。
- 训练速度快:计算量显著减少。
- 缓解过拟合:保留预训练知识,仅针对新任务微调上层。
劣势:
- 性能上限较低,尤其当新任务与预训练任务差异较大时。
适用场景:
- 数据量有限。
- 希望快速验证模型在新任务上的可行性。
- 任务与预训练任务高度相关(如领域适应,从通用文本到法律文本)。
5.3.3 LoRA(Low-Rank Adaptation,低秩适应)
参数更新范围:不直接更新原模型参数,而是通过添加少量可训练的低秩矩阵来间接调整模型行为。
原理:
- 对于权重矩阵 W∈Rd×k,分解为 W+ΔW=W+B⋅A,其中 B∈Rd×r 和 A∈Rr×k 是低秩矩阵(r≪d,k)。
- 仅训练 B 和 A,而原权重 W 保持冻结。
优势:
- 参数效率极高:仅需存储和训练少量额外参数(通常为原模型的 0.01%~1%)。
- 显存占用极小:适合在单 GPU 上微调大型模型(如 7B/13B 参数模型)。
- 支持快速切换任务:不同任务的 LoRA 权重可独立保存,共享基础模型。
劣势:
- 需额外实现 LoRA 的权重合并逻辑(推理时将 W 和 ΔW 合并)。
适用场景:
- 资源受限环境(如单 GPU、边缘设备)。
- 多任务微调(每个任务保存独立的 LoRA 权重)。
- 与 Full Fine-tuning 效果接近,但成本显著降低。
5.4 量化等级、量化方法、提示模板、RoPE插值方法、加速方式

一般情况下这里是不用动的。
5.4.1 模型量化(Model Quantization)
模型量化是一种通过减少模型参数和计算过程中的数值精度,从而降低模型大小和计算复杂度的技术。深度学习模型通常使用 32 位浮点数(FP32)进行训练,但在推理阶段可以用更低的精度表示而不会显著损失精度。
5.4.2 量化等级
| 化等级 | 位宽 | 表示方式 | 说明 |
|---|---|---|---|
| FP32 | 32 位 | 单精度浮点数 | 原始模型精度,存储和计算成本最高 |
| FP16 | 16 位 | 半精度浮点数 | 精度损失较小,计算效率提升显著 |
| BF16 | 16 位 | Brain Floating Point | 类似 FP16 但保留更多指数位,适合深度学习 |
| INT8 | 8 位 | 整数 | 最常见的低精度量化,部分硬件有专用加速 |
| INT4 | 4 位 | 整数 | 更高压缩率,但精度损失明显 |
| INT2/INT1 | 2/1 位 | 整数 | 极端压缩,仅适用于简单任务或特殊场景 |
5.4.3 量化方法
1. BNB (BitsAndBytes)
核心特点:
- 专为大模型设计:支持 INT8/INT4 量化,在保持较高精度的同时大幅降低显存需求。
- 双量化技术:通过量化量化参数本身,进一步减少内存占用。
- 混合精度计算:权重用低比特表示,计算时动态恢复为更高精度(如 FP16/BF16),平衡精度与速度。
适用场景:
- 大语言模型(如 LLaMA-7B/13B)在单 GPU 上的部署。
2. HQQ (High Quality Quantization)
核心特点:
- 极致压缩:支持 INT3/INT2 超低位宽量化,模型大小可压缩至原始的 1/8 甚至 1/16。
- 自适应量化策略:根据权重分布动态调整量化参数,减少信息损失。
- 量化感知微调:提供微调工具,进一步提升低位宽模型的性能。
适用场景:
- 对模型体积敏感的场景(如边缘设备部署)。
- 需要在极低比特下保持相对较高精度的任务。
3. EETQ (Efficient Exact Tensor Quantization)
核心特点:
- 高精度保持:通过误差补偿机制和张量分解技术,在低位宽下仍能保持接近浮点精度的计算结果。
- 硬件感知优化:针对不同硬件架构(如 CPU/GPU/ASIC)生成最优量化方案。
- 精确量化计算:确保量化后的计算结果与浮点计算高度接近。
适用场景:
- 对精度要求极高的科学计算、金融推理等领域。
- 需要严格控制量化误差的场景
| 方案 | 最低量化位宽 | 压缩率 | 精度保持 | 计算效率 | 典型应用 |
|---|---|---|---|---|---|
| BNB | INT4 | 4-8 倍 | 高 | 高 | LLM 高效部署 |
| HQQ | INT2 | 16 倍 | 中 | 中 | 边缘设备极致压缩 |
| EETQ | INT4 | 4 倍 | 极高 | 中 | 高精度科学计算 |
建议:
- 优先使用 BNB:对于大多数 LLM 部署场景,BNB 的 INT4 量化在精度和效率上取得较好平衡。
- 尝试 HQQ:若需要极致压缩(如模型需通过网络频繁传输),可考虑 HQQ 的 INT3/INT2。
- 选择 EETQ:仅在对精度要求苛刻且能接受一定计算开销时使用。
5.4.4 加速方式
- auto:自动选择最佳的加速方式。
- flashattn2:全称是FlashAttention,2是指第二代,FlashAttention的主要作用是全面降低显存读写,旨在减少计算复杂度并加快推理速度。
- unsloth:开源的加速微调项目,地址:https: / github.com/unslothai/unsloth
- liger_kernel:也是加速训练的项目,地址: https: / github.com/linkedin/Liger-Kerne
5.5 Train
5.5.1 Train
1.训练阶段
1)、基础训练阶段
(1). 预训练(Pre-Training)
目标:
在大规模无标注文本(如网页、书籍)上训练基础语言模型,学习通用语言表示。特点:
- 计算成本极高(如 LLaMA-7B 训练需数千 GPU 小时)。
- 模型参数全部可训练。
LLaMAFactory 配置:
- 需指定海量语料库路径。
- 通常使用 AdamW 优化器,学习率约 1e-4。
(2). 监督微调(Supervised Fine-Tuning, SFT)
目标:
使用标注好的指令 - 响应数据(如 {"指令": "写一首诗", "响应": "床前明月光..."})微调预训练模型,使其遵循人类意图。特点:
- 数据量通常较小(数万至数十万样本)。
- 可使用全量微调或参数高效微调(如 LoRA)。
LLaMAFactory 配置:
- 学习率:5e-5(LoRA)或 1e-5(全量)。
- 训练轮数:3-5 轮。
2)、强化学习训练阶段
(3). 奖励模型训练(Reward Modeling, RM)
目标:
训练一个奖励模型,对模型生成的不同回答进行评分(如人类更喜欢回答 A 而非 B)。流程:
- 收集同一问题的多个回答。
- 人类标注偏好排序(如 A>B>C)。
- 训练奖励模型预测这种偏好。
LLaMAFactory 配置:
- 输入:问题 + 多个回答的排序数据。
- 输出:奖励分数(标量值)。
(4). 近端策略优化(Proximal Policy Optimization, PPO)
目标:
使用奖励模型的反馈,通过强化学习进一步优化 SFT 模型,使其生成更符合人类偏好的回答。特点:
- 基于策略梯度的强化学习算法。
- 引入 KL 散度惩罚,防止模型参数更新过大。
LLaMAFactory 配置:
- 需预训练好的奖励模型。
- 关键参数:KL 惩罚系数(通常 0.1-0.5)、学习率(1e-6-1e-5)。
(5). 直接偏好优化(Direct Preference Optimization, DPO)
目标:
直接从人类偏好数据中学习,无需显式训练奖励模型,简化 RLHF 流程。优势:
- 训练效率更高(减少一个训练阶段)。
- 理论上能更好地利用偏好数据。
LLaMAFactory 配置:
- 输入:与 RM 相同的偏好排序数据。
- 直接优化策略模型,无需中间奖励模型。
(6). 知识蒸馏优化(Knowledge Transfer Optimization, KTO)
目标:
将大型教师模型的知识蒸馏到小型学生模型中,实现模型压缩。流程:
- 使用大型模型(如 LLaMA-7B)作为教师。
- 训练小型模型(如 LLaMA-1.3B)模仿教师的输出分布。
LLaMAFactory 配置:
- 需同时加载教师和学生模型。
- 损失函数:交叉熵(预测结果与教师输出)。
2.数据路径与数据集
默认data路径,在数据集中可以多选data路径下的数据集。要想自己的数据能在这里被选到要在LLamaFactory的data路径下的data_info.json下把你的数据json配置上。
3.学习率**(Learning Rate)**
作用:控制参数更新步长,影响收敛速度和稳定性。
典型值:
- 全量微调:
5e-5 ~ 1e-4 - LoRA 微调:
1e-4 ~ 5e-3
- 全量微调:
调优:
- 若损失震荡:降低学习率;
- 若收敛缓慢:适当提高学习率。
4.训练轮数**(Epochs)**
作用:模型对整个数据集的遍历次数。
典型值:
- 预训练:10~100 轮
- 微调:3~10 轮
调优:
- 通过验证集损失动态调整,避免过拟合(如早停策略)。
5.最大梯度范数**(Max Gradient Norm)**
- 作用:梯度裁剪阈值,防止梯度爆炸。
- 典型值:1.0~5.0
6.最大样本数
作用:限制参与训练的样本总量(用于快速验证或资源有限场景)。
示例:
- 设为
10000时,仅使用前 10k 条样本。
- 设为
影响:
- 过小:模型欠拟合;过大:训练时间延长。
7.计算类型**(Compute Type)**

作用:控制训练时的数值精度,影响显存和速度。
选项:
fp32:全精度(默认)fp16:半精度(需混合精度训练)bf16:Brain Floating Point(适合 LLM,NVIDIA Ampere 及以上)
8.截断长度**(Max Sequence Length)**
用:限制输入序列的最大 token 数,影响长文本处理能力。
典型值:
- 标准模型:2048
- 长文本模型:8192~131072(如 LLaMA-3)
注意:
- 过长会显著增加显存消耗(复杂度为 O (n²))。
9.批处理大小**(Batch Size)**
作用:单次前向 / 反向传播的样本数,影响显存占用和收敛稳定性。
典型值:
- 单 GPU(7B 模型):8~64
- 多 GPU:64~512
调优:
- 显存不足时:减小 Batch Size 并增大梯度累计步数。
10.梯度累计
- 作用:分批次计算梯度并累加,等效实现更大 Batch Size。
- **公式:**等效Batch Size = 实际Batch Size × 梯度累计步数
11.验证集比例
- 作用:从训练数据中划分验证集,评估模型泛化能力。
- 典型值:0.1~0.2(即 10%~20% 数据用于验证)。
12.学习率调节器

| 策略 | 特点 | 适用场景 |
|---|---|---|
| 固定学习率 | 全程保持恒定学习率 | 简单任务或调试 |
| Warmup | 训练初期逐步提升学习率(如前 10% 步数),避免冷启动不稳定 | 所有场景(必用) |
| 余弦衰减 | 学习率随训练进程按余弦曲线衰减 | 大多数场景 |
| 阶梯衰减 | 每隔固定步数突然降低学习率(如每 5k 步降为 1/10) | 需要快速收敛的场景 |
LLaMA 微调推荐配置
# Hugging Face实现Warmup+余弦衰减
from transformers import get_cosine_schedule_with_warmup
optimizer = AdamW(model.parameters(), lr=5e-5)
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=1000, # 前1000步为Warmup
num_training_steps=total_steps
)
5.5.2 其他参数设置
- 日志间隔:设定每隔多少步输出一次日志就是终端窗口窗口每隔多少步(steps)打印一次训练的日志。
- 保存间隔:用于定期保存模型参数以防止意外丢失训练成果。
- 预热步数:在训练过程中,学习率逐步增加到初始设定值之前的步数。
- NEFTune噪声参数:嵌入向量所添加的噪声大小,用于正则化和提升模型泛化能力。
5.5.3 部分参数微调设置

这里我们一般不动。
- 可训练层数:控制模型中可以进行训练的层数。在微调过程中,你可以选择只对模型的部分层级进行训练,而不是全部。这可能是因为你想保留预训练模型的一些知识,或者因为你的数据集较小,全量训练可能导致过拟合。
- 可训模块:在这个文本框中,你可以指定要训练的具体模块名称。如果输入"all",则表示所有模块都将被训练。否则,你需要提供一个逗号分隔的列表来指明哪些模块需要训练。这在一些复杂的模型结构中非常有用,比如Transformer模型,其中包含多个不同的组件,如自注意力层、多头注意力层等。通过选择特定的模块进行训练,你可以更好地控制模型的学习过程,避免过度训练某些部分并提高效率。
- 额外模块(非必须域): 这个字段允许你添加除隐藏层之外的其他可训练模块。这些可能是模型中的特殊组件,如嵌入层、池化层或其他特定于任务的层。如果你想要微调的模块不是默认的隐藏层,那么在这里列出它们可以帮助你精确地控制哪些部分应该被更新。
5.5.4 LoRA 参数设置

这里比较重要我们后面会有专门的文章解读这里的配置。
5.5.5 RLHF 参数设置

5.5.6 多模态参数设置

5.5.7 GaLore参数设置

5.5.8 APOLLO参数设置

5.5.9 BAdam参数设置

5.5.10 SwanLab参数设置

5.6 Evluate&Predict
这儿是测试集的配置,可以用作模型评估。
5.7 Chat
这里可以调用我们配置的模型,如果我们既配置了模型路径,又配置了检查点路径,那么在这里我们对话的模型就是我们训练好的基座模型。
推理引擎建议选择 vllm,比 huggingface快。

5.8 Export

Export模块是用于导出训练好的模型。lora 不能单独存在,因此我们需要吧基座模型和训练好的权重一起打包打出使其成为新的模型,导出的模型可以作为基座模型再训练。
注意导出模型的时候尽量不要选导出旧格式,旧格式指的是老的模型格式,现在基本不会用了。
- 最大分块大小:用于设置导出文件的最大大小。这对于上传到某些平台(如Hugging Face Hub)有限制的文件大小很有用。你可以调整此值以确保导出的文件不会超过所选的最大大小。
- 导出量化等级:选择是否要对模型进行量化。选择 “none” 表示不进行量化,而选择其他选项可能会导致模型尺寸减小,但在某些情况下可能会影响准确率。
- 导出量化数据集:如果选择了量化级别,可以在这里选择用于量化评估的数据集。这通常是训练或验证数据的一个子集,用于评估和微调量化后的模型性能。
- 导出设备:选择模型将被导出到什么类型的设备上。CPU选项表示模型将被优化以在CPU上运行,而auto选项让系统自动决定最适合的设备类型。这取决于你的目标环境和可用硬件。
- 不使用safetensors格式保存模型: 这个复选框用于选择是否使用safetensors格式保存模型。safetensors是一种安全的张量格式,可以保护模型免受恶意攻击。取消勾选该选项表示将使用标准格式保存模型。 导出目录: 在这里,你可以指定一个路径来保存导出的模型文件。这是模型及其相关文件将被保存的位置。
- HF Hub ID: 如果你想将模型上传到Hugging Face Hub,你可以在此处输入仓库ID。这是一个可选字段,如果你不想上传模型,则可以留空。
六、需要看懂的参数
6.1 LIama3输出的参数
Model config LlamaConfig {
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": [
128001,
128008,
128009
],
"head_dim": 64,
"hidden_act": "silu",
"hidden_size": 2048,
"initializer_range": 0.02,
"intermediate_size": 8192,
"max_position_embeddings": 131072,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 16,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": {
"factor": 32.0,
"high_freq_factor": 4.0,
"low_freq_factor": 1.0,
"original_max_position_embeddings": 8192,
"rope_type": "llama3"
},
"rope_theta": 500000.0,
"tie_word_embeddings": true,
"torch_dtype": "bfloat16",
"transformers_version": "4.48.2",
"use_cache": true,
"vocab_size": 128256
}
【模型架构与类型】architectures:指定模型类型为自回归语言模型,通过前文预测下一个 token。
【注意力机制参数】attention_bias:注意力层不使用偏置项(bias),减少参数量。
【注意力机制参数】attention_dropout:注意力层不应用 dropout(丢弃率为 0),提升训练稳定性。
【词汇表与特殊 Token】bos_token_id:文本开始标记(Begin of Sequence)的 token ID 为 128000。
【词汇表与特殊 Token】eos_token_id:文本结束标记(End of Sequence)有多个候选 ID,模型可能根据不同场景使用不同的结束标记。
【注意力机制参数】head_dim:每个注意力头的维度为 64,总注意力维度 = 32×64 = 2048。
【模型规模与结构】hidden_act:隐藏层激活函数使用 SiLU(Swish),数学表达式为
x * sigmoid(x)。【模型规模与结构】hidden_size:Transformer 层的隐藏层维度为 2048,对应约 7B 参数量级。
【归一化与初始化】initializer_range:权重初始化的标准差为 0.02(遵循标准正态分布)。
【模型规模与结构】intermediate_size:MLP 层的中间维度,通常为 hidden_size 的 4 倍(2048×4=8192)。
【位置编码与上下文长度】max_position_embeddings:模型支持的最大上下文长度为 131,072 tokens(约 100 万字)。
【模型规模与结构】mlp_bias:MLP 层不使用偏置项,减少参数量。
【模型架构与类型】model_type:表明采用 Llama 架构,使用 Llama 特有的层归一化、激活函数等设计。
【注意力机制参数】num_attention_heads:注意力头数量为 32 个,并行处理不同子空间的信息。
【模型规模与结构】num_hidden_layers:模型共有 16 层 Transformer 块。
【注意力机制参数】num_key_value_heads:采用 Grouped Query Attention (GQA),使用 8 个 KV 头降低内存消耗(Llama 3 优化)。
【归一化与初始化】pretraining_tp:预训练时不使用张量并行(tensor parallelism),值为 1 表示单设备训练。
【归一化与初始化】rms_norm_eps:RMSNorm 层的稳定性参数,防止数值计算时除以接近零的方差。
【位置编码与上下文长度】rope_scaling:Llama 3 改进的旋转位置编码(RoPE)缩放机制:
- factor=32.0:将原始 Llama 的 8192 tokens 上下文扩展 32 倍至 131K。
- high_freq_factor=4.0:高频位置编码的缩放因子(优化长序列外推)。
- low_freq_factor=1.0:低频位置编码保持不变。
- rope_type="llama3":使用 Llama 3 特有的 RoPE 实现。
【位置编码与上下文长度】rope_theta:RoPE 的基础频率参数,增大至 500K(原始 Llama 为 10,000),提升长序列建模能力。
【量化与版本信息】tie_word_embeddings:共享输入和输出词嵌入矩阵(减少参数量)。
【量化与版本信息】torch_dtype:使用 bfloat16 数据类型训练,相比 FP16 更稳定(适合大模型)。
【注意力机制参数】use_cache:启用 KV 缓存,加速推理阶段的自回归生成(保存历史 key/value 矩阵)。
【词汇表与特殊 Token】vocab_size:词汇表大小为 128,256,支持更丰富的 token 表示(大于标准 Llama 2 的 32K)。
6.2 LLamaFactory输出的参数
Num examples = 10
- 表示用于训练的样本总数为 10 条。这是你提供给模型进行学习的所有数据量。
Batch size = 10
- 表示每个训练批次包含 10 个样本。结合上面的 Num examples=10 来看,这里一个 epoch 只需要一个 batch 就能完成所有样本的训练。
loss
- 损失值
- 含义:衡量模型预测结果与真实标签之间的差异程度。损失值越低,模型预测越准确。
- 计算方式:常见的损失函数如交叉熵损失(用于分类任务)、均方误差(用于回归任务)等。
- 训练趋势:理想情况下,随着训练进行,loss 应逐渐下降并趋于稳定。若 loss 波动较大或不降反升,可能表示学习率设置不当或模型过拟合。
epoch
- 轮次
- 含义:一个 epoch 表示模型完整地遍历了一次训练数据。
- 与 Batch 的关系:若总样本数为 N,batch size 为 B,则一个 epoch 需要 N/B 个 batch。在你的例子中,10 个样本,batch size=10,因此每个 epoch 只需 1 个 batch。
- 训练策略:通常需要多个 epoch 来让模型充分学习数据特征,但过多的 epoch 可能导致过拟合。
throughput
- 吞吐量
- 含义:表示单位时间内模型处理的样本数量,通常以 “样本 / 秒” 为单位。
- 计算公式:吞吐量 = 处理的总样本数 / 总耗时。例如,若一个 epoch 处理 10 个样本耗时 2 秒,则吞吐量为 5 样本 / 秒。
- 意义:反映训练效率,吞吐量越高,说明模型在硬件上的运行效率越高,训练速度越快。
6.3 看懂折线图
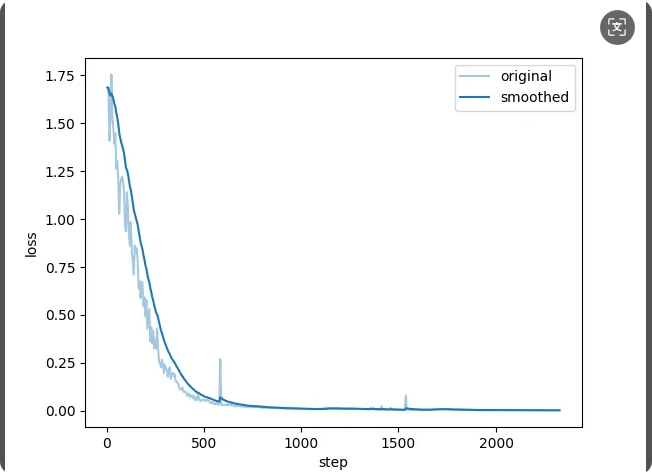
6.3.1基本概念
1. Original(原始值)
定义:模型在每个训练步骤(step)中直接计算得到的未经过处理的原始指标值。
特点:
- 反映模型在当前批次数据上的即时表现。
- 波动较大,尤其是在小批量训练或学习率较高时,可能包含噪声。
2. Smoothed(平滑值)
定义:通过某种平滑算法(如指数移动平均 EMA)对原始值进行处理后得到的指标值。
特点:
- 抑制短期波动,展示指标的长期趋势。
- 更适合判断模型是否真正收敛或过拟合。
6.3.2如何查看和解读
1. Loss 曲线对比
Original Loss:
若原始损失曲线剧烈波动,可能表示:- 学习率设置过高,模型参数更新不稳定。
- 批次数据分布不均匀(如样本难度差异大)。
Smoothed Loss:
观察平滑损失的趋势:- 若持续下降,说明模型仍在学习。
- 若趋于稳定,可能接近收敛。
- 若开始上升,可能出现过拟合(尤其当原始损失仍在下降时)。
2.结论
| 指标 | 优势 | 适用场景 |
|---|---|---|
| Original | 反映即时性能,检测训练异常 | 调试学习率、排查数据问题 |
| Smoothed | 展示长期趋势,判断收敛与过拟合 | 评估模型整体训练效果、确定训练终止点 |
你应该懂的AI大模型(十)之 LLamaFactory 之 LoRA微调Llama3的更多相关文章
- AI大模型学习了解
# 百度文心 上线时间:2019年3月 官方介绍:https://wenxin.baidu.com/ 发布地点: 参考资料: 2600亿!全球最大中文单体模型鹏城-百度·文心发布 # 华为盘古 上线时 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- PowerDesigner 学习:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- PowerDesigner 15学习笔记:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- HBase实践案例:知乎 AI 用户模型服务性能优化实践
用户模型简介 知乎 AI 用户模型服务于知乎两亿多用户,主要为首页.推荐.广告.知识服务.想法.关注页等业务场景提供数据和服务, 例如首页个性化 Feed 的召回和排序.相关回答等用到的用户长期兴趣特 ...
- zz独家专访AI大神贾扬清:我为什么选择加入阿里巴巴?
独家专访AI大神贾扬清:我为什么选择加入阿里巴巴? Natalie.Cai 拥有的都是侥幸,失去的都是人生 关注她 5 人赞同了该文章 本文由 「AI前线」原创,原文链接:独家专访AI大神贾扬清:我 ...
- 阿里开源新一代 AI 算法模型,由达摩院90后科学家研发
最炫的技术新知.最热门的大咖公开课.最有趣的开发者活动.最实用的工具干货,就在<开发者必读>! 每日集成开发者社区精品内容,你身边的技术资讯管家. 每日头条 阿里开源新一代 AI 算法模型 ...
- 搭乘“AI大数据”快车,肌肤管家,助力美业数字化发展
经过疫情的发酵,加速推动各行各业进入数据时代的步伐.美业,一个通过自身技术.产品让用户变美的行业,在AI大数据的加持下表现尤为突出. 对于美妆护肤企业来说,一边是进入存量市场,一边是疫后的复苏期,一边 ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
随机推荐
- 我对TamperMonkey的不满-更新中
我认为我的电脑上的TamperMonkey插件的值得考虑的不足: 没有提供一个把脚本最小化的功能 不能编辑热键 脚本icon不能使用svg 没有提供一种很好的能够区分别人的脚本和自己的脚本的方式,自己 ...
- Linux系统中的目录和文件夹的区别
Linux系统中的目录和文件夹的区别 目录 Linux系统中的目录和文件夹的区别 一.概念与术语背景 1.目录(Directory) 2.文件夹(Folder) 二.技术实现差异 1.存储内容 2.权 ...
- idhttp的socket error # 10054 错误的处理办法
在通过http实现restful数据通讯时,死活出现: socket error # 10054 导致这种情况的原因很复杂. 同样的程序,在不同的环境中出现不同结果. 通过观察,发现登录后获取toke ...
- MySurvey 问卷调查, 一个简单的Biwen.QuickApi示例项目
MySurvey 项目 很久没更新我的博客了,之前开发的Biwen.QuickApi微框架 一直没有开发一个示例项目,最近有点时间,写了一个示例项目稍微介绍下 项目简介 这是一个基于 Biwen.Qu ...
- Codeforces Round 970 (Div. 3)
A. Sakurako's Exam 分类讨论即可,当a为奇数,无法消去1,或者a==0且b为奇数时,无法消去2 #include <bits/stdc++.h> using namesp ...
- spring cloud alibaba的小坑:Caused by: com.alibaba.nacos.api.exception.NacosException: endpoint is blank报错问题,
一.是因为加添spring cloud alibaba配置中心依赖和bootstrap.xml又不使用的问题
- 🎀idea获取当前项目git仓库地址
简介 在idea中快速获取当前项目的远程仓库地址 方案一 右键项目 选择Git 选择Manage Remotes 弹框中的URL就是远程仓库地址 方案二 打开terminal 命令行 直接Git命令查 ...
- 探秘Transformer系列之(27)--- MQA & GQA
探秘Transformer系列之(27)--- MQA & GQA 目录 探秘Transformer系列之(27)--- MQA & GQA 0x00 概述 0x01 MHA 1.1 ...
- git 更新和强制更新失败
Your local changes to the following files would be overwritten by mergeerror: Your local changes to ...
- 【工具】SageMath|Ubuntu 22 下 SageMath 安装和一般数域筛法代码示例(2024年)
就一个终端就能运行的东西, 网上写教程写那么长, 稍微短点的要么是没链接只有截图.要么是链接给的不到位, 就这,不是耽误生命吗. 废话就到这里. 文章目录 链接 步骤 链接 参考: Install S ...