KES的执行计划分析与索引优化
今天我们继续探讨国产数据库KES的相关内容,本次的讨论重点将放在SQL优化的细节上。作为Java开发人员,我们通常并不需要深入了解数据库的底层实现细节,而是更多地关注如何提升应用性能与数据库的交互效率。具体来说,工作中我们常常需要关注的优化策略包括查看SQL的执行计划和合理地建立索引。
今天我们就从这两个方面深入讨论一下相关的优化技巧。如果你希望了解更深入的内容,建议阅读KES数据库的官方文档,里面涵盖了更多的最佳实践和细节说明:https://bbs.kingbase.com.cn/docHtml?recId=d16e9a1be637c8fe4644c2c82fe16444&url=aHR0cHM6Ly9iYnMua2luZ2Jhc2UuY29tLmNuL2tpbmdiYXNlLWRvYy92OS9wZXJmb3Ivc3FsLW9wdGltaXphdGlvbi9pbmRleC5odG1s
环境准备
好的,首先,我已经在本地成功安装了KES数据库,为了确保接下来的操作顺利进行,我们首先需要准备好一些基础的数据表以及相应的数据。命令如下:
create table t1(id int, val int, name varchar(64));
create table t2(id int, val int);
create index t1_idx on t1(id);
create index t2_idx on t2(id);
insert into t1 select i, i%5000, CONCAT('Kingbase',(i%5)) from generate_series(1,3000000) as x(i);
insert into t2 select i, i%5000 from generate_series(1,1000000) as x(i);
为防止并行影响测试结果,以下所有示例结果是在关闭并行扫描的前提下进行,命令如下:
set max_parallel_workers_per_gather = 0;
执行计划
作为开发人员,我们与执行计划的接触是最为频繁的。尽管我们编写的 SQL 查询在功能上是可用的,但与程序代码不同,数据库的性能压力会受到 SQL 查询效率的显著影响。因此,在我们将 SQL 查询部署到生产环境之前,通常会仔细分析执行计划,确保查询的高效性。否则,一个不优化的慢查询不仅可能影响到单一业务模块的性能,更有可能波及到整个系统,导致性能瓶颈,影响用户体验,甚至影响系统的稳定性。
KingbaseES中explain命令来查看执行计划时最常用的方式。其命令格式如下:
explain [option] statement
其中option为可选项,可以是以下5种情况的组合:
- analyze:执行命令并显示执行事件,默认false(更新语句计划慎用)
- verbose:显示附加信息,比如计划树中每个节点输出的字段名等,默认false
- costs:显示执行计划的成本,默认true
- buffers:显示缓冲区的使用信息,包括共享快、本地块和临时读写块,默认false,前置条件是analyze
- format:指定执行计划的输出格式,支持:TEXT、XML、JSON或者YAML,默认是text
分析执行计划
关于analyze之前说过,我们简单了解下如何分析下explain结果。
explain analyze select * from
t1t whereid=555;
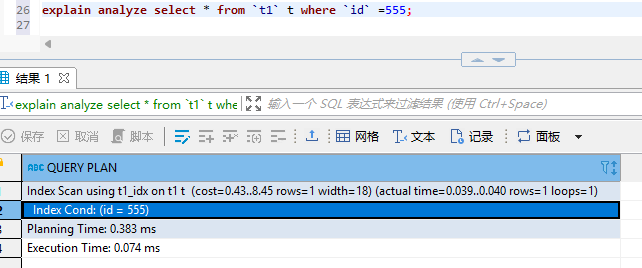
- 执行动作:Index Scan using t1_idx on t1
- Index Scan表示索引扫描,还有一种是Seq Scan代表全表扫描。t1_idx为索引名称。
- 估算成本:(cost=0.43..8.45 rows=1 width=18)
- Cost=0.43..8.45:第一个数0.43表示启动成本,也就是说返回第一行需要多少cost。第二个数值8.45表示返回所有的数据的成本。这两个数值用..分开。
- 实际成本:(actual time=0.039..0.040 rows=1 loops=1)
- 只有启动analyze 时才会有。Rows=1:表示实际查询返回了1行记录。Loops=1:表示该索引扫描只执行了1次。
- 索引条件:Index Cond: (id = 555)
- 代表哪个检索条件命中了索引。
会看执行计划了,我们基本就不会犯特别大的错误。接下来,我们看下索引部分。
索引
在数据库优化中,索引是提高查询效率的关键手段。常见的普通索引和主键索引在此不再赘述,这些类型的索引一般用于对常见查询字段进行优化。
然而,除了这些常见的索引类型之外,还有一些较为特殊的索引类型,对于某些复杂或不常见的查询条件,可能会带来更好的性能提升。接下来,我们将介绍一些不那么常见的索引类型,建议在遇到复杂查询或特殊查询需求时,尝试应用这些索引方式,以便更好地优化数据库的查询效率。
表达式索引
我们通常知道,如果一个查询条件加了函数的话,那么这个索引是肯定无法命中的。所以,在KES也有相应的处理方法,给函数也加上索引。如下所示:
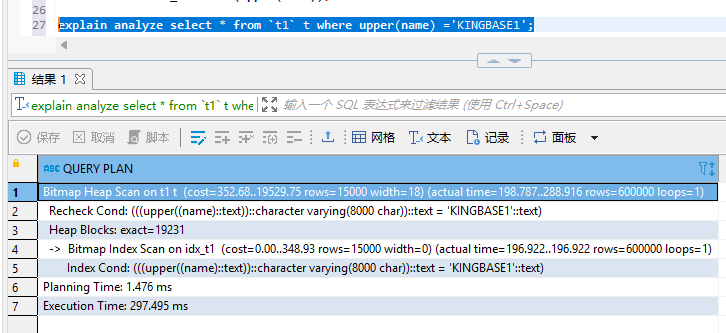
create index idx_t1 on t1(upper(name));
比如数据库内存储的是包含大小写的字母,但是用户在搜索的时候很难真的将大小写写正确,所以我们直接全都按照大写处理,这样就可以正常匹配数据了。效果对比如图所示:
未建立索引情况下如下:
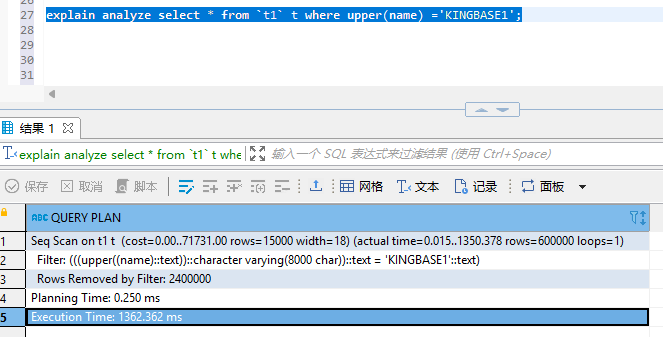
建立索引后,情况如下:
like后匹配索引
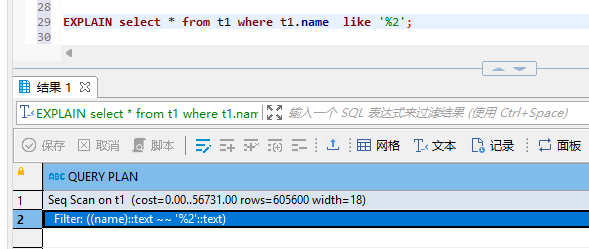
正常情况下,不管是联合索引还是like查询都是要满足最左原则的。这理解不介绍了,但是如果我们的like条件是后缀匹配怎么办?如下:
select * from t1 where t1.name like '%2';
直接全表扫描,如图所示:
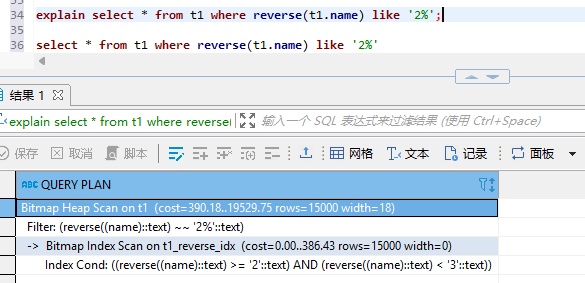
这里给出的解决方案是反转函数,其中Collate 为 "C"的字段做like操作时,也被转换为">= AND <" 的一对索引条件。命令如下:
create index on t1(reverse(name) collate "C");
explain select * from t1 where reverse(t1.name) like '2%';
字符串like ‘%abc’等价于reverse(字符串) like ‘cba%’,将其转换成类似前匹配的方式。效果对比如图所示:
局部索引
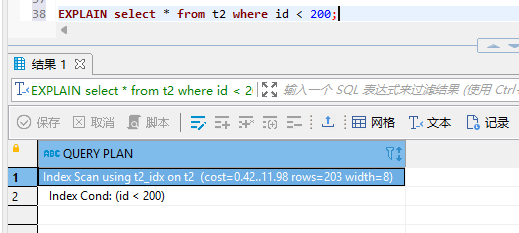
顾名思义,我进进对部分数据做索引,而不是整表数据,如果这部分是热点数据经常被查询,你完全可以使用起来。
create index idx_t2 on t2(id) where id < 500;
效果对比如图所示:
创建后如图所示:
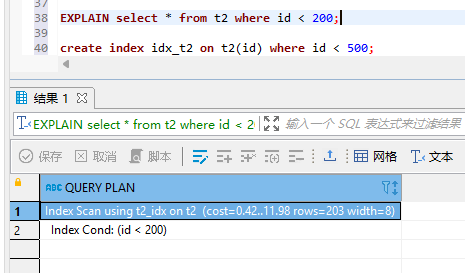
这里基本没啥差别,是因为在演示之前已经有id的全表索引了。
使用HINT
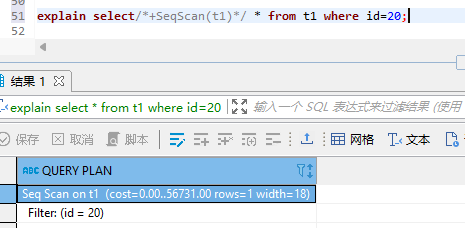
比如,你建立了很多索引在同一个表中,但是执行计划并不是你想用的索引,你个人觉得有问题,那么也可以强制让SQL使用索引,命令如下:
explain select * from t1 where id=20;
set enable_hint = TRUE;
explain select/+seqscan(t1)/ * from t1 where id=20;
因为默认不开启hint,所以我们需要提前开启才生效,效果对比如图所示:
删除不必要的索引
由于开发人员经验以及数据库管理人员暂缺,有时候可能一张表中的索引已成泛滥状态,比如你有一个联合索引,但又有人建立一个重复的单独索引。完全就是浪费空间,并且也增加了插入数据的时间。命令如下:
select relname, indexrelname, idx_scan, idx_tup_read, idx_tup_fetch from sys_stat_user_indexes order by idx_scan, idx_tup_read, idx_tup_fetch;
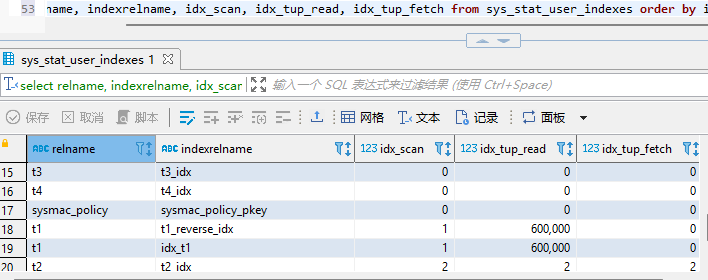
定期vacuum和重建索引
可以通过使用数据库的磁盘空间工具 VACUUM 来优化存储空间,该工具的主要作用是删除那些已经被标记为删除的数据行,并释放相应的磁盘空间。
然而,VACUUM 工具并不会自动清理与这些数据行相关联的索引,因此在执行VACUUM后,索引可能依旧包含冗余数据。这时需要手动重建索引来优化查询性能。
索引重建可以通过以下几种方式进行,具体级别的选择取决于需要操作的范围:
- 数据库级别:通过
REINDEX DATABASE命令,可以重建整个数据库中的所有索引。REINDEX DATABASE d1;
- 表级别:通过
REINDEX TABLE命令,可以重建指定表的所有索引。REINDEX TABLE t1;
- 索引级别:通过
REINDEX INDEX命令,可以重建单个索引。此操作针对特定索引进行优化,适用于仅希望对某个索引进行优化,而不影响其他部分的情形。REINDEX INDEX idx1;
重建索引操作可以有效地减少索引文件的大小,提高查询性能,尤其在数据量较大、删除或更新操作频繁的环境中。
总结
在今天的讨论中,我们深入探讨了国产数据库KES的SQL优化技巧,尤其是执行计划分析和索引优化这两个方面。通过理解和优化SQL查询的执行计划,我们能够显著提高数据库查询的效率,避免不必要的性能瓶颈。作为Java开发人员,尽管我们通常不需要深入到数据库底层的细节,但理解如何通过执行计划优化查询以及合理使用索引,将直接影响到应用性能和用户体验。
通过合理使用不同类型的索引,比如表达式索引、反转索引和局部索引等,我们可以优化查询性能,尤其是在面对复杂或特殊查询需求时。此外,定期对数据库进行维护,诸如删除冗余索引和重建索引,也能有效减少系统负担,保持数据库的高效运行。
总之,虽然数据库优化是一个持续的过程,但通过合理的工具和方法,我们能够确保在KES数据库中进行高效的查询和数据存取,保障应用的稳定性和高效性。如果你希望进一步深入了解优化技巧,官方文档提供了更多的详细信息和最佳实践,值得开发者参考。
我是努力的小雨,一个正经的 Java 东北服务端开发,整天琢磨着 AI 技术这块儿的奥秘。特爱跟人交流技术,喜欢把自己的心得和大家分享。还当上了腾讯云创作之星,阿里云专家博主,华为云云享专家,掘金优秀作者。各种征文、开源比赛的牌子也拿了。
想把我在技术路上走过的弯路和经验全都分享出来,给你们的学习和成长带来点启发,帮一把。
欢迎关注努力的小雨,咱一块儿进步!
KES的执行计划分析与索引优化的更多相关文章
- mysql,存储引擎,事务,锁,慢查询,执行计划分析,sql优化
基础篇:MySql架构与存储引擎 逻辑架构图: 连接层: mysql启动后(可以把mysql类比为一个后台的服务器),等待客户端请求,当请求到来后,mysql建立一个一个线程处理(线程池则分配一个空线 ...
- MySQL学习系列2--MySQL执行计划分析EXPLAIN
原文:MySQL学习系列2--MySQL执行计划分析EXPLAIN 1.Explain语法 EXPLAIN SELECT …… 变体: EXPLAIN EXTENDED SELECT …… 将执行 ...
- MySQL学习系列2--MySQL执行计划分析EXPLAIN [原创]
1.Explain语法 EXPLAIN SELECT …… 变体: EXPLAIN EXTENDED SELECT …… 将执行计划“反编译”成SELECT语句,运行SHOW WARNINGS 可 ...
- MySQL执行计划分析
原文:MySQL执行计划分析 一. 执行计划能告诉我们什么? SQL如何使用索引 联接查询的执行顺序 查询扫描的数据函数 二. 执行计划中的内容 SQL执行计划的输出可能为多行,每一行代表对一个数据库 ...
- MongoDB执行计划分析详解
要保证数据库处于高效.稳定的状态,除了良好的硬件基础.高效高可用的数据库架构.贴合业务的数据模型之外,高效的查询语句也是不可少的.那么,如何查看并判断我们的执行计划呢?我们今天就来谈论下MongoDB ...
- MongoDB干货系列2-MongoDB执行计划分析详解(2)(转载)
写在之前的话 作为近年最为火热的文档型数据库,MongoDB受到了越来越多人的关注,但是由于国内的MongoDB相关技术分享屈指可数,不少朋友向我抱怨无从下手. <MongoDB干货系列> ...
- SQLServer查询执行计划分析 - 案例
SQLServer查询执行计划分析 - 案例 http://pan.baidu.com/s/1pJ0gLjP 包括学习笔记.书.样例库
- Mysql 执行计划以及常见索引问题总结
Mysql 执行计划以及常见索引问题总结
- mysql系列八、mysql数据库优化、慢查询优化、执行计划分析
mysql的性能优化无法一蹴而就,必须一步一步慢慢来,从各个方面进行优化,最终性能就会有大的提升. 一.介绍 对mysql优化是一个综合性的技术,主要包括 表的设计合理化(符合3NF) 添加适当索引( ...
- 记一次SqlServer大表查询语句优化和执行计划分析
数据库: sqlserver2008r2 表: device_data 数据量:2000w行左右 表结构 CREATE TABLE [dbo].[device_data]( [Id] [int] ID ...
随机推荐
- 在C#中基于Semantic Kernel的检索增强生成(RAG)实践
Semantic Kernel简介 玩过大语言模型(LLM)的都知道OpenAI,然后微软Azure也提供了OpenAI的服务:Azure OpenAI,只需要申请到API Key,就可以使用这些AI ...
- IO体系
IO,即in和out,也就是输入和输出,指应用程序和外部设备之间的数据传递,常见的外部设备包括文件.管道.网络连接. Java 中是通过流处理IO 的,那么什么是流? 流(Stream),是一个抽象的 ...
- Machine Learning Week_1 Linear Algebra Review 1-6
目录 4 Linear Algebra Review 4.1 Video: Matrices and Vectors unfamiliar words 4.2 Reading: Matrices an ...
- Python面向对象小备忘
最近学到面向对象了,感觉到Python这方面的语法也有点神奇,这里专门归纳一下Python面向对象中我觉得比较重要的笔记. 本文目前有的内容:实例属性和类属性的访问,使用@property修饰器 实例 ...
- GoLand IDE 如何设置每次打开时先展示启动界面
GoLand IDE 如何设置每次打开时先展示启动界面 打开设置,在SystemSeting下进行如下操作即可
- 用文字“画出”时序图:用 AI+Mermaid.js 解决交互过程中的问题
什么是时序图 序列图是一种用于描述对象之间在时间上的交互顺序的图表. 它可以展示对象之间是如何相互作用的,以及这些交互的顺序. 什么是Mermaid Mermaid.js是一个开源项目,它允许你通过简 ...
- Python基础快速入门
1).Python运算符 1.Python算数运算符 描述: 例子: a = 21 b = 10 c = 0 c = a + b #31 c = a - b #11 c = a * b #210 c ...
- Slate文档编辑器-WrapNode数据结构与操作变换
Slate文档编辑器-WrapNode数据结构与操作变换 在之前我们聊到了一些关于slate富文本引擎的基本概念,并且对基于slate实现文档编辑器的一些插件化能力设计.类型拓展.具体方案等作了探讨, ...
- Flink 实战之 Real-Time DateHistogram
系列文章 Flink 实战之 Real-Time DateHistogram Flink 实战之从 Kafka 到 ES DateHistogram 用于根据日期或时间数据进行分桶聚合统计.它允许你将 ...
- Django admin实现图片上传到腾讯云
官网参考:https://docs.djangoproject.com/zh-hans/3.2/howto/custom-file-storage/ 当前业务需要使用django的admin后台进行数 ...