解锁硬件潜能:Java向量化计算,性能飙升W倍!
机器相关的编译优化
与机器相关的编译优化常见的有指令选择(Instruction Selection)、寄存器分配(Register Allocation)、窥孔优化(Peephole Optimization)等。这些机器级优化通常发生在中间表示向目标代码生成之间的后端编译阶段。
与源代码层面的优化(如循环展开、内联函数)相比,它们更接近硬件,必须考虑具体平台的硬件特性。如指令集结构(如RISC精简指令集 vs CISC复杂指令集);通用寄存器和专用寄存器的数量与类型(如浮点寄存器、向量寄存器);指令延迟、吞吐量与调度约束(如乱序执行和分支预测);特殊硬件功能(如SIMD寄存器、浮点处理单元FPU、图形处理单元GPU))等。
这些机器级优化是编译器架构适配能力的核心体现,直接决定了生成的代码是否能“榨干”硬件的每一分性能。其中,向量化计算是利用现代处理器并行能力的一个突出例子。
向量化计算
向量化计算(Vectorization) 是一种数据级并行(Data-Level Parallelism)的优化技术。它的核心思想是允许处理器在单个操作指令中对一组数据元素(即“向量”或数组片段)同时执行相同的操作,而不是像传统的标量计算(Scalar Computation)那样一次只处理一个数据元素。这种并行处理能力能够显著提高代码的运行效率,尤其是在处理大规模数据集的科学计算、图像处理、机器学习等领域。
向量化计算的性能极大程度上依赖于底层硬件的单指令多数据流(Single Instruction Multiple Data,SIMD)指令集支持。SIMD是现代处理器中的一种特殊硬件单元,它包含比通用寄存器更宽的向量寄存器,以及能够操作这些宽寄存器的特殊指令。
SIMD工作流程主要有三个步骤。
1)数据加载/打包 (Load/Pack): 将内存中连续或按特定模式排列的多个数据元素加载(并可能重新排列)到一个宽大的SIMD寄存器中。
2)并行计算 (Parallel Operation): 使用一条SIMD指令(例如向量加法 VADDPS、向量乘法 VMULPS)对SIMD寄存器中的所有数据元素同时执行指定运算。
3)结果存储/解包 (Store/Unpack): 将SIMD寄存器中包含多个计算结果的向量数据存回内存,或用于后续的SIMD/标量计算。
向量化的能力依赖于底层硬件是否支持SIMD指令集,例如Intel x86架构的 SSE(Streaming SIMD Extensions)、AVX(Advanced Vector Extensions)、AVX-512;ARM 架构的 NEON;Apple 架构的 Accelerate等。
一般来说,越新的SIMD指令集,其支持的向量寄存器宽度越大,能够并行处理的数据元素就越多,功能也越强大。例如,AVX-512的向量寄存器宽度为512位(即64字节),能够一次处理8个双精度浮点数 (double) 或16个单精度浮点数 (float)。AVX-512指令集的提升巨大,不仅因为寄存器宽度翻倍,还引入了掩码寄存器(Masking)、嵌入式广播(Embedded broadcast)、新的算术和置换指令等众多高级功能。
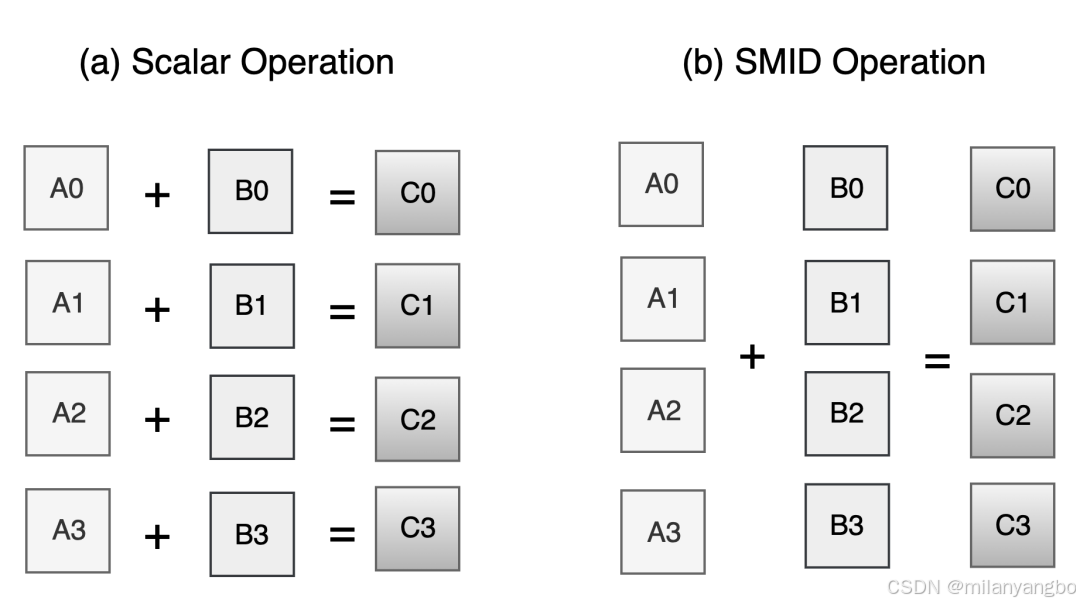
假设有两个数组 A 和 B,想把它们对应元素相加,结果存入数组 C。每个数组有 N 个元素。
非向量化计算伪代码演示:
function scalar_add(A, B, C, N):
// 循环N次,每次处理一对元素
for i from 0 to N-1:
// 每次循环迭代中,处理器取出一对数字(A[i] 和 B[i]),执行一次加法,然后存储结果 C[i]
C[i] = A[i] + B[i] // 单个加法指令作用于单个元素对
// 除了加法指令本身,还有循环控制指令(如索引增加、条件判断、跳转)的开销
向量化计算伪代码演示(假设SIMD寄存器能处理 W 个元素):
function simd_add(A, B, C, N):
// 假设 N 是 W 的倍数,简化演示
// 循环次数减少为 N/W 次
for i from 0 to N-1 step W: // 每次处理 W 个元素
// 1. 加载数据到SIMD寄存器 (一次加载 W 个元素)
vector_reg_A = load_vector_from_memory(address_of A[i], W)
vector_reg_B = load_vector_from_memory(address_of B[i], W)
// 2. 执行SIMD加法 (一条指令完成 W 个元素的加法)
vector_reg_C = simd_add_instruction(vector_reg_A, vector_reg_B)
// 3. 存储结果回内存 (一次存储 W 个元素)
store_vector_to_memory(address_of C[i], W, vector_reg_C)
// 理想情况下,如果SIMD寄存器能处理 W 个元素,理论上可以获得接近 W 倍的速度提升(实际中会因内存带宽、数据依赖等因素有所折扣)
Java虚拟机,如HotSpot的C2编译器,在将向量化优势引入Java代码,主要有自动化向量和显式向量API(Project Panama)两种方式。
自动向量化
这是最常见且透明的方式。即时编译器在运行时分析Java字节码。如果它识别出对数组或集合的元素执行相同操作的循环(且满足一定的安全性和收益性标准),它就可以自动将该循环转换为底层硬件对应的SIMD指令。
// 判断转换为向量化指令的条件:
// 1)无分支或复杂控制流(如 if)
// 2)循环变量和访问范围可静态确定
// 3)无指针别名或内存重叠风险
// 4)操作为“纯函数式”,无副作用
void scaleArray(float[] arr, float factor) {
for (int i = 0; i < arr.length; i++) {
arr[i] = arr[i] * factor; // 简单、独立的操作
}
}
显式向量API
为了让开发者获得更细粒度的控制,并表达自动向量化器可能遗漏的复杂向量计算,Java引入了向量API。该API允许开发人员在Java中显式编写向量化代码。它在几个JDK版本中进行孵化(如JDK 16-21),并在JDK 22(JEP 460)中成为标准功能。
向量API提供了诸如FloatVector, IntVector, DoubleVector 等类,它们代表了与硬件SIMD能力相对应的特定数据类型和大小的向量(称为"species",物种)。开发者可以使用这些类显式地构造向量、执行向量运算,并与Java数组进行数据交换。
import java.util.vector.*; // 假设最终包名为 java.util.vector
void vectorMultiply(float[] arr, float factor) {
// 获取与硬件最匹配的FloatVector种类 (如128位、256位或512位SIMD)
VectorSpecies<Float> species = FloatVector.SPECIES_PREFERRED;
int i = 0;
int loopBound = species.loopBound(arr.length);
// 主循环:处理完整的向量块
for (; i < loopBound; i += species.length()) {
// 从数组加载数据到向量
FloatVector vec_arr = FloatVector.fromArray(species, arr, i);
// 执行向量乘法 (所有元素乘以factor)
FloatVector vec_result = vec_arr.mul(factor);
// 将结果向量存储回数组
vec_result.intoArray(arr, i);
}
// 尾部循环:处理任何剩余的元素 (数量小于一个完整向量的长度)
for (; i < arr.length; i++) {
arr[i] *= factor;
}
}
未完待续
很高兴与你相遇!如果你喜欢本文内容,记得关注哦!
解锁硬件潜能:Java向量化计算,性能飙升W倍!的更多相关文章
- 如何利用缓存机制实现JAVA类反射性能提升30倍
一次性能提高30倍的JAVA类反射性能优化实践 文章来源:宜信技术学院 & 宜信支付结算团队技术分享第4期-支付结算部支付研发团队高级工程师陶红<JAVA类反射技术&优化> ...
- 性能调优之Java系统级性能监控及优化
性能调优之Java系统级性能监控及优化 对于性能调优而言,通常我们需要经过以下三个步骤:1,性能监控:2,性能剖析:3,性能调优 性能调优:通过分析影响Application性能问题根源,进行优化 ...
- 2017年的golang、python、php、c++、c、java、Nodejs性能对比(golang python php c++ java Nodejs Performance)
2017年的golang.python.php.c++.c.java.Nodejs性能对比 本人在PHP/C++/Go/Py时,突发奇想,想把最近主流的编程语言性能作个简单的比较, 至于怎么比,还是不 ...
- JProfiler 解决 Java 服务器的性能跟踪
作者:徐建祥(netpirate@gmail.com) 时间: 2006/01/05 来自:http://www.anymobile.org 1.摘要......................... ...
- Java-Runoob-高级教程-实例-字符串:11. Java 实例 - 字符串性能比较测试
ylbtech-Java-Runoob-高级教程-实例-字符串:11. Java 实例 - 字符串性能比较测试 1.返回顶部 1. Java 实例 - 字符串性能比较测试 Java 实例 以下实例演 ...
- jvm 命令使用调优 通过jstat、jmap对java程序进行性能调优
转载:http://blog.csdn.net/jerry024/article/details/8507589 转载: https://blog.csdn.net/zhaozheng7758/art ...
- Java服务端性能优化
<Java程序性能优化>说性能优化包含五个层次:设计调优.代码调优.JVM调优.数据库调优.操作系统调优. 常用的几个代码优化方案: 使用单例 对于IO处理.数据库连接.配置文件解析加载等 ...
- Java精确计算小数
Java在计算浮点数的时候,由于二进制无法精确表示0.1的值(就好比十进制无法精确表示1/3一样),所以一般会对小数格式化处理. 但是如果涉及到金钱的项目,一点点误差都不能有,必须使用精确运算的时候, ...
- Java精确计算
Java精确计算 如果我们编译运行下面这个程序会看到什么? public class Test{ public static void main(String args[]){ System.out. ...
- lua、groovy嵌入到java中的性能对比(转)
lua和groovy都是可以嵌入到java中的脚本语言.lua以高性能著称,与C/C++在游戏开放中有较多使用,groovy是一个基于Java虚拟机(JVM)的敏捷动态语言,在jvm下有着不错的性能. ...
随机推荐
- sass中@use 的用法
前言在上一篇中,我们深入探讨了 Sass 中 @import 语法的局限性,正是因为这些问题,Sass 在 1.80 版本 后逐步弃用 @import,推出了更现代化的 @use 语法作为替代.在本文 ...
- 简单介绍List和数组转List集合
目录 综述 如何创建List 六种数组转List的方法 for循环遍历 Arrays.asList() new ArrayList<>(Arrays.asList(array)) Coll ...
- Apache JMeter压力测试工具的安装与使用
官网下载 https://jmeter.apache.org/download_jmeter.cgi 然后解压即可 运行 双击bin/jmeter.bat 汉化 在软件里选择语言重启就会还原,所以这里 ...
- [书籍精读]《JavaScript异步编程》精读笔记分享
写在前面 书籍介绍:本书讲述基本的异步处理技巧,包括PubSub.事件模式.Promises等,通过这些技巧,可以更好的应对大型Web应用程序的复杂性,交互快速响应的代码.理解了JavaScript的 ...
- 【Electron】记录一下常用代码
macOS 实现毛玻璃效果 function createWindow() { const mainWindow = new BrowserWindow({ width: 960, height: 6 ...
- Spread Ribbon 工具栏控件:在WinForms中高效编辑Spread工作簿
引言 在数据密集型应用中,电子表格功能是提升用户体验的关键要素.GrapeCity Spread.NET V17 推出的独立 Ribbon工具栏控件,为WinForms开发者提供了与Excel高度一致 ...
- DBA备库工具:Oracle环境中表空间全自动扩容
我们的文章会在微信公众号IT民工的龙马人生和博客网站( www.htz.pw )同步更新 ,欢迎关注收藏,也欢迎大家转载,但是请在文章开始地方标注文章出处,谢谢! 由于博客中有大量代码,通过页面浏览效 ...
- MySQL 07 行锁功过:怎么减少行锁对性能的影响?
行锁是针对数据表中行记录的锁,是在引擎层由引擎实现的. 从两阶段锁说起 在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立即释放,而是等到事务结束时才释放,这就是两阶段锁协议. 知 ...
- websocket拦截器,统一处理参数和返回值json数据
前言 传统的ws,发送前后都需要json序列化和反序列化这对编写代码并不友好.所以我做了个优化 废话不多说,上代码 my-ws.js const ws = new WebSocket("ws ...
- leetcode 236 而哈数的最近公共祖先
简介 dfs 找出路劲,然后长链在短链里面找. code /** * Definition for a binary tree node. * struct TreeNode { * int val; ...