使用CAMEL实现Graph RAG过程记录
前言
本文为学习官方文档Graph RAG Cookbook — CAMEL 0.2.47 documentation的学习记录。
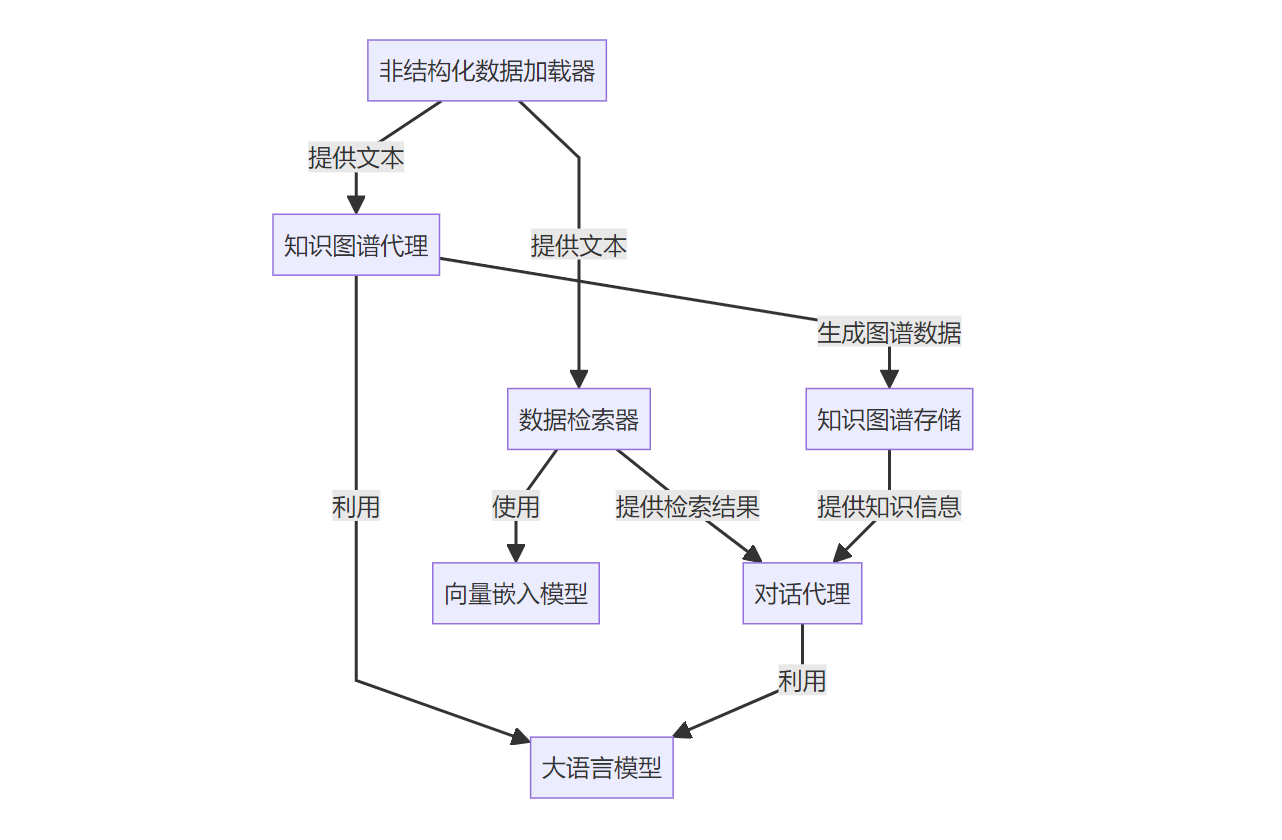
配置Neo4j图数据库
第一步先配置 Neo4j 图数据库。
在浏览器中导航到 Neo4j Aura 控制台。
选择新建实例。
选择创建免费实例。
复制并保存实例的用户名和生成的密码,或者将凭据下载为 .txt 文件。
勾选确认复选框,然后选择继续。
每个账户只能创建一个 AuraDB 免费实例。
免费实例限制为 200,000 个节点和 400,000 个关系。
地址:https://neo4j.com/docs/aura/classic/auradb/getting-started/create-database/
免费额度已经够我们学习使用的了。
什么是知识图谱数据库?为什么是 Neo4j?
想象一下,我们生活中的信息并不是孤立的。一个人“居住在”一个城市,一个公司“开发了”一个产品,一篇文章“讨论了”一个主题。这些信息之间充满了“关系”。传统的数据库(比如表格形式的关系型数据库)虽然能存储大量数据,但在表达和查询这些复杂的“关系”时,可能会变得非常复杂和低效。
知识图谱数据库应运而生,它就像一个巨大的“概念关系网”。它以图形(Graph)的形式来存储数据,主要由两部分组成:
- 节点 (Nodes): 代表现实世界中的“事物”或“概念”,比如一个人、一个地点、一个组织、一个事件、一个产品等等。可以想象成社交网络里的“人”。
- 边 (Relationships): 代表节点之间的“关系”或“联系”。比如“居住在”、“属于”、“开发了”、“写了”、“讨论了”等等。可以想象成社交网络里的“朋友关系”或“关注关系”。每条边都有方向和类型。
除了节点和边,它们还可以拥有属性 (Properties),用来存储关于节点或边的额外信息。比如,一个“人”节点可以有“姓名”、“年龄”属性;一条“居住在”边可以有“开始日期”属性。节点还可以有标签 (Labels),用来分类节点的类型(例如:Person, Organization, Product)。
A["节点 A (标签: Person)"] -- "关系 X (属性: 日期)" --> B["节点 B (标签: City)"]
C["节点 C (标签: Organization)"] -- "关系 Y" --> D["节点 D (标签: Product)"]
B -- "关系 Z" --> C

上图:一个简单的知识图谱示例,展示了节点、标签和关系。
Neo4j 是一种流行的、高性能的图数据库,专门用于存储和处理知识图谱。它使用一种称为 Cypher 的强大图查询语言,可以非常直观和高效地查询节点和它们之间的关系。
在 本文中,我们将 Neo4j 用作我们的知识图谱存储层。它存放着由知识图谱代理从各种来源(比如文档、网页)中提取出来的结构化数据(节点和边)。这样存储的好处是:
- 关系清晰: 直接以图的形式存储,数据的关系一目了然。
- 查询高效: 对于需要遍历关系或查找复杂模式的查询,Neo4j 通常比传统数据库快得多。
- 结构化利用: 存储在 Neo4j 中的知识图谱数据,可以被信息检索流程以结构化的方式进行查询和利用,比如找到与某个实体直接关联的所有事实。这为 RAG 应用提供了更精准、更具解释性的知识来源。
简单来说,Neo4j 就是 RAG 应用中存放那些“结构化事实”的“大脑记忆库”。
创建实例:
from camel.models import ModelFactory
from camel.types import ModelPlatformType, ModelType
from camel.configs import MistralConfig, OllamaConfig
from camel.loaders import UnstructuredIO
from camel.storages import Neo4jGraph
from camel.retrievers import AutoRetriever
from camel.embeddings import MistralEmbedding
from camel.types import StorageType
from camel.agents import ChatAgent, KnowledgeGraphAgent
from camel.messages import BaseMessage
import pathlib
import os
from dotenv import load_dotenv
sys_msg = 'You are a curious stone wondering about the universe.'
base_dir = pathlib.Path(__file__).parent.parent
env_path = base_dir / ".env"
load_dotenv(dotenv_path=str(env_path))
modeltype = os.getenv("Silicon_Model_ID")
modeltype2= os.getenv("ZHIPU_Model_ID")
api_key = os.getenv("SiliconCloud_API_KEY")
base_url = os.getenv("SiliconCloud_Base_URL")
siliconcloud_model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=modeltype,
api_key=api_key,
url=base_url,
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)
siliconcloud_model2 = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=modeltype2,
api_key=api_key,
url=base_url,
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)
# Set Neo4j instance
n4j = Neo4jGraph(
url="url",
username="neo4j",
password="password",
)
# Set instance
uio = UnstructuredIO()
kg_agent = KnowledgeGraphAgent(model=siliconcloud_model)
创建Neo4j实例需要url、username与password,在创建好实例之后,叫你下载的那个txt文件里,如下所示:

现在来测试一段文本:
随便用AI生成一段包含主人公小明与小红的适用于知识图谱的文本。
# Set example text input
text_example = """
在一个风和日丽的下午,小明和小红在图书馆邂逅了。小明是一名对历史充满热情的大学生,而小红则是一位热衷于现代艺术的画家。两人因为一本关于古代文明与现代艺术融合的书籍而结缘。在接下来的几个月里,他们一起参观了许多博物馆和艺术展览,从小明对古代文化深厚的理解中,小红获得了许多创作灵感;而小红对色彩和形式的敏锐感知,也让小明对历史有了更生动的认识。他们的友谊逐渐加深,最终决定合作创建一个项目,旨在通过现代艺术的形式展现历史文化的魅力,旨在连接过去与未来,传统与创新。这个项目不仅加深了他们之间的关系,也使得周围的人开始对历史与艺术的结合产生了浓厚的兴趣。
""
从给定的文本创建一个元素,并让知识图谱代理提取节点和关系信息,然后再检查一下。
# Create an element from given text
element_example = uio.create_element_from_text(
text=text_example, element_id="0"
)
# Let Knowledge Graph Agent extract node and relationship information
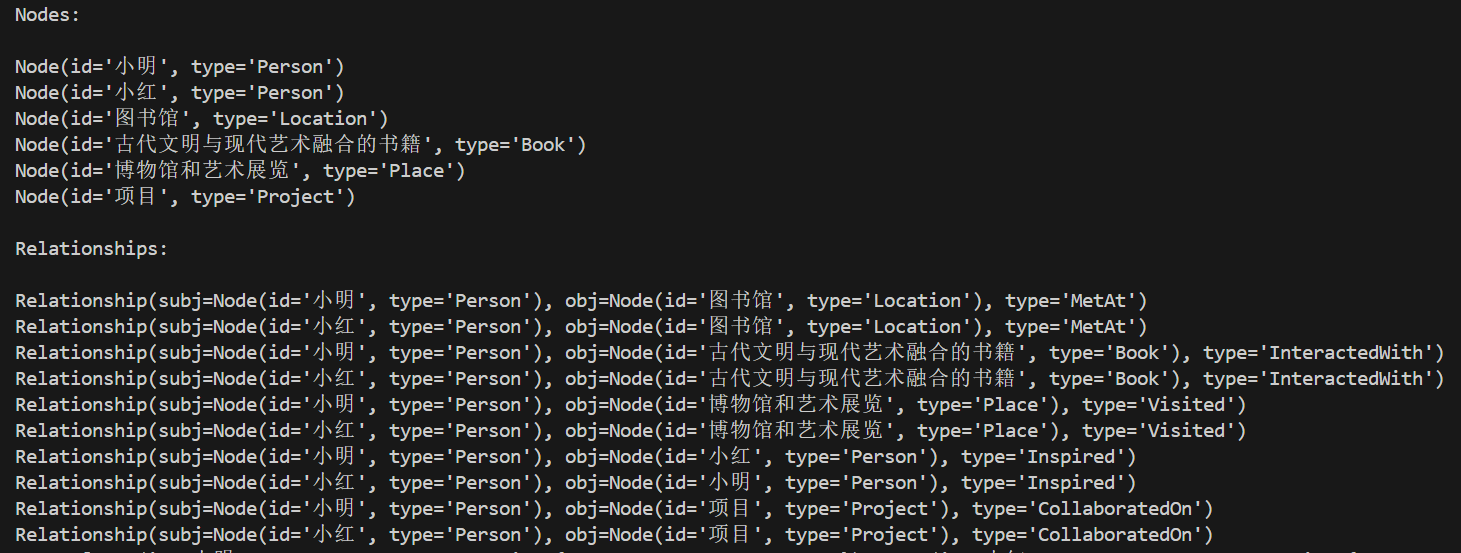
ans_element = kg_agent.run(element_example, parse_graph_elements=False)
print(ans_element)
# Check graph element
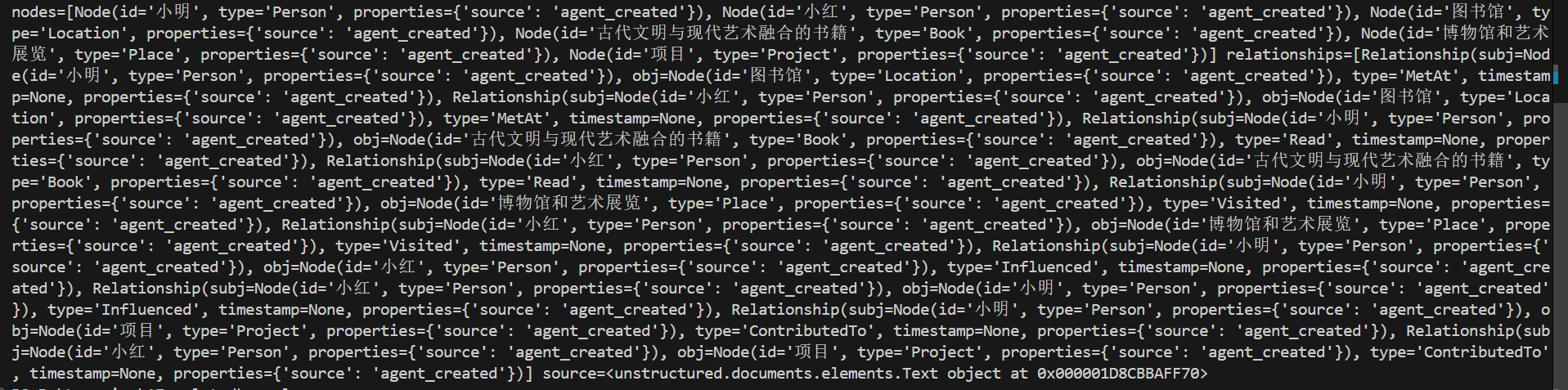
graph_elements = kg_agent.run(element_example, parse_graph_elements=True)
print(graph_elements)
查看效果:
保存至图数据库:
# Add the element to neo4j database
n4j.add_graph_elements(graph_elements=[graph_elements])
打开图数据库控制台,如下所示:
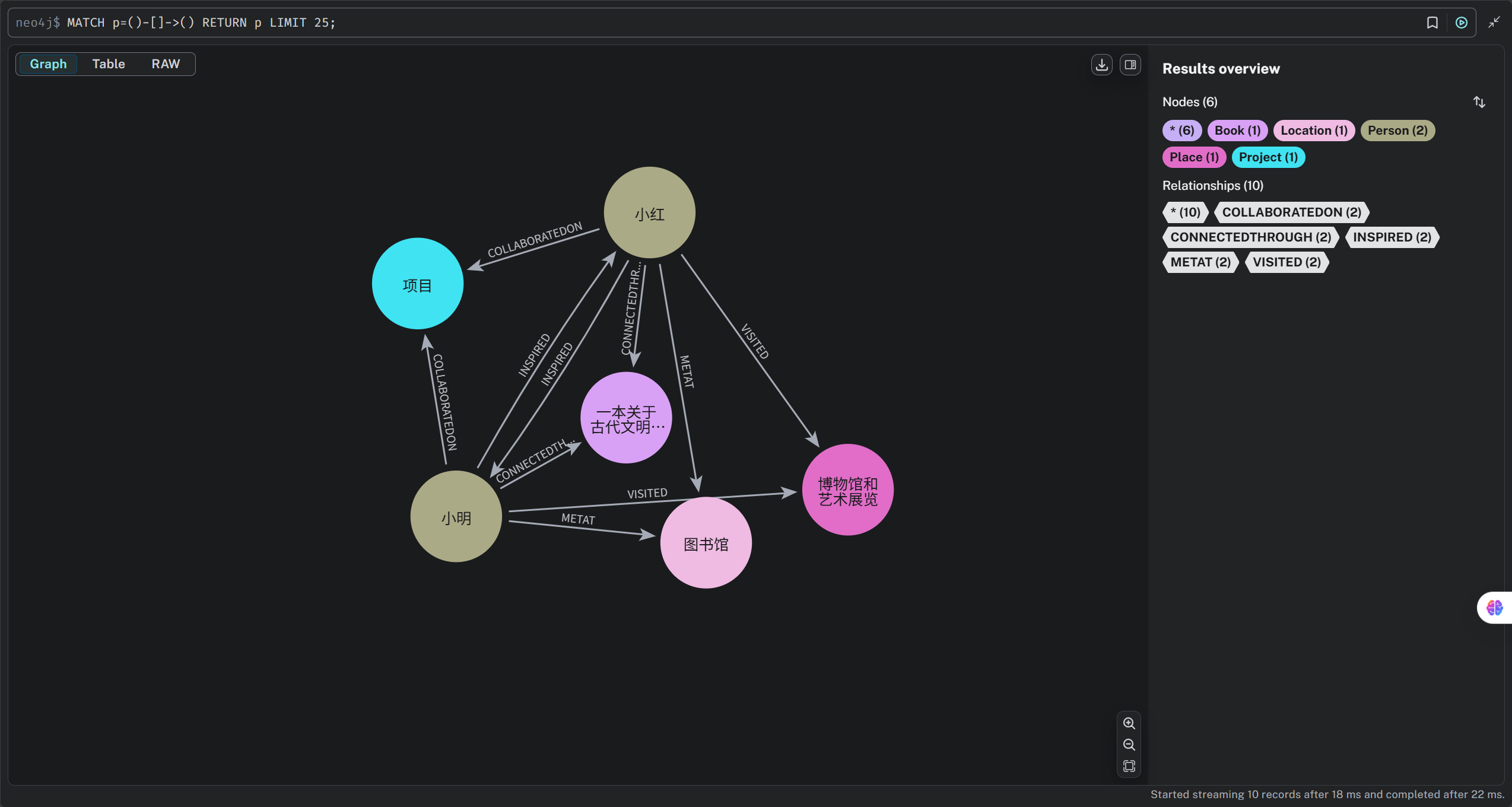
agent_with_graph_rag
现在来看看如何实现Graph RAG。
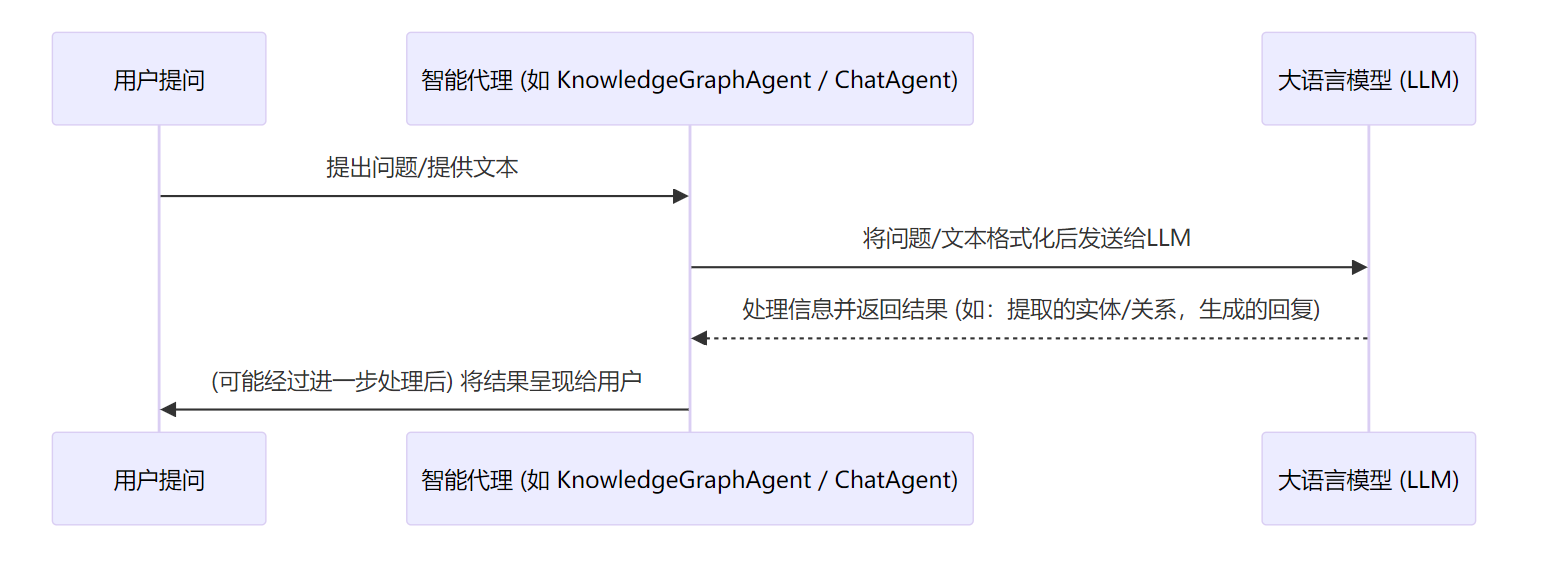
写一个agent_with_graph_rag脚本:
from camel.models import ModelFactory
from camel.types import ModelPlatformType, ModelType
from camel.configs import MistralConfig, OllamaConfig
from camel.loaders import UnstructuredIO
from camel.storages import Neo4jGraph
from camel.retrievers import AutoRetriever
from camel.embeddings import OpenAICompatibleEmbedding
from camel.types import StorageType
from camel.agents import ChatAgent, KnowledgeGraphAgent
from camel.messages import BaseMessage
import pathlib
import os
from dotenv import load_dotenv
sys_msg = 'You are a curious stone wondering about the universe.'
base_dir = pathlib.Path(__file__).parent.parent
env_path = base_dir / ".env"
load_dotenv(dotenv_path=str(env_path))
modeltype = os.getenv("Silicon_Model_ID")
modeltype2= os.getenv("ZHIPU_Model_ID")
embedding_modeltype = os.getenv("Embedding_Model_ID")
api_key = os.getenv("SiliconCloud_API_KEY")
base_url = os.getenv("SiliconCloud_Base_URL")
siliconcloud_model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=modeltype,
api_key=api_key,
url=base_url,
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)
siliconcloud_model2 = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=modeltype2,
api_key=api_key,
url=base_url,
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)
# Set one user query
query="小明与小红有什么关系?"
# Parse content from mistral website and create knowledge graph data by using
# the Knowledge Graph Agent, store the information into graph database.
# Set Neo4j instance
n4j = Neo4jGraph(
url="url",
username="neo4j",
password="password",
)
# Set instance
uio = UnstructuredIO()
kg_agent = KnowledgeGraphAgent(model=siliconcloud_model)
# Create an element from user query
query_element = uio.create_element_from_text(
text=query, element_id="1"
)
# Let Knowledge Graph Agent extract node and relationship information from the qyery
ans_element = kg_agent.run(query_element, parse_graph_elements=True)
# Match the entity got from query in the knowledge graph storage content
kg_result = []
for node in ans_element.nodes:
n4j_query = f"""
MATCH (n {{id: '{node.id}'}})-[r]->(m)
RETURN 'Node ' + n.id + ' (label: ' + labels(n)[0] + ') has relationship ' + type(r) + ' with Node ' + m.id + ' (label: ' + labels(m)[0] + ')' AS Description
UNION
MATCH (n)<-[r]-(m {{id: '{node.id}'}})
RETURN 'Node ' + m.id + ' (label: ' + labels(m)[0] + ') has relationship ' + type(r) + ' with Node ' + n.id + ' (label: ' + labels(n)[0] + ')' AS Description
"""
result = n4j.query(query=n4j_query)
kg_result.extend(result)
kg_result = [item['Description'] for item in kg_result]
# Show the result from knowledge graph database
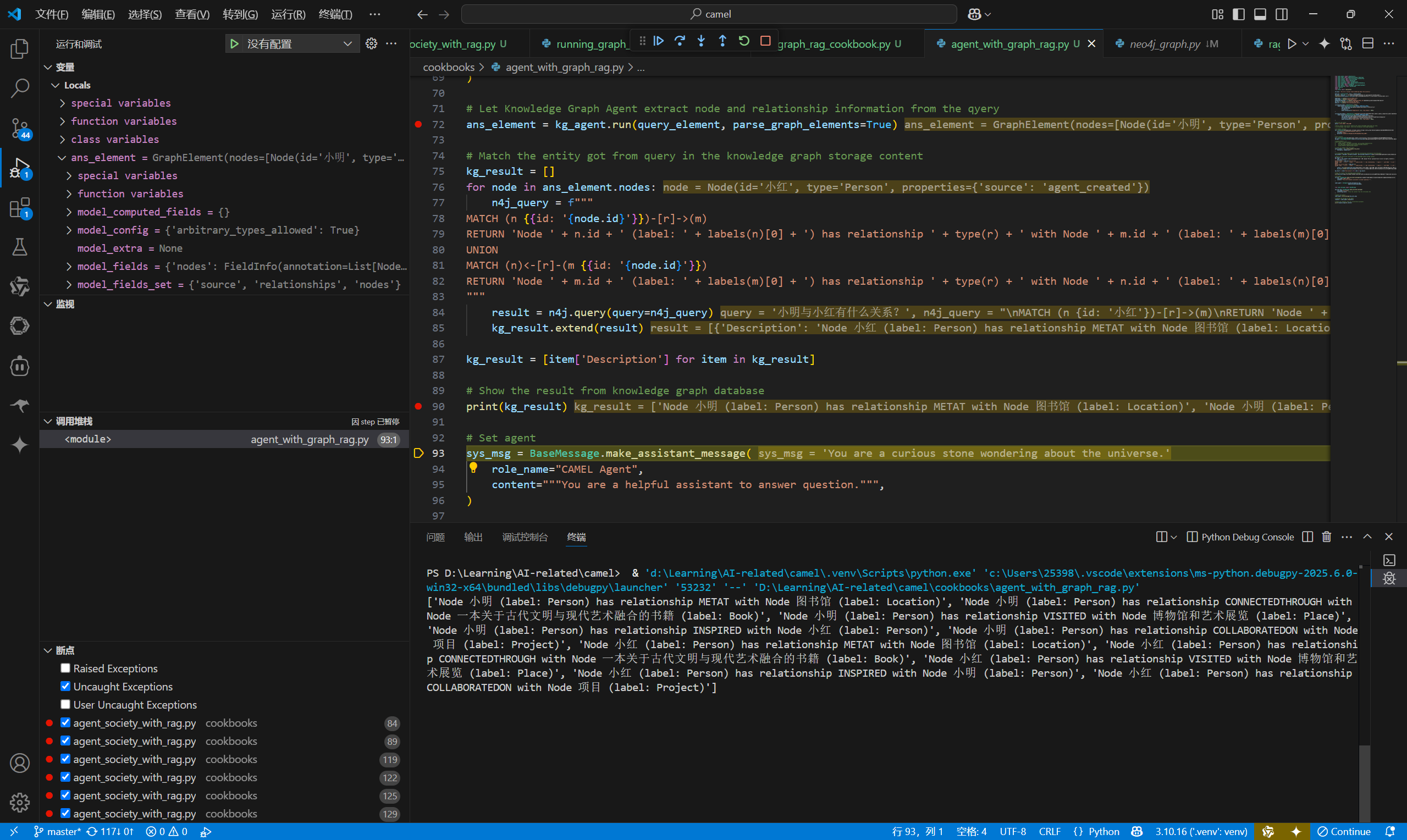
print(kg_result)
text = "\n".join(kg_result)
print(text)
# Set agent
sys_msg = BaseMessage.make_assistant_message(
role_name="CAMEL Agent",
content="""You are a helpful assistant to answer question.""",
)
camel_agent = ChatAgent(system_message=sys_msg,
model=siliconcloud_model)
from camel.messages import BaseMessage
new_user_msg = BaseMessage.make_assistant_message(
role_name="assistant",
content=text, # Use the content from the retrieved info
)
# Update the memory
camel_agent.record_message(new_user_msg)
# Sending the message to the agent
response = camel_agent.step(query)
# Check the response (just for illustrative purpose)
print(response.msgs[0].content)
调试运行。
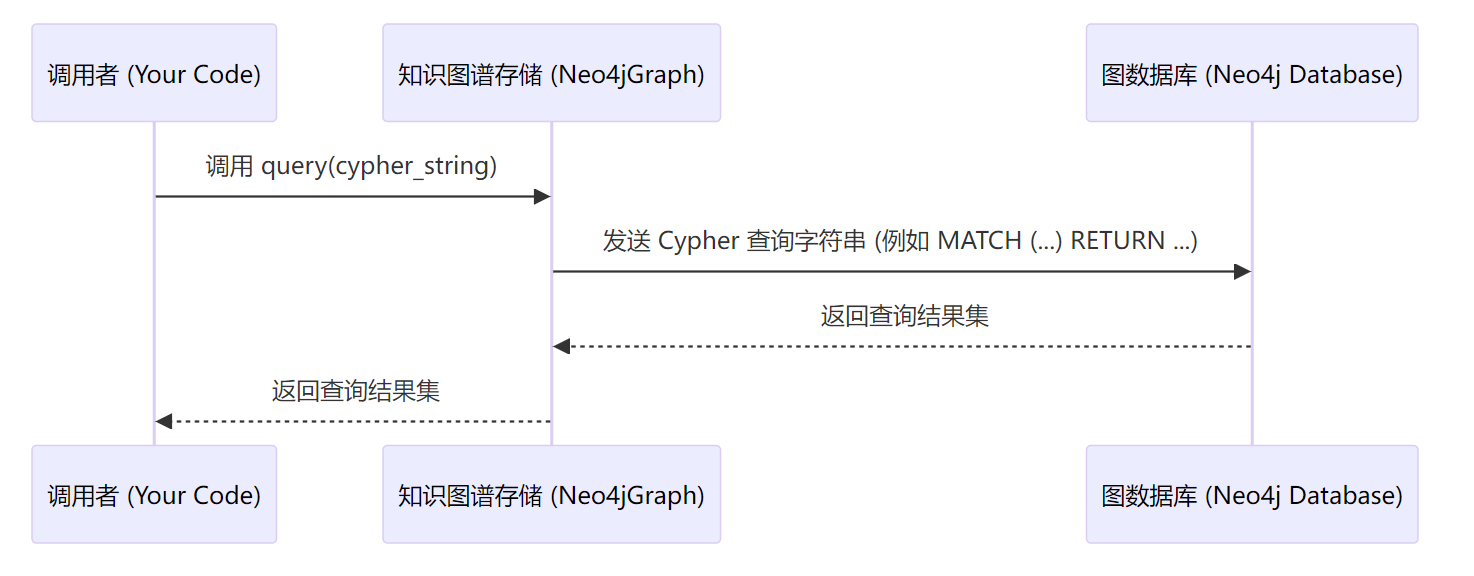
从图数据库中取出相关的内容:
查看结果:
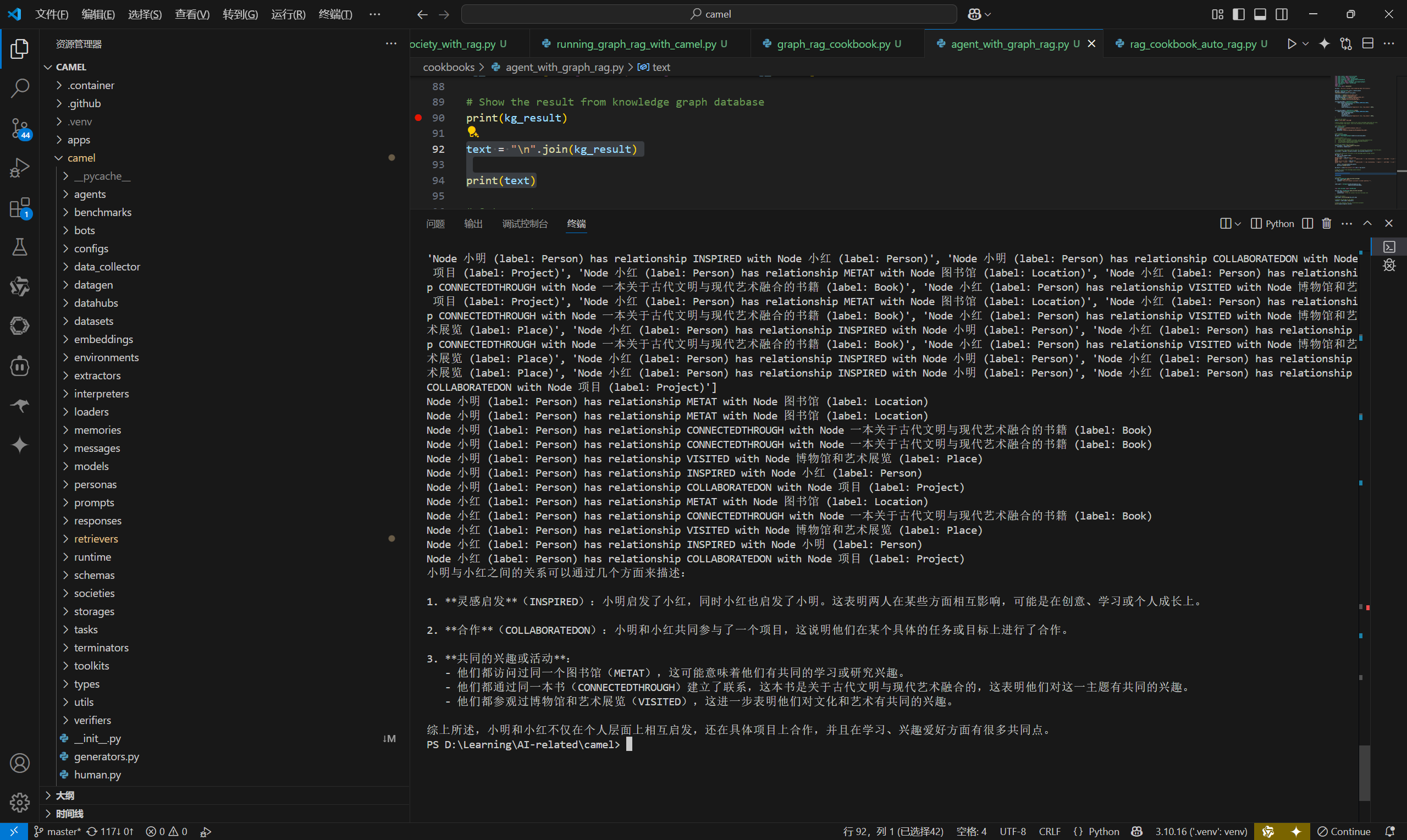
小明与小红之间的关系可以通过几个方面来描述:
1. **灵感启发**(INSPIRED):小明启发了小红,同时小红也启发了小明。这表明两人在某些方面相互影响,可能是在创意、学习或个人成长上。
2. **合作**(COLLABORATEDON):小明和小红共同参与了一个项目,这说明他们在某个具体的任务或目标上进行了合作。
3. **共同的兴趣或活动**:
- 他们都访问过同一个图书馆(METAT),这可能意味着他们有共同的学习或研究兴趣。
- 他们都通过同一本书(CONNECTEDTHROUGH)建立了联系,这本书是关于古代文明与现代艺术融合的,这表明他们对这一主题有共同的兴趣。
- 他们都参观过博物馆和艺术展览(VISITED),这进一步表明他们对文化和艺术有共同的兴趣。
综上所述,小明和小红不仅在个人层面上相互启发,还在具体项目上合作,并且在学习、兴趣爱好方面有很多共同点。
混合检索
还可以将前面学的向量检索与图检索结合起来。
脚本可以这样写:
from camel.models import ModelFactory
from camel.types import ModelPlatformType, ModelType
from camel.configs import MistralConfig, OllamaConfig
from camel.loaders import UnstructuredIO
from camel.storages import Neo4jGraph
from camel.retrievers import AutoRetriever
from camel.embeddings import OpenAICompatibleEmbedding
from camel.types import StorageType
from camel.agents import ChatAgent, KnowledgeGraphAgent
from camel.messages import BaseMessage
import pathlib
import os
from dotenv import load_dotenv
sys_msg = 'You are a curious stone wondering about the universe.'
base_dir = pathlib.Path(__file__).parent.parent
env_path = base_dir / ".env"
load_dotenv(dotenv_path=str(env_path))
modeltype = os.getenv("Silicon_Model_ID")
modeltype2= os.getenv("ZHIPU_Model_ID")
embedding_modeltype = os.getenv("Embedding_Model_ID")
api_key = os.getenv("SiliconCloud_API_KEY")
base_url = os.getenv("SiliconCloud_Base_URL")
siliconcloud_model = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=modeltype,
api_key=api_key,
url=base_url,
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)
siliconcloud_model2 = ModelFactory.create(
model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,
model_type=modeltype2,
api_key=api_key,
url=base_url,
model_config_dict={"temperature": 0.4, "max_tokens": 4096},
)
embedding_instance = OpenAICompatibleEmbedding(model_type=embedding_modeltype, api_key=api_key, url=base_url)
embedding_instance.output_dim=1024
auto_retriever = AutoRetriever(
vector_storage_local_path="local_data3/",
storage_type=StorageType.QDRANT,
embedding_model=embedding_instance)
# Set example text input
text_example = """
在一个风和日丽的下午,小明和小红在图书馆邂逅了。
小明是一名对历史充满热情的大学生,而小红则是一位热衷于现代艺术的画家。
两人因为一本关于古代文明与现代艺术融合的书籍而结缘。
在接下来的几个月里,他们一起参观了许多博物馆和艺术展览,从小明对古代文化深厚的理解中,小红获得了许多创作灵感;而小红对色彩和形式的敏锐感知,也让小明对历史有了更生动的认识。他们的友谊逐渐加深,最终决定合作创建一个项目,旨在通过现代艺术的形式展现历史文化的魅力,旨在连接过去与未来,传统与创新。
这个项目不仅加深了他们之间的关系,也使得周围的人开始对历史与艺术的结合产生了浓厚的兴趣。
"""
# Set one user query
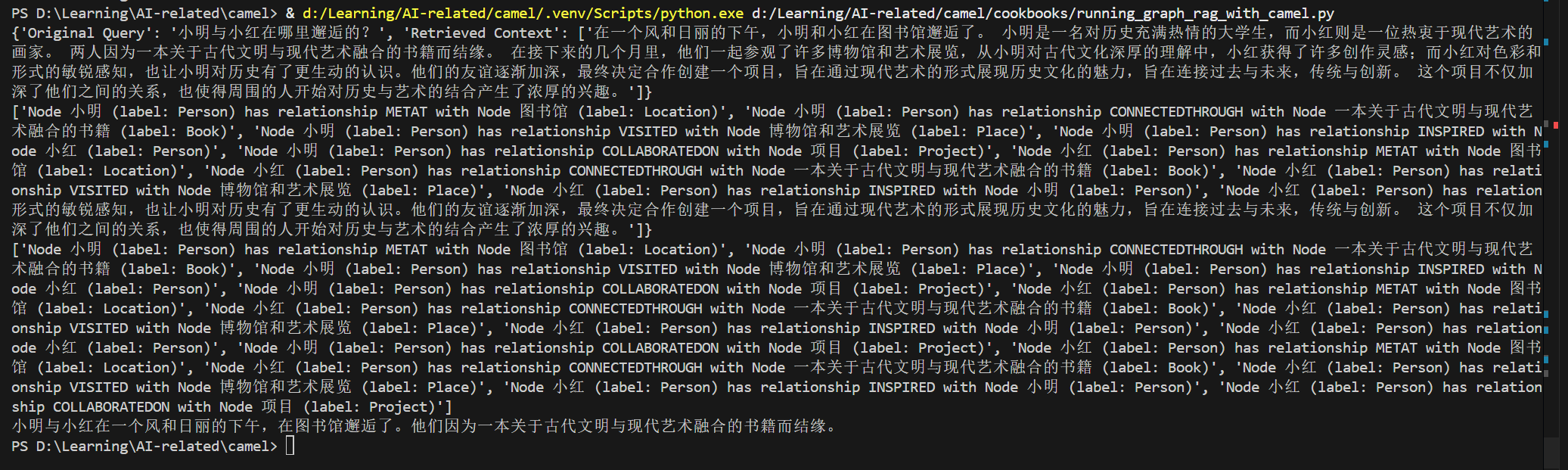
query="小明与小红在哪里邂逅的?"
# Get related content by using vector retriever
vector_result = auto_retriever.run_vector_retriever(
query=query,
contents=text_example,
similarity_threshold=0.6
)
# Show the result from vector search
print(vector_result)
# Parse content from mistral website and create knowledge graph data by using
# the Knowledge Graph Agent, store the information into graph database.
# Set Neo4j instance
n4j = Neo4jGraph(
url="url",
username="neo4j",
password="password",
)
# Set instance
uio = UnstructuredIO()
kg_agent = KnowledgeGraphAgent(model=siliconcloud_model)
# Create an element from user query
query_element = uio.create_element_from_text(
text=query, element_id="1"
)
# Let Knowledge Graph Agent extract node and relationship information from the qyery
ans_element = kg_agent.run(query_element, parse_graph_elements=True)
# Match the entity got from query in the knowledge graph storage content
kg_result = []
for node in ans_element.nodes:
n4j_query = f"""
MATCH (n {{id: '{node.id}'}})-[r]->(m)
RETURN 'Node ' + n.id + ' (label: ' + labels(n)[0] + ') has relationship ' + type(r) + ' with Node ' + m.id + ' (label: ' + labels(m)[0] + ')' AS Description
UNION
MATCH (n)<-[r]-(m {{id: '{node.id}'}})
RETURN 'Node ' + m.id + ' (label: ' + labels(m)[0] + ') has relationship ' + type(r) + ' with Node ' + n.id + ' (label: ' + labels(n)[0] + ')' AS Description
"""
result = n4j.query(query=n4j_query)
kg_result.extend(result)
kg_result = [item['Description'] for item in kg_result]
# Show the result from knowledge graph database
print(kg_result)
# combine result from vector search and knowledge graph entity search
comined_results = str(vector_result) + "\n".join(kg_result)
# Set agent
sys_msg = BaseMessage.make_assistant_message(
role_name="CAMEL Agent",
content="""You are a helpful assistant to answer question.""",
)
camel_agent = ChatAgent(system_message=sys_msg,
model=siliconcloud_model)
from camel.messages import BaseMessage
new_user_msg = BaseMessage.make_assistant_message(
role_name="assistant",
content=comined_results, # Use the content from the retrieved info
)
# Update the memory
camel_agent.record_message(new_user_msg)
# Sending the message to the agent
response = camel_agent.step(query)
# Check the response (just for illustrative purpose)
print(response.msgs[0].content)
效果:
使用CAMEL实现Graph RAG过程记录的更多相关文章
- 升级Windows 10 正式版过程记录与经验
升级Windows 10 正式版过程记录与经验 [多图预警]共50张,约4.6MB 系统概要: 预装Windows 8.1中文版 64位 C盘Users 文件夹已经挪动到D盘,并在原处建立了符号链接. ...
- 双系统Ubuntu分区扩容过程记录
本人电脑上安装了Win10 + Ubuntu 12.04双系统.前段时间因为在Ubuntu上做项目要安装一个比较大的软件,导致Ubuntu根分区的空间不够了.于是,从硬盘又分出来一部分空间,分给Ubu ...
- CentOS 5.5 下安装Countly Web Server过程记录
CentOS 5.5 下安装Countly Web Server过程记录 1. 系统更新与中文语言包安装 2. 基本环境配置: 2.1. NodeJS安装 依赖项安装 yum -y install g ...
- linux-i386(ubuntu)下编译安装gsoap_2.8.17过程记录
过程记录 : 1.下载gsoap_2.8.17.zip 并 解压 : $unzip gsoap_2.8.17.zip 2.进入解压后的目录gsoap-2.8 3.自动配置编译环境: $ ...
- 【转】android 最新 NDK r8 在window下开发环境搭建 安装配置与使用 详细图文讲解,完整实际配置过程记录(原创)
原文网址:http://www.cnblogs.com/zdz8207/archive/2012/11/27/android-ndk-install.html android 最新 NDK r8 在w ...
- 升级到 ExtJS 5的过程记录
升级到 ExtJS 5的过程记录 最近为公司的一个项目创建了一个 ExtJS 5 的分支,顺便记录一下升级到 ExtJS 5 所遇到的问题以及填掉的坑.由于 Sencha Cmd 的 sencha ...
- Ubuntu14.04 Tomcat 安装过程记录
Ubuntu14.04 Tomcat 安装过程记录 检查java的版本 zhousp@ubuntu:~$ sudo java -version [sudo] password for zhousp: ...
- mercurial(Hg) Server 搭建 过程记录
mercurial(Hg) Server 搭建 过程记录 1. 环境说明 只是测试搭建,环境为本机开发环境:win 8.1 + IIS8.5 软件准备: 2. 软件安装 先安装Python2.7, ...
- xp硬盘安装Fedora14 过程记录及心得体会(fedora14 live版本680M 和fedora14 DVD版本3.2G的选择)
这次电脑奔溃了,奇怪的是直接ghost覆盖c盘竟然不中.之前电脑上硬盘安装的fedora14操作系统,也是双系统.不知道是不是这个问题,记得同学说过,在硬盘装fedora之后,要手动修改c盘隐藏的那个 ...
- openWRT自学---自己编译的第一个 backfire10.03 版本的过程记录(转)
基于 backfire10.03(从http://downloads.openwrt.org/backfire/10.03/ 中下砸的源码包backfire_10.03_source.tar.bz2: ...
随机推荐
- 对比使用DeepSeek与文新一言,了解DeepSeek的关键技术论文
DeepSeek是国内大模型技术的新秀,最近也在业界和媒体界火爆出圈,所以想学习一下其技术. 大模型时代,学习知识,当然首先想到利用大模型,由于在过去一年,对DeepSeek使用不多,所以想和文新一言 ...
- 腾讯云HAI服务器上部署与调用DeepSeek-R1大模型的实战指南
上次我们大概了解了一下 DeepSeek-R1 大模型,并简单提及了 Ollama 的一些基本信息.今天,我们将深入实际操作,利用腾讯云的 HAI 服务器进行 5 分钟部署,并实现本地 DeepSee ...
- Project Euler 588 题解
这玩意好像甚至有递推式--不太懂 (为什么是图片?cnblogs 第一个公式没渲染成功) 时间复杂度是 \(O(4^{\deg F}\log K)\) 的. #include<bits/stdc ...
- datawhale-leetcode打卡:第026~037题
反转链表(leetcode 206) 这个题目我就比较流氓了,干脆新建链表翻转过来算了.但是完蛋,超出内存限制,那我就只能两两换了.这里比较大的技巧就是可以用一个空节点进行置换. # Definiti ...
- 2024年最新iOS 17屏蔽系统更新方法,iPhone、iPad通用!
到Safari浏览器打开,描述文件会自动安装进手机里. 这时候我们在设置里,找到设备管理,点击刚刚下载好的描述文件,进行安装.要注意看,有苹果的签名,才说明是官方出品,千万要注意哦!安装完成后,重启手 ...
- 八米云-N1盒子、S905系列机顶盒等设备-小白保姆式超详细刷机教程
线刷准备 这里以魔百盒CM211-1为例,本次刷机用到的零碎工具比较多,不过都是常见刚需设备,大家可以按照清单核对一下. 目前只支持S905 L3.L3a.L2 系列的各种盒子 机顶盒本体 电脑一台 ...
- MybatisPlus - [08] RestFul
编号 接口 请求方式 请求路径 请求参数 返回值 1 新增用户 POST /users 用户表单实体 无 2 删除用户 DELETE /users/{id} 用户id 无 3 根据id查询用户 GET ...
- Qt QSqlDatabase的removeDatabase需要注意的地方
文章目录 问题描述 Qt官方解决方法 另外一种解决方式 碎碎念 关于智能指针 问题描述 今天在做之前代码的重构的时候,在调用QSqlDatabase的removeDatabase函数的时候,出现了如下 ...
- linux xxx is not in the sudoers file. This incident will be reported.
前言 linux 报错:xxx is not in the sudoers file. This incident will be reported. 这意味着用户 xxx 没有在 sudoers 文 ...
- 2025年3月GESP八级真题解析
第一题--上学 题目描述 C 城可以视为由 \(n\) 个结点与 \(m\) 条边组成的无向图.这些结点依次以 \(1,2,-,n\) 标号,边依次以 \(1,2,-,m\) 标号.第 \(i\) 条 ...