机器学习-回归中的相关度和R平方值
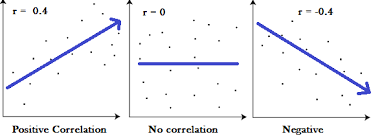
1. 皮尔逊相关系数(Pearson Correlation Coefficient)
1.1 衡量两个值线性相关强度的量
1.2 取值范围[-1, 1]
正相关:>0, 负相关:<0, 无相关:=0
1.3 要理解Pearson相关系数,首先要理解协方差(Covariance),协方差是一个反映两个随机变量相关程度的指标,如果一个变量跟随着另一个变量同时变大或者变小,那么这两个变量的协方差就是正值,反之相反,公式如下:
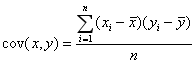
方差:
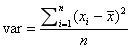
Pearson相关系数公式如下:
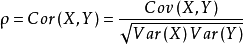
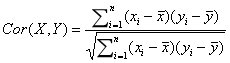
注意:有了协方差,为什么还使用皮尔逊相关系数?虽然协方差能反映两个随机变量的相关程度(协方差大于0的时候表示两者正相关,小于0的时候表示两者负相关),但是协方差值的大小并不能很好地度量两个随机变量的关联程度,例如,现在二维空间中分布着一些数据,我们想知道数据点坐标X轴和Y轴的相关程度,如果X与Y的相关程度较小但是数据分布的比较离散,这样会导致求出的协方差值较大,用这个值来度量相关程度是不合理的。
为了更好的度量两个随机变量的相关程度,引入了Pearson相关系数,其在协方差的基础上除以了两个随机变量的标准.
2. 计算方法举例:
x y
1 10
3 12
8 24
7 21
9 34
在Excel中计算:

3. 其他例子
4. R平方值
4.1 定义:决定系数,反应因变量的全部变异能通过回归关系被自变量解释的比例。
也就是说,对于已经建模的模型,多大程度上可以解释数据
4.2 描述:如R平方为0.8,则表示回归关系可以解释因变量80%的变异。换句话说,如果我们控制自变量不变,则因变量的变异程度会减少80%。
4.3 简单线性回归:R^2 = r * r (r为皮尔逊相关系数)
多元线性回归:
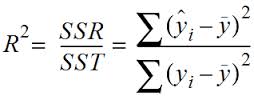
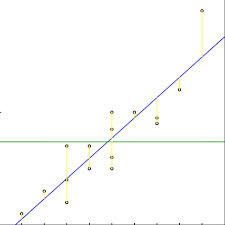

R平方也有局限性:R平方随着自变量的增加会变大,R平方和样本量是有关系的。因此,我们要对R平方进行修正。修正方法:

实际中一般会选择修正后的R平方值对线性回归模型对拟合度进行评判
Python实现:
# -*- coding:utf-8 -*- import numpy as np
from astropy.units import Ybarn
import math #相关度
def computeCorrelation(X, Y):
xBar = np.mean(X)
yBar = np.mean(Y)
SSR = 0
varX = 0
varY = 0
for i in range(0, len(X)):
diffXXbar = X[i] - xBar
diffYYbar = Y[i] - yBar
SSR += (diffXXbar * diffYYbar)
varX += diffXXbar**2
varY += diffYYbar**2
SST = math.sqrt(varX * varY)
return SSR / SST #测试
testX = [1, 3, 8, 7, 9]
testY = [10, 12, 24, 21, 34] # print("相关度r:", computeCorrelation(testX, testY))
#相关度r: 0.940310076545 #R平方
#简单线性回归:
# print("r^2:", str(computeCorrelation(testX, testY)**2))
#r^2: 0.884183040052 #多个x自变量时:
def polyfit(x, y, degree): #degree自变量x次数
result = {}
coeffs = np.polyfit(x, y, degree)
result['polynomial'] = coeffs.tolist() p = np.poly1d(coeffs)
yhat = p(x)
ybar = np.sum(y)/len(y)
ssreg = np.sum((yhat - ybar)**2)
sstot = np.sum((y - ybar)**2)
result['determination'] = ssreg / sstot return result #测试
print(polyfit(testX, testY, 1)["determination"])
#r^2:0.884183040052
机器学习-回归中的相关度和R平方值的更多相关文章
- day-14 回归中的相关系数和决定系数概念及Python实现
衡量一个回归模型常用的两个参数:皮尔逊相关系数和R平方 一.皮尔逊相关系数 在统计学中,皮尔逊相关系数( Pearson correlation coefficient),又称皮尔逊积矩相关系数(Pe ...
- 斯坦福《机器学习》Lesson4感想--1、Logistic回归中的牛顿方法
在上一篇中提到的Logistic回归是利用最大似然概率的思想和梯度上升算法确定θ,从而确定f(θ).本篇将介绍还有一种求解最大似然概率ℓ(θ)的方法,即牛顿迭代法. 在牛顿迭代法中.如果一个函数是,求 ...
- Apache Spark 2.2.0 中文文档 - SparkR (R on Spark) | ApacheCN
SparkR (R on Spark) 概述 SparkDataFrame 启动: SparkSession 从 RStudio 来启动 创建 SparkDataFrames 从本地的 data fr ...
- 回归模型效果评估系列3-R平方
决定系数(coefficient of determination,R2)是反映模型拟合优度的重要的统计量,为回归平方和与总平方和之比.R2取值在0到1之间,且无单位,其数值大小反映了回归贡献的相对程 ...
- Echarts实现Excel趋势线和R平方计算思路
测试数据 [19550, 7.1 ],[22498, 8.44 ],[25675, 9.56 ],[27701, 10.77],[29747, 11.5 ],[32800, 12.27],[34822 ...
- 机器学习算法中的准确率(Precision)、召回率(Recall)、F值(F-Measure)
摘要: 数据挖掘.机器学习和推荐系统中的评测指标—准确率(Precision).召回率(Recall).F值(F-Measure)简介. 引言: 在机器学习.数据挖掘.推荐系统完成建模之后,需要对模型 ...
- 【笔记】逻辑回归中使用多项式(sklearn)
在逻辑回归中使用多项式特征以及在sklearn中使用逻辑回归并添加多项式 在逻辑回归中使用多项式特征 在上面提到的直线划分中,很明显有个问题,当样本并没有很好地遵循直线划分(非线性分布)的时候,其预测 ...
- javascript基础程序(算出一个数的平方值、算出一个数的阶乘、输出!- !- !- !- !- -! -! -! -! -! 、函数三个数中的最大数)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 今天在Mac机器上使用了Flex Builder编辑了一个源代码文件,保存后使用vim命令去打开时发现系统自动在每一行的结尾添加了^M符号,其实^M在Linux/Unix中是非常常见的,也就是我们在Win中见过的/r回车符号。由于编辑软件的编码问题,某些IDE的编辑器在编辑完文件之后会自动加上这个^M符号。看起来对我们的源代码没有任何影响,其实并不然,当我们把源代码文件Check In到svn之类
今天在Mac机器上使用了Flex Builder编辑了一个源代码文件,保存后使用vim命令去打开时发现系统自动在每一行的结尾添加了^M符号,其实^M在Linux/Unix中是非常常见的,也就是我们在W ...
随机推荐
- LeetCode 22. 括号生成(Generate Parentheses)
题目描述 给出 n 代表生成括号的对数,请你写出一个函数,使其能够生成所有可能的并且有效的括号组合. 例如,给出 n =3,生成结果为: [ "((()))", "(() ...
- axios 的用法解析
axios 的非常好的请求数据方式,利用了 promise 的方式来进行的操作 首先 promise 是非常好的处理 异步请求的方式,且拥有高并发请求的能力 并发请求:出现大量的异步请求后,一起处理 ...
- js对数组分组处理
一.js数组分组 1.js对数据分组类似group by 源码如下: <!DOCTYPE html> <html lang="en"> <head&g ...
- C#的语音识别 using System.Speech.Recognition;
using System; using System.Collections.Generic; using System.Linq; using System.Speech.Recognition; ...
- Activity 怎么和 Service 绑定,怎么在 Activity 中启动自己对应的 Service?
Activity 通过 bindService(Intent service, ServiceConnection conn, int flags)跟 Service 进行绑定,当绑定成功的时候 Se ...
- web.py下获取get参数
比较简单,就直接上代码了: import web urls = ( '/', 'hello' ) app = web.application(urls, globals()) class hello: ...
- centos7.7下docker与k8s安装(DevOps三)
1.系统配置 centos7.7 docker 1.13.1 centos7下安装docker:https://www.cnblogs.com/pu20065226/p/10536744.html 2 ...
- 437路径总和III
题目: 给定一个二叉树,它的每个结点都存放着一个整数值.找出路径和等于给定数值的路径总数.路径不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点).来源: ht ...
- MySQL备份工具之mysqlhotcopy
mysqlhotcopy使用lock tables.flush tables和cp或scp来快速备份数据库.它是备份数据库或单个表最快的途径,完全属于物理备份,但只能用于备份MyISAM存储引擎和运行 ...
- 《Python编程从0到1》笔记5——图解递归你肯定看完就能懂!
本小节的示例比较简单,因为在每次递归过程中原问题仅缩减为单个更小的问题.这样的问题往往能够用简单循环解决.这类递归算法的函数调用图是链状结构.这种递归类型被称为“单重递归”(single recurs ...