机器学习算法中的准确率(Precision)、召回率(Recall)、F值(F-Measure)
摘要:
数据挖掘、机器学习和推荐系统中的评测指标—准确率(Precision)、召回率(Recall)、F值(F-Measure)简介。
引言:
在机器学习、数据挖掘、推荐系统完成建模之后,需要对模型的效果做评价。
业内目前常常采用的评价指标有准确率(Precision)、召回率(Recall)、F值(F-Measure)等,下图是不同机器学习算法的评价指标。下文讲对其中某些指标做简要介绍。
本文针对二元分类器!
本文针对二元分类器!!
本文针对二元分类器!!!
对分类的分类器的评价指标将在以后文章中介绍。
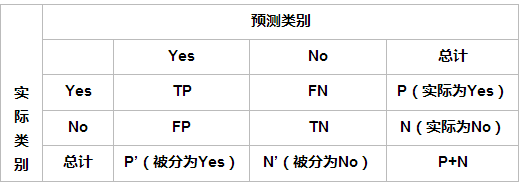
在介绍指标前必须先了解“混淆矩阵”:
混淆矩阵
True Positive(真正,TP):将正类预测为正类数
True Negative(真负,TN):将负类预测为负类数
False Positive(假正,FP):将负类预测为正类数误报 (Type I error)
False Negative(假负,FN):将正类预测为负类数→漏报 (Type II error)

1、准确率(Accuracy)
准确率(accuracy)计算公式为:
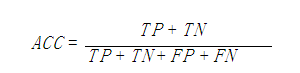
注:准确率是我们最常见的评价指标,而且很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
准确率确实是一个很好很直观的评价指标,但是有时候准确率高并不能代表一个算法就好。比如某个地区某天地震的预测,假设我们有一堆的特征作为地震分类的属性,类别只有两个:0:不发生地震、1:发生地震。一个不加思考的分类器,对每一个测试用例都将类别划分为0,那那么它就可能达到99%的准确率,但真的地震来临时,这个分类器毫无察觉,这个分类带来的损失是巨大的。为什么99%的准确率的分类器却不是我们想要的,因为这里数据分布不均衡,类别1的数据太少,完全错分类别1依然可以达到很高的准确率却忽视了我们关注的东西。再举个例子说明下。在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc也有 99% 以上,没有意义。因此,单纯靠准确率来评价一个算法模型是远远不够科学全面的。
2、错误率(Error rate)
错误率则与准确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(TP+TN+FP+FN),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
3、灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
4、特效度(sensitive)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
5、精确率、精度(Precision)
精确率(precision)定义为:
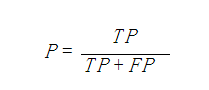
表示被分为正例的示例中实际为正例的比例。
6、召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
7、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。
F-Measure是Precision和Recall加权调和平均:
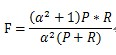
当参数α=1时,就是最常见的F1,也即
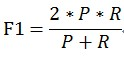
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
8、其他评价指标
计算速度:分类器训练和预测需要的时间;
鲁棒性:处理缺失值和异常值的能力;
可扩展性:处理大数据集的能力;
可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
下面来看一下ROC和PR曲线(以下内容为自己总结):
1、ROC曲线:
ROC(Receiver Operating Characteristic)曲线是以假正率(FP_rate)和假负率(TP_rate)为轴的曲线,ROC曲线下面的面积我们叫做AUC,如下图所示:
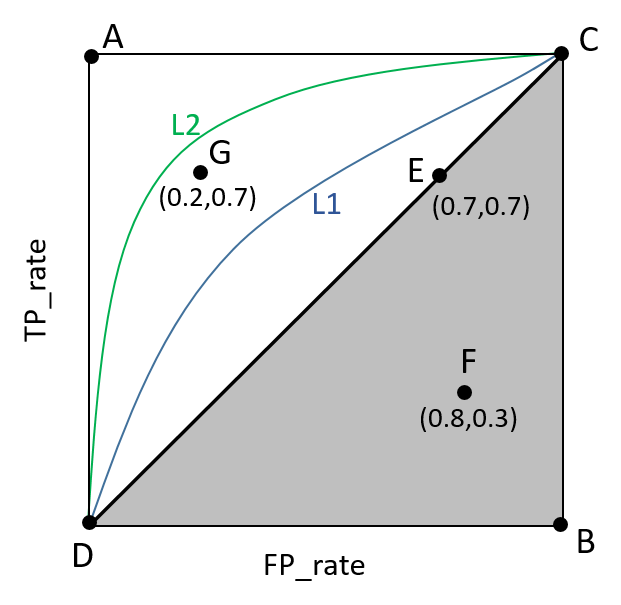
图片根据Paper:Learning from eImbalanced Data画出
其中: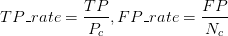
(1)曲线与FP_rate轴围成的面积(记作AUC)越大,说明性能越好,即图上L2曲线对应的性能优于曲线L1对应的性能。即:曲线越靠近A点(左上方)性能越好,曲线越靠近B点(右下方)曲线性能越差。
(2)A点是最完美的performance点,B处是性能最差点。
(3)位于C-D线上的点说明算法性能和random猜测是一样的–如C、D、E点。位于C-D之上(即曲线位于白色的三角形内)说明算法性能优于随机猜测–如G点,位于C-D之下(即曲线位于灰色的三角形内)说明算法性能差于随机猜测–如F点。
(4)虽然ROC曲线相比较于Precision和Recall等衡量指标更加合理,但是其在高不平衡数据条件下的的表现仍然过于理想,不能够很好的展示实际情况。
2、PR曲线:
即,PR(Precision-Recall)曲线。
举个例子(例子来自Paper:Learning from eImbalanced Data):
假设N_c>>P_c(即Negative的数量远远大于Positive的数量),若FP很大,即有很多N的sample被预测为P,因为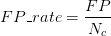
机器学习算法中的准确率(Precision)、召回率(Recall)、F值(F-Measure)的更多相关文章
- 准确率(Precision),召回率(Recall)以及综合评价指标(F1-Measure)
准确率和召回率是数据挖掘中预测,互联网中得搜索引擎等经常涉及的两个概念和指标. 准确率:又称“精度”,“正确率” 召回率:又称“查全率” 以检索为例,可以把搜索情况用下图表示: 相关 不相关 检索 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
yu Code 15 Comments 机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accu ...
- fashion_mnist 计算准确率、召回率、F1值
本文发布于 2020-12-27,很可能已经过时 fashion_mnist 计算准确率.召回率.F1值 1.定义 首先需要明确几个概念: 假设某次预测结果统计为下图: 那么各个指标的计算方法为: A ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure(对于二分类问题)
首先我们可以计算准确率(accuracy),其定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比.也就是损失函数是0-1损失时测试数据集上的准确率. 下面在介绍时使用一下例子: 一个 ...
- 目标检测评价标准(mAP, 精准度(Precision), 召回率(Recall), 准确率(Accuracy),交除并(IoU))
1. TP , FP , TN , FN定义 TP(True Positive)是正样本预测为正样本的数量,即与Ground truth区域的IoU>=threshold的预测框 FP(Fals ...
- 精确率、准确率、召回率和F1值
当我们训练一个分类模型,总要有一些指标来衡量这个模型的优劣.一般可以用如题的指标来对预测数据做评估,同时对模型进行评估. 首先先理解一下混淆矩阵,混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用 ...
- keras如何求分类问题中的准确率和召回率
https://www.zhihu.com/question/53294625 由于要用keras做一个多分类的问题,评价标准采用precision,recall,和f1_score:但是keras中 ...
- 机器学习 F1-Score 精确率 - P 准确率 -Acc 召回率 - R
准确率 召回率 精确率 : 准确率->accuracy, 精确率->precision. 召回率-> recall. 三者很像,但是并不同,简单来说三者的目的对象并不相同. 大多时候 ...
- 准确率和召回率(precision&recall)
在机器学习.推荐系统.信息检索.自然语言处理.多媒体视觉等领域,常常会用到准确率(precision).召回率(recall).F-measure.F1-score 来评价算法的准确性. 一.准确率和 ...
随机推荐
- 指导手册03:Hadoop基础操作
指导手册03:Hadoop基础操作 Part 1:查看Hadoop集群的基本信息1.查询存储系统信息(1)在WEB浏览器的地址栏输入http://master:50070/ 请查看自己的Hadoop集 ...
- Redis常用命令与高级应用
附: 127.0.0.1:6379> set xiaofei 小飞 OK 127.0.0.1:6379> get xiaofei "\xe5\xb0\x8f\xe9\xa3\x9 ...
- Linux:CentOS 7系统的安装
相信有看过我写的博文就知道我写的第一篇博文就是CentOS 7系统的安装,不过是在虚拟机中安装的,而且还是直接加载镜像文件进去的,不过这次我就通过PE来安装,来证实下PE是否可以用来安装Linux系统 ...
- c++ 生成dll文件并调用-转
.h(头文件) .lib(库文件) .dll(动态链接库文件) 之间的关系和作用的区分 .h头文件是编译时必须的,lib是链接时需要的,dll是运行时需要的. 附加依赖项的是.lib不是.dll, ...
- 关于$\mathcal{D}(0,1)$上的一个有趣结论
[转载请注明出处]http://www.cnblogs.com/mashiqi 2017/02/20 在$\mathcal{D}(0,1)$上取定$\varphi_0 \in \mathcal{D}( ...
- php连接redis服务
$redis = new Redis(); $redis->connect('127.0.0.1', 6379);//可以执行redis操作了.....
- Scala环境(集成idea)
1 语言介绍 他已经出生15年了,就像明星一样,谁都不可能一开始就人气爆棚粉丝无数,得慢慢混. 据说这家伙已经威胁到了Java的地位,我当时也是被这句话惊到,才毅然决然的认识了他.目前也正在努力学习中 ...
- Mysql组复制之单主模式(一)
环境 系统:CentOS release 6.9 (Final) Mysql:5.7 机器: S1 10.0.0.7 lemon S2 10.0.0.8 lemon2 S3 10.0.0.9 lemo ...
- linux上安装memcached步骤
libevent: http://libevent.org/ 服务器端:https://code.google.com/archive/p/memcached/downloads 客户端: http: ...
- 在flask框架中,对wtforms的SelectMultipleField的一个报错处理
先粘贴代码: form.py文件: users = SelectMultipleField( label="请选择用户", validators=[ DataRequired(&q ...