Python爬虫实战——反爬策略之模拟登录【CSDN】
在《Python爬虫实战—— Request对象之header伪装策略》中,我们就已经讲到:“在header当中,我们经常会添加两个参数——cookie 和 User-Agent,来模拟浏览器登录,以此提高绕过后台服务器反爬策略的可能性。”
User-Agent已经讲过,这篇我们则主要讲cookie的使用案例。
通俗地讲:User-Agent的作用是模拟浏览器,cookie的作用是模拟登陆,所以二者合起来,便是模拟浏览器登录啦。
为了方便理解,现在我们试一下爬取CSDN学院中自己的收藏的课程。
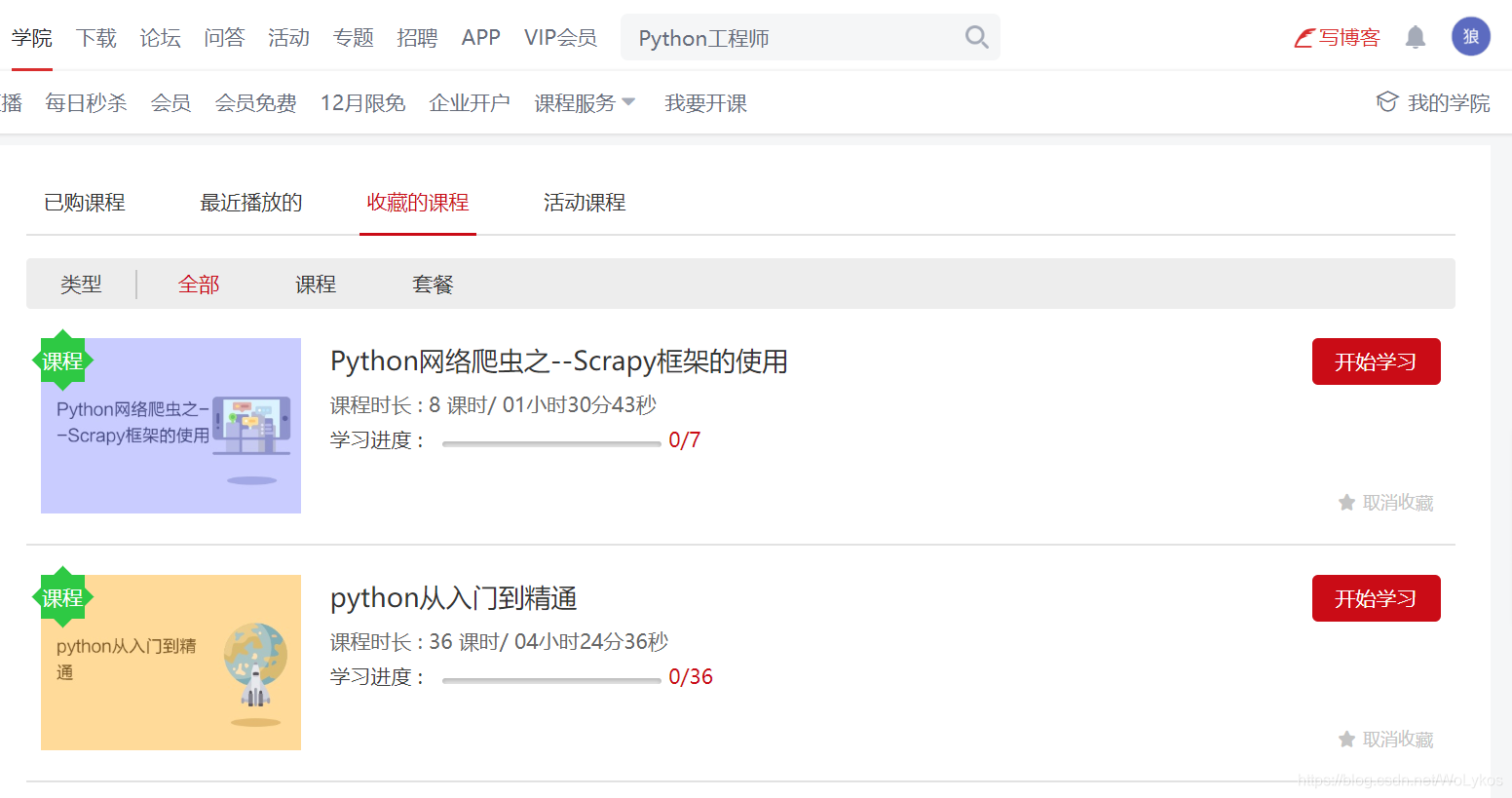
1. 为了验证,我麻溜地瞎收藏了几个课程:
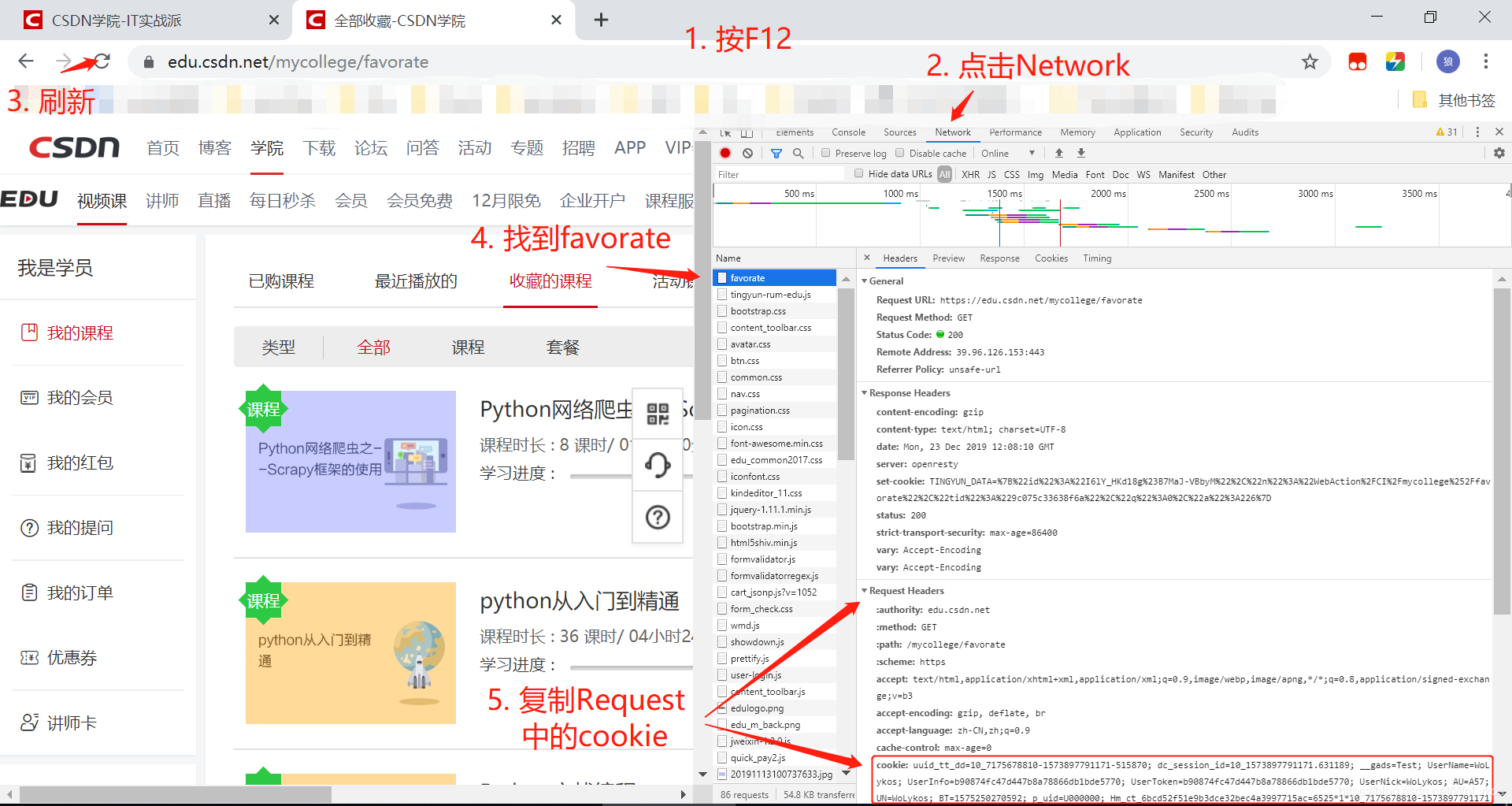
2. 获取cookie:
3. 创建一个request对象:
import urllib.request as ur
import user_agent
import lxml.etree as le
request = ur.Request(
url='https://edu.csdn.net/mycollege/favorate',
headers={
'User-Agent': user_agent.get_user_agent_pc(),
'Cookie': 'uuid_tt_dd=10_7175678810-1573897791171-515870; dc_session_id=10_1573897791171.631189; __gads=Test; UserName=WoLykos; UserInfo=b90874fc47d447b8a78866db1bde5770; UserToken=b90874fc47d447b8a78866db1bde5770; UserNick=WoLykos; AU=A57; UN=WoLykos; BT=1575250270592; p_uid=U000000; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_7175678810-1573897791171-515870!5744*1*WoLykos; acw_tc=2760823f15766000004357185efdb2fe81badf98c5418fdaaa006c8fb641e2; UM_distinctid=16f1e154f3e6fc-06a15022d8e2cb-7711a3e-e1000-16f1e154f3f80c; Hm_lvt_e5ef47b9f471504959267fd614d579cd=1576843409; Hm_ct_e5ef47b9f471504959267fd614d579cd=5744*1*WoLykos!6525*1*10_7175678810-1573897791171-515870; __yadk_uid=BWljcDoqISiHxWKSFRvypn90shczp7Ay; firstDie=1; ADHOC_MEMBERSHIP_CLIENT_ID1.0=fa924465-1b26-cf9e-e00b-4ca8a6fe68e2; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1576889587,1577070936,1577087859,1577098502; PHPSESSID=5nfs1s5g2kl8hiot0duljcaao6; TY_SESSION_ID=820b1d6d-9ef0-4d5b-8dea-a74643320a77; cname10651=1; dc_tos=q2ys77; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1577102659; announcement=%257B%2522isLogin%2522%253Atrue%252C%2522announcementUrl%2522%253A%2522https%253A%252F%252Fblog.csdn.net%252Fblogdevteam%252Farticle%252Fdetails%252F103603408%2522%252C%2522announcementCount%2522%253A0%252C%2522announcementExpire%2522%253A3600000%257D',
}
)
4. 将response结果写入到本地文件:
response = ur.urlopen(request).read().decode('utf-8')
# 由于response是字符串类型,所以此处只需‘w’即可
with open('myfavorate.html', 'w', encoding='utf-8') as f:
f.write(response)
结果如下:
5. 如果注释掉cookie又会如何呢:
import urllib.request as ur
import user_agent
import lxml.etree as le
request = ur.Request(
url='https://edu.csdn.net/mycollege/favorate',
headers={
'User-Agent': user_agent.get_user_agent_pc(),
}
)
response = ur.urlopen(request).read().decode('utf-8')
# 由于response是字符串类型,所以此处只需‘w’即可
with open('myfavorate2.html', 'w', encoding='utf-8') as f:
f.write(response)
结果如下:

注意:
这是一个重定向,转至CSDN的登录界面。
6. 利用XPath提取课程名称:
import lxml.etree as le
# 加载文本内容
html_x = le.HTML(response)
# 提取当前用户收藏的课程名称
title_s = html_x.xpath('//li[@class="item_box"]//h1/a/text()')
print(title_s)
输出如下:

全文完整代码:
import urllib.request as ur
import user_agent
import lxml.etree as le
request = ur.Request(
url='https://edu.csdn.net/mycollege/favorate',
headers={
'User-Agent': user_agent.get_user_agent_pc(),
'Cookie': 'uuid_tt_dd=10_7175678810-1573897791171-515870; dc_session_id=10_1573897791171.631189; __gads=Test; UserName=WoLykos; UserInfo=b90874fc47d447b8a78866db1bde5770; UserToken=b90874fc47d447b8a78866db1bde5770; UserNick=WoLykos; AU=A57; UN=WoLykos; BT=1575250270592; p_uid=U000000; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_7175678810-1573897791171-515870!5744*1*WoLykos; acw_tc=2760823f15766000004357185efdb2fe81badf98c5418fdaaa006c8fb641e2; UM_distinctid=16f1e154f3e6fc-06a15022d8e2cb-7711a3e-e1000-16f1e154f3f80c; Hm_lvt_e5ef47b9f471504959267fd614d579cd=1576843409; Hm_ct_e5ef47b9f471504959267fd614d579cd=5744*1*WoLykos!6525*1*10_7175678810-1573897791171-515870; __yadk_uid=BWljcDoqISiHxWKSFRvypn90shczp7Ay; firstDie=1; ADHOC_MEMBERSHIP_CLIENT_ID1.0=fa924465-1b26-cf9e-e00b-4ca8a6fe68e2; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1576889587,1577070936,1577087859,1577098502; PHPSESSID=5nfs1s5g2kl8hiot0duljcaao6; TY_SESSION_ID=820b1d6d-9ef0-4d5b-8dea-a74643320a77; cname10651=1; dc_tos=q2ys77; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1577102659; announcement=%257B%2522isLogin%2522%253Atrue%252C%2522announcementUrl%2522%253A%2522https%253A%252F%252Fblog.csdn.net%252Fblogdevteam%252Farticle%252Fdetails%252F103603408%2522%252C%2522announcementCount%2522%253A0%252C%2522announcementExpire%2522%253A3600000%257D',
}
)
response = ur.urlopen(request).read().decode('utf-8')
# 由于response是字符串类型,所以此处只需‘w’即可
# with open('myfavorate2.html', 'w', encoding='utf-8') as f:
# f.write(response)
# 加载文本内容
html_x = le.HTML(response)
# 提取当前用户收藏的课程名称
title_s = html_x.xpath('//li[@class="item_box"]//h1/a/text()')
print(title_s)
为我心爱的女孩~~
Python爬虫实战——反爬策略之模拟登录【CSDN】的更多相关文章
- Python爬虫实战——反爬策略之代理IP【无忧代理】
一般情况下,我并不建议使用自己的IP来爬取网站,而是会使用代理IP. 原因很简单:爬虫一般都有很高的访问频率,当服务器监测到某个IP以过高的访问频率在进行访问,它便会认为这个IP是一只"爬虫 ...
- 抖音爬虫教程,python爬虫采集反爬策略
一.爬虫与反爬简介 爬虫就是我们利用某种程序代替人工批量读取.获取网站上的资料信息.而反爬则是跟爬虫的对立面,是竭尽全力阻止非人为的采集网站信息,二者相生相克,水火不容,到目前为止大部分的网站都还是可 ...
- Python爬虫实战——反爬机制的解决策略【阿里】
这一次呢,让我们来试一下"CSDN热门文章的抓取". 话不多说,让我们直接进入CSND官网. (其实是因为我被阿里的反爬磨到没脾气,不想说话--) 一.URL分析 输入" ...
- 【Day5】3.反爬策略之模拟登录
import urllib.request as ur import user_agent import lxml.etree as le request = ur.Request( url='htt ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- 原创:Python爬虫实战之爬取美女照片
这个素材是出自小甲鱼的python教程,但源码全部是我原创的,所以,猥琐的不是我 注:没有用header(总会报错),暂时不会正则表达式(马上要学了),以下代码可能些许混乱,不过效果还是可以的. 爬虫 ...
- python爬虫--cookie反爬处理
Cookies的处理 作用 保存客户端的相关状态 在爬虫中如果遇到了cookie的反爬如何处理? 手动处理 在抓包工具中捕获cookie,将其封装在headers中 应用场景:cookie没有有效时长 ...
- Python爬虫-字体反爬-猫眼国内票房榜
偶然间知道到了字体反爬这个东西, 所以决定了解一下. 目标: https://maoyan.com/board/1 问题: 类似下图中的票房数字无法获取, 直接复制粘贴的话会显示 □ 等无法识别的字 ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
随机推荐
- 练手项目之image caption问题记录
小白一个,刚刚费了老大的劲完成一个练手项目--image caption,虽然跑通了,但是评估结果却惨不忍睹.于是贴上大神的作品,留待日后慢慢消化.顺便记录下自己踩坑的一些问题. 先膜拜下大神的作品. ...
- enumerate()(Python)
>>> E=enumerate('spam') >>> E <enumerate object at 0x1021ceca8> >>> ...
- Python深度学习
序言 目的驱动型学习 概念解释 资料 https://www.tensorflow.org/ https://www.imooc.com/video/17186 https://www.cnblogs ...
- imp需要
导入全部: imp user/password@10.10.10.10:1521/orcl file = C:\Users\Administrator\Desktop\20170404230000.d ...
- Losing session data in ASP.NET
Losing session data in ASP.NET By default Response.Redirect terminates thread execution and there mi ...
- QTP学习笔记1
1.将变量值写入datatable/ 从datatable中取值赋给变量 DataTable("列名","sheet名") = 变量名 变量名 = DataTa ...
- leetcode上的一些栈、队列问题
20-有效的括号 思路:主要考察栈的一些基本操作,像push()(将数据压入栈顶).top()(取栈顶的数据但不删除).pop()(直接删除栈顶的元素).empty()(判断栈是否为空).这题就是先把 ...
- 爬取猎聘大数据岗位相关信息--Python
猎聘网站搜索大数据关键字,只能显示100页,爬取这一百页的相关信息,以便做分析. __author__ = 'Fred Zhao' import requests from bs4 import Be ...
- HTML5: HTML5 Audio(音频)
ylbtech-HTML5: HTML5 Audio(音频) 1.返回顶部 1. HTML5 Audio(音频) HTML5 提供了播放音频文件的标准. 互联网上的音频 直到现在,仍然不存在一项旨在网 ...
- docker-compose 搭建 Redis Sentinel 测试环境
docker-compose 搭建 Redis Sentinel 测试环境 本文介绍如何使用 docker-compose 快速搭建一个 Redis Sentinel 测试环境.其中 Redis 集群 ...