【转】分布式存储和一致性hash
本文我将对一致性算法作介绍,同时谈谈自己对一致性hash和一般意义上的hash算法的区别
hash是什么
hash即hash算法,又称为散列算法,百度百科的定义是
哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。
1.这句话有几个很重要的地方,首先是任意长度二进制,在java中,可以代表所有对象(序列化)
2.固定长度,使得hashmap等可以按照高低位进行位操作,同时能够提供统一的方式(有种协议的感觉)
3.数据唯一的数值,使得hashcode可以作为查找的依据(快速查找的根本)
为什么hash
说为什么首先要说说如果没有会怎么样。
csdn有这样一篇文章讲的很有意思,我们有一堆猪,怎么根据体重找到对应的一头。如果没有hash的思想,我们会比较每头猪,但是如果有1000头你也这样做么。引入hash,每头猪的重量hash到一个hashcode,hashcode会映射到对应的猪圈,我们只要比较每个猪圈的猪就行了,而最理想的情况就是每个猪圈的猪都一样多(注:每个猪圈一个是好,但是空间消耗巨大)
(http://blog.csdn.net/ok7758521ok/article/details/4003476)
而java中,hash也是采用这样的方式,通过hashcode与桶数取模的方式(当然时间是通过位操作,性能更高)自然映射到具体的桶中。
关于分布式存储
当hash遇上分布式,单台机子的hashmap存储已经不能满足我们的key-value需求,怎么办,我们需要把存储内容分布到不同的实体机上,这时需要一种把key映射到不同机器的方法,我们想起了hash,可以把实体机当做是桶,采用和hashmap实现一样的思路,通过和实体机的数量取模,自然映射到不同的机器。
ok,搞定,分布式确实可以实现。但现在问题来了,如果其中一台机子挂了,或者又加了一台机子怎么办,这时出现两种情况:
1.不做任何改变,那么挂了的数据将无法得到恢复,新增的机子也无法得到利用
2.rehash 这种情况,桶的数量将会改变,所有的值将重新映射,最终数据会得到存储,这有两个问题,rehash的时刻,所有key将重新映射,这时,对于大并发的情形,是灾难的,所有请求将不经过任何缓存,服务器面临崩溃的风险,再者,老的数据依然还在,并且不会被用到,浪费存储空间。
那么,怎么办
引入一致性hash
consistent hashing 是这样一种 hash 算法,简单的说,在移除 / 添加一个 节点(机器,ip)时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性()的要求。
hash回环
任何的hash值都是固定长度的,因此可以通过一个回环来承载所有的hash值(为什么用环后面会说)
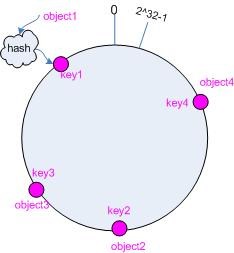
映射
hash最总要的一步就是把对象映射到对应的桶,而与通常的hash做法相比,一致性hash会比较特殊,一致性hash不会将key直接映射到桶,而将key和桶分别映射到回环的对应hash值节点
映射key
映射桶
接下来是最重要的一步,把key映射到对应的桶
寻桶
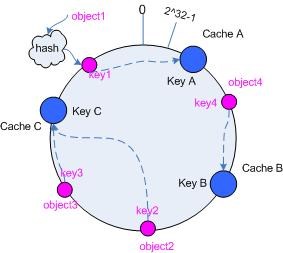
现在 cache 和对象都已经通过同一个 hash 算法映射到 hash 数值空间中了,接下来要考虑的就是如何将对象映射到 cache 上面了。
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 cache ,那么就将该对象存储在这个 cache 上,因为对象和 cache 的 hash 值是固定的,因此这个 cache 必然是唯一和确定的。这样不就找到了对象和 cache 的映射方法了吗?!
依然继续上面的例子(参见图 3 ),那么根据上面的方法,对象 object1 将被存储到 cache A 上; object2和 object3 对应到 cache C ; object4 对应到 cache B ;
好处
我们讲了这么多一致性hash的算法,那么他究竟带来了什么,我们分添加和删除的情况考虑
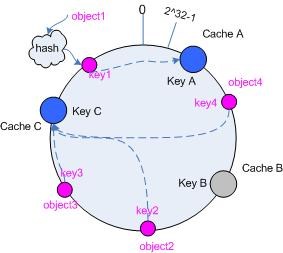
添加
我们添加一个新的节点D,按照顺时针的方式,原先映射到C的object2会映射到D,而object3则还是映射到C,这样添加只会影响到object2,事实上是B和D之间的对象,这种影响相比传统的方式,影响是很小的
删除
与添加类似,删除也只会影响A和B之间的对象
虚拟节点(一下完全引自:http://my.oschina.net/jsan/blog/49702)
考量 Hash 算法的另一个指标是平衡性 (Balance) ,定义如下:
平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡,如果 cache 较少的话,对象并不能被均匀的映射到 cache 上,比如在上面的例子中,仅部署 cache A 和 cache C 的情况下,在 4 个对象中, cache A 仅存储了 object1 ,而 cache C 则存储了 object2 、 object3 和 object4 ;分布是很不均衡的。
为了解决这种情况, consistent hashing 引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”( virtual node )是实际节点在 hash 空间的复制品( replica ),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。
仍以仅部署 cache A 和 cache C 的情况为例,在图 4 中我们已经看到, cache 分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为 2 ,这就意味着一共会存在 4 个“虚拟节点”, cache A1, cache A2 代表了 cache A ; cache C1, cache C2 代表了 cache C ;假设一种比较理想的情况,参见图 6 。

图 6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2 ; objec2->cache A1 ; objec3->cache C1 ; objec4->cache C2 ;
因此对象 object1 和 object2 都被映射到了 cache A 上,而 object3 和 object4 映射到了 cache C 上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从 { 对象 -> 节点 } 转换到了 { 对象 -> 虚拟节点 } 。查询物体所在 cache时的映射关系如图 7 所示。
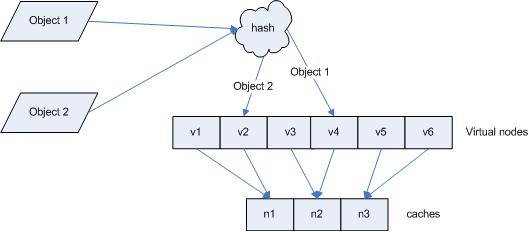
图 7 查询对象所在 cache
“虚拟节点”的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为202.168.14.241 。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2
参考
http://my.oschina.net/u/1166485/blog/136663
http://my.oschina.net/jsan/blog/49702
转自:https://my.oschina.net/zhenglingfei/blog/405622
【转】分布式存储和一致性hash的更多相关文章
- Memcache 分布式存储 【一致性Hash】crc32
class memcacheHash { private $_node = array(); private $_nodeData = array(); private $_keyNode = 0; ...
- tornado--SESSION框架,一致性hash,分布式存储
预备知识 tornado框架session要自己写 cookie存储在客户端浏览器上,session数据放在服务器上 session依赖cookie 扩展tornado,返回请求前自定义session ...
- 一致性hash应用到redis
理解分布式存储的本质 有一个经典的实践经验: 数(值)据大了, 什么都是问题! 如果要求128B或更大数值计算, 哪么四则运算会是个大问题! 如果要求128T或更大日志存储, 哪么文件存储会是个大问题 ...
- php一致性hash算法的应用
阅读这篇博客前首先你需要知道什么是分布式存储以及分布式存储中的数据分片存储的方式有哪些? 分布式存储系统设计(2)—— 数据分片 阅读玩这篇文章后你会知道分布式存储的最优方案是使用 一致性hash算法 ...
- 分布式一致性hash算法
写在前面 在学习Redis的集群内容时,看到这么一句话:Redis并没有使用一致性hash算法,而是引入哈希槽的概念.而分布式缓存Memcached则是使用分布式一致性hash算法来实现分布式存储. ...
- 01--是时候让我们谈谈一致性hash了
--------------------- 假如你有图中三个盒子,我们有代号为 1,4,5,12 这四样东西 那根据代号作为主键,将东西放到盒子了,该如何放置? 我们可以对代号取模 1 mod 3 = ...
- dht 分布式hash 一致性hash区别
先有一致性hash :一致性哈希,似乎最早提出是在分布式缓存里面的,让节点震荡的时候,影响最小.不过现在已经应用在分布式存储和p2p系统里面. dht 是p2p领域的概念,内有三大概念是由keyspa ...
- 图解一致性hash算法和实现
更多内容,欢迎关注微信公众号:全菜工程师小辉.公众号回复关键词,领取免费学习资料. 一致性hash算法是什么? 一致性hash算法,是麻省理工学院1997年提出的一种算法,目前主要应用于分布式缓存当中 ...
- 分布式算法-一致性HASH
分布式算法 参考: https://blog.51cto.com/alanwu/1431397 https://blog.csdn.net/kojhliang/article/details/8120 ...
随机推荐
- selenium学习笔记(HTMLTestRunner测试报告)
之前提到selenium加入unittest框架.可以引入HTMLTestRunner扩展.以此来生成测试报告 首先是分享下载的百度云地址 http://pan.baidu.com/s/1pKUItW ...
- Git的add、commit、push命令
简单的代码提交流程1.git status 查看工作区代码相对于暂存区的差别2.git add . 将当前目录下修改的所有代码从工作区添加到暂存区 . 代表当前目录3.git commit -m ‘注 ...
- Vector3函数理解-计算两向量之间的角度
1.已知两个向量dirA,dirB.Vector3 dirA = new Vector3(-1,1,0); Vector3 dirB = new Vector3(-1,1,1);2.使向量处于同一个平 ...
- MySql的数据库文件
找到mysql安装目录下的一个叫my.ini的文件用记事本或者其他的文本编辑器打开. 找到datadir这个字段,这个地址就是mysql数据库的地址 另附my.ini详解 Mysql my.ini 配 ...
- Neutron的安全组原理
Security group通过Linux IPtables来实现,为此,在Compute节点上引入了qbr*这样的Linux传统bridge(iptables规则目前无法加载到直接挂在到ovs的 ...
- Eclipse Android 代码自动提示功能
Eclipse Android 代码自动提示功能 Eclipse for android 实现代码自动提示智能提示功能,介绍 Eclipse for android 编辑器中实现两种主要文件 java ...
- ROS中使用ABB Yumi IRB14000的一些资料汇总
目前,ABB RobotStudio 已经更新到6.05.01了,可至官网下载. 使用ABB RobotStudio和ROS进行联合调试,请参考下文: http://blog.csdn.net/Zha ...
- Kali Linux ettercap的使用
ettercap是执行ARP欺骗嗅探的工具,通常用它来施行中间人攻击. 我还介绍过另一个arp欺骗工具-arpspoof 我使用的是Kali Linux 2.0:在开始使用ettercap之前,先配置 ...
- 前端之JavaScript 01
一JavaScript介绍 js历史 1992年Nombas开发出C-minus-minus(C--)的嵌入式脚本语言(最初绑定在CEnvi软件中).后将其改名ScriptEase.(客户端执行的语言 ...
- 进程(并发,并行) join start 进程池 (同步异步)
一.背景知识 顾名思义,进程即正在执行的一个过程.进程是对正在运行程序的一个抽象.进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一.操作系统的其他所有 ...