HTTP/1.1 持久连接 persistent connection
首先:HTTP的长连接和短连接本质上是TCP长连接和短连接。
1. 在HTTP1.0中,默认的是短连接,没有正式规定 Connection:Keep-alive 操作;在HTTP1.1中所有连接都是Keep-alive的,也就是默认都是持续连接的(Persistent Connection)。
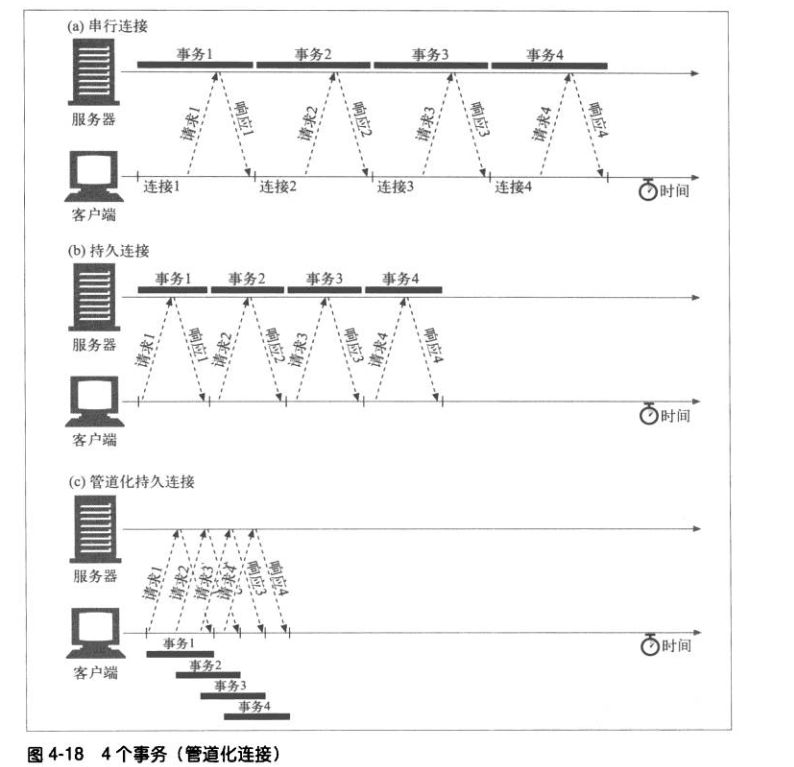
2. 两种的连接方式的区别如下图所示

3. 从上图可以看出,客户端与服务器建立持续连接后,在连接期间可以处理多个请求/响应(Request/Response)
HTTP权威指南:
HTTP/1.1 允许HTTP设备在事务处理结束以后将TCP连接保持在打开状态,后面的HTTP Request/Response 依然可以通过这个TCP连接继续传送。
在事务结束之后仍然保持在打开状态的TCP连接成为持久链接。非持久连接会在每个事务结束后关闭,持久连接会在不同事务(Request/Response)之间保持打开状态,知道客户端或服务器决定将其关闭为止。
可以提高HTTP连接性能的方法:
并行连接
通过多条连接发起并发的HTTP请求。并行连接可以提高复合页面的传输速度,但其连接也有一些缺点
每个事务都会打开/关闭一条新的连接,会耗费时间和带宽。由于TCP慢启动特性存在,每条连接的性能都会有所降低。可打开的并行连接数量实际上是有限的
持久化连接
Web客户端经常会打开到同一个站点的连接。比如,一个Web页面上的大部分内嵌图片通常来自同一个Web站点,而且相当一部分指向其他对象的超链通常都指向同一个站点。初始化了对某服务器HTTP请求的应用程序很可能会不久的将来对那台服务器发起更多的请求,这种性质称为站点局部性。
因此,HTTP/1.1允许HTTP设备在事务处理结束之后将TCP连接保持在打开状态,以便为未来的HTTP请求重用现存的连接。在事务处理结束之后仍然保持在打开状态的TCP连接称之为持久连接。持久连接会在不同事务之间保持打开状态,直到客户端或服务器决定其关闭为之。重用已对目标服务器打开的空闲持久连接,就可以避开缓慢的连接建立阶段。而且,已经打开的连接还可以避免慢启动的拥塞适应阶段,以便更快速地进行数据传输。所以,持久连接降低了时延和连接建立的开销,将连接保持在已调谐状态,而且减少了打开连接的潜在数量。
持久连接和并行连接配合使用可能是最高效的方式。很多Web应用程序都会打开少量的并行连接,其中每个都是持久连接。持久连接有两种类型
1)HTTP/1.0 + keep-alive 连接
2) HTTP/1.1 + persistent 连接
HTTP/1.0 keep-alive连接
现在很多客户端和服务器仍然在使用这些早期的keep-live连接。
实现HTTP/1.0 keep-live连接的客户端可以通过包含Connection:Keep-Alive 首部请求将一条连接保持在打开状态。
如果服务器愿意为下一条请求将连接保持在打开状态,就在响应中包含相同的首部,如果响应中没有Connection:Keep-Alive 首部,客户端就认为服务器不支持keep-live,会在发回响应报文后关闭连接。

响应中Keep-Alive首部是可选的,但只有在提供Connection:Keep-Alive时才能使用它。
Connection:Keep-Alive
Keep-Alive:max=5,timeout=120
这个例子说明了服务器最多还会为另外5个事务保持连接的打开状态,或者将打开状态保持到连接空闲了2分钟以后。
注意:
1 在HTTP/1.0中,keep-alive并不是默认使用的。客户端必需发送一个Connection:Keep-Alive 请求首部来激活keep-alive连接。
2 如果服务器愿意为下一条请求将连接保持在打开状态,就在响应中包含相同的首部,如果响应中没有Connection:Keep-Alive 首部,客户端就认为服务器不支持keep-live,会在发回响应报文后关闭连接。
3 只有在无需检测到连接的关闭就可以确定报文实体主体部分长度的情况下,才能将连接保持在打开状态--也就是说实体的主体部分必需有正确的Content-Length,
有多部件媒体类型(multipart/form-data ? 有boundary)或者用分块传输编码的方式进行了编码。在一条keep-live信道中回送错误的Content-Length是很糟糕的事情,这样的话,事务处理的另一端就无法精确地检测出一条报文的结束和另一条报文的开始了。
HTTP/1.1 持久连接 Persistent Connection
HTTP/1.1逐渐停止了对keep-alive连接的支持,用一种名为持久连接的改进型设计取代了它。持久连接的目的与keep-alive连接的目的相同,但是工作机制更优些。HTTP/1.1就吃连接在默认情况下是激活的,除非特别指明,否则HTTP/1.1假定所有的连接都是持久的,要在事务处理结束之后将连接关闭,HTTP/1.1应用程序必须向报文中显示地添加一个Connection:close首部。
HTTP1.1客户端加载在收到响应后,除非响应中包含了Connection:close首部,不然HTTP/1.1连接就仍然维持在打开状态。但是,客户端和服务器仍然可以随时关闭空闲的连接。不发送Connection:close并不意味这服务器承诺永远将连接保持在打开状态。
注意:
1 只有当连接所有的报文都有正确的、自定义报文长度时,也就是说,实体主体部分的长度都和相应的Content-Length一致,或者用分块传输编码方式编码的,连接诶才能持久保持。
2 如果客户端不想在连接上发送其他请求了,就应该在最后一条请求中发送一个Connection:close请求首部
管道化连接
HTTP/1.1允许在持久连接上可选的使用请求管道。是相对于keep-alive连接的又一性能优化。在响应到达之前,可以将多条请求放入队列,当第一条请求通过网络流向服务器时,第二条和第三条请求也可以开始发送了。在高时延网络条件下,这样做可以降低网络的环回时间,提高性能。
对管道连接的说明:
1)如果HTTP客户端无法确认连接是持久的,就不应该使用管道
2)必须按照与请求相同的顺序回送HTTP响应。
3)HTTP客户端必须做好连接会在任意时刻关闭的准备,还要准备好重发所有未完成管道化的请求。
4)出错的时候,管道连接会阻碍客户端了解服务器执行的是一些列管道化请求中的哪一些。由于无法安全地重试POST这样的非幂请求,所以出错时,就存在某些方法永远不会被执行的风险。
HTTP/1.1 持久连接 persistent connection的更多相关文章
- HTTP实现长连接(TTP1.1和HTTP1.0相比较而言,最大的区别就是增加了持久连接支持Connection: keep-alive)
HTTP实现长连接 HTTP是无状态的 也就是说,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接.如果客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web ...
- asp.net signalR 专题—— 第二篇 对PersistentConnection持久连接的快速讲解
上一篇我们快速的搭建了一个小案例,但是并没有对其中的方法进行介绍,这一篇我来逐一解析下. 一:从override的那些方法说起 不管怎么样,我们先上代码,如下: public class MyConn ...
- HTTP - 持久连接
Web 客户端经常会打开到同一个站点的连接.比如,一个 Web 页面上的大部分内嵌图片通常都是来自同一个 Web 站点,而且相当一部分指向其他对象的超链接通常都指向同一个站点.因此,初始化了对某服务器 ...
- HTTP的长连接(持久连接)和短连接
HTTP的长连接和短连接 本文总结&分享网络编程中涉及的长连接.短连接概念. 关键字:Keep-Alive,并发连接数限制,TCP,HTTP 一.什么是长连接 HTTP1.1规定了默认保持 ...
- HTTP要点概述:五,HTTP的无状态性,持久连接,Cookie
一,HTTP的无状态性: HTTP 是一种不保存状态,无状态(stateless)协议.HTTP 协议自身不对请求和响应之间的通信状态进行保存.也就是说在 HTTP 这个级别,协议对于发送过的请求或响 ...
- Httpd服务入门知识-Httpd服务常见配置案例之配置持久连接
Httpd服务入门知识-Httpd服务常见配置案例之配置持久连接 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看默认的持久连接时间 [root@node101.yinzhe ...
- HTTP之持久连接
HTTP/1.1 允许 HTTP 设备在事务处理结束之后将 TCP 连接保持在打开状态,以便为未来的 HTTP 请求重用现存的连接.在事务处理结束后仍然保持在打开状态的 TCP 连接被称为持久连接.非 ...
- 有关[Http持久连接]的一切,撕碎给你看
上文中我的结论是: HTTP Keep-Alive 是在应用层对TCP连接进行滑动续约复用, 如果客户端/服务器稳定续约,就成了名副其实的长连接. 目前所有的Http网络库都默认开启了HTTP Kee ...
- WebSocket 是什么原理?为什么可以实现持久连接?
https://www.zhihu.com/question/20215561 作者:Ovear链接:https://www.zhihu.com/question/20215561/answer/ ...
随机推荐
- Swift类型转换
关于「类型转换」(Type Casting),<The Swift Programming Language>描述如下: Type casting is a way to check th ...
- MongoDB复制集高可用选举机制(三)
复制集高可用选举机制 在上一章介绍了MongoDB的架构,复制集的架构直接影响着故障切换时的结果.为了能够有效的故障切换,请确保至少有一个节点能够顺利升职为主节点.保证在拥有核心业务系统的数据中心中拥 ...
- c和c++字符串分割
1.c++版本,第一个参数为待分割的字符串 , 第二个参数为分割字符串 std::vector<std::string> split(const std::string& s, c ...
- bzoj 4260 Codechef REBXOR——trie树
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=4260 一段的异或和就是两个前缀的异或和.正反扫两边,用trie树算每个位置为左/右端点时最大 ...
- Linux设备驱动之Kobject、Kset
作者:lizuobin(也是我们兼职的论坛答疑助手) 原文: https://blog.csdn.net/lizuobin2/article/details/51523693 纠结又纠结,虽然看了一些 ...
- Spark Streaming之二:StreamingContext解析
1.1 创建StreamingContext对象 1.1.1通过SparkContext创建 源码如下: def this(sparkContext: SparkContext, batchDurat ...
- spark学习之IDEA配置spark并wordcount提交集群
这篇文章包括以下内容 (1)IDEA中scala的安装 (2)hdfs简单的使用,没有写它的部署 (3) 使用scala编写简单的wordcount,输入文件和输出文件使用参数传递 (4)IDEA打包 ...
- 【网络爬虫】【java】微博爬虫(四):数据处理——jsoup工具解析html、dom4j读写xml
之前提到过,对于简单的网页结构解析,可以直接通过观察法.手工写正则解析,可以做出来,比如网易微博.但是对于结构稍微复杂点的,比如新浪微博,如果还用正则,用眼睛一个个去找,未免太麻烦了. 本文介绍两个工 ...
- 【Linux学习】Linux用户管理2—用户配置文件
Linux用户管理2-用户配置文件 /etc/passwd: 存放系统用户的文件 输入 vi /etc/passwd /etc/shadow: 保存保密文件 /etc/group: 群组文件 输入 v ...
- WeFlow 简单使用教程
一.前言 WeFlow 是什么?一个高效.强大.跨平台的前端开发工作流工具.(官网定义),下载那些你们都知道,我就不一 一介绍了.下面我说一下简单使用: 二.使用教程 首先,我们使用 WeFlow 是 ...