前世今生:Hive、Shark、spark SQL
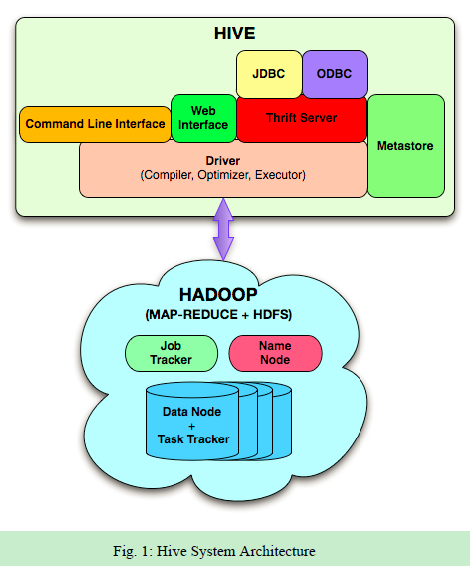
Apache Hive是一个构建在Hadoop上的数据仓库框架,它提供数据的概要信息、查询和分析功能。最早是Facebook开发的,现在也被像Netflix这样的公司使用。Amazon维护了一个为自己定制的分支。
- 加速用的索引功能(有什么特别的?)
- 不同的存储类型文件,例如plain text, RCFile, HBase, ORC, and others.
- 元数据保存在关系数据库中,默认是(Apache Derbydatabase),可替换为Mysql等;
- 可对hadoop生态系统的压缩数据操作,支持多种算法:gzip, bzip2, snappy, etc.
- 内置UDF(自定义函数)
- 类SQL查询,是转换为Mapreduce执行的。
Shark将停止开发,而Spark SQL将取代并兼容Shark 0.9的所有功能,并提供额外的功能。
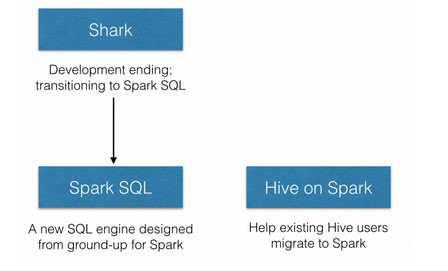
- 性能不佳;
- 为了执行交互查询,需要部署昂贵且私有的数据仓库,且这些数据仓库(EDWs )需要严格而冗长的ETL处理。
前世今生:Hive、Shark、spark SQL的更多相关文章
- Hive、Spark SQL、Impala比较
Hive.Spark SQL.Impala比较 Hive.Spark SQL和Impala三种分布式SQL查询引擎都是SQL-on-Hadoop解决方案,但又各有特点.前面已经讨论了Hi ...
- Spark SQL读取hive数据时报找不到mysql驱动
Exception: Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "BoneC ...
- spark SQL概述
Spark SQL是什么? 何为结构化数据 sparkSQL与spark Core的关系 Spark SQL的前世今生:由Shark发展而来 Spark SQL的前世今生:可以追溯到Hive Spar ...
- Spark SQL概念学习系列之Spark SQL概述
很多人一个误区,Spark SQL重点不是在SQL啊,而是在结构化数据处理! Spark SQL结构化数据处理 概要: 01 Spark SQL概述 02 Spark SQL基本原理 03 Spark ...
- Spark SQL官方文档阅读--待完善
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
- Spark SQL | 目前Spark社区最活跃的组件之一
Spark SQL是一个用来处理结构化数据的Spark组件,前身是shark,但是shark过多的依赖于hive如采用hive的语法解析器.查询优化器等,制约了Spark各个组件之间的相互集成,因此S ...
- Spark SQL 之 Data Sources
#Spark SQL 之 Data Sources 转载请注明出处:http://www.cnblogs.com/BYRans/ 数据源(Data Source) Spark SQL的DataFram ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL 之 Migration Guide
Spark SQL 之 Migration Guide 支持的Hive功能 转载请注明出处:http://www.cnblogs.com/BYRans/ Migration Guide 与Hive的兼 ...
随机推荐
- 数组去重-----js 判断字符串中是否包含某个字符串indexOf
判断obj对象是否在arr数组里面,是返回true const dealArray = (arr, obj) => { Array.prototype.S = String.fromCharCo ...
- 解决:Nginx访问静态页面出现中文乱码
需要修改nginx的server的配置内容,增加一行:charset utf-8; 详情如下: upstream you.domainName.com { server 127.0.0.1:8080; ...
- REST easy with kbmMW #1
kbmMW 5.0支持REST服务器的开发,并且非常简单,下面看看如何实作一个REST服务器. 首先我们制作一个服务器应用程序,增加一个简单的Form,并放置kbmMW组件. 在Delphi中单击Fi ...
- Linux(CentOS)下编译安装apache
Centos7.6系统 已经安装lnmp一键环境 想装个apache跑php7 (php7的安装以及与apache的交互在这里: https://www.cnblogs.com/lz0925/p/11 ...
- Linux sed命令 -- 三剑客老二
格式: sed [OPTION]... {script-only-if-no-other-script} [input-file]... sed [OPTION]... ‘地址定界+[高级]编辑命令’ ...
- eclipse集成springboot 插件(离线安装,含解决Cannot complete the install because one or more required items could)
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/li18310727696/article/details/81071002首先,确认eclipse的 ...
- Yii2常用操作
获取添加或修改成功之后的数据id $insert_id = $UserModel->attributes['id']; 执行原生sql $list = Yii::$app->db-> ...
- BZOJ2238 Mst[最小生成树+树剖+线段树]
跑一遍mst.对于非mst上的边,显然删掉不影响. 如果删边在树上,相当于这时剩下两个连通块.可以证明要重新构成mst只需要再加一条连接两个连通块的最小边,不会证,yy一下,因为原来连通块连的边权和已 ...
- MySQL 将数据文件分布到不同的磁盘
https://blog.csdn.net/john_chang11/article/details/51783632 [root@test1 temp]# vi /etc/my.cnf [mysql ...
- TXNLP 20-33
文本处理的流程 # encoding=utf-8 import jieba import warnings # 基于jieba的分词 seg_list = jieba.cut("贪心学院专注 ...