前世今生:Hive、Shark、spark SQL
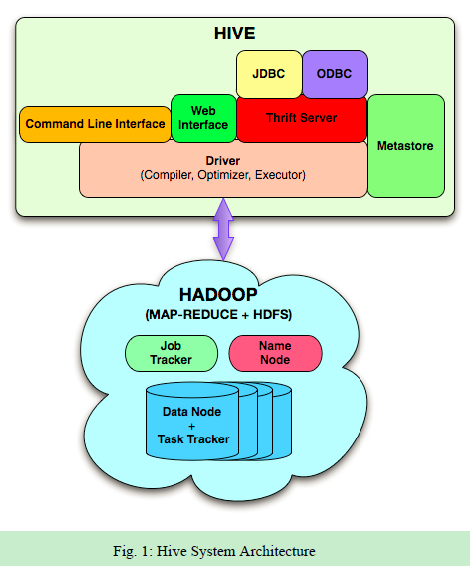
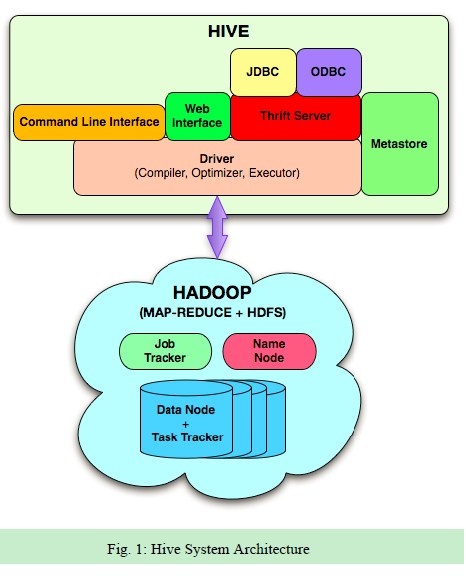
Apache Hive是一个构建在Hadoop上的数据仓库框架,它提供数据的概要信息、查询和分析功能。最早是Facebook开发的,现在也被像Netflix这样的公司使用。Amazon维护了一个为自己定制的分支。
- 加速用的索引功能(有什么特别的?)
- 不同的存储类型文件,例如plain text, RCFile, HBase, ORC, and others.
- 元数据保存在关系数据库中,默认是(Apache Derbydatabase),可替换为Mysql等;
- 可对hadoop生态系统的压缩数据操作,支持多种算法:gzip, bzip2, snappy, etc.
- 内置UDF(自定义函数)
- 类SQL查询,是转换为Mapreduce执行的。
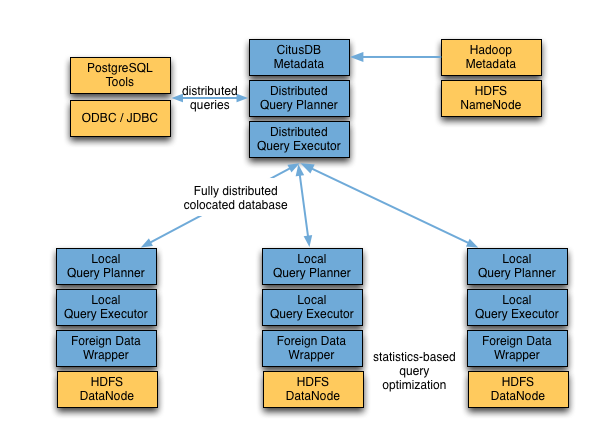
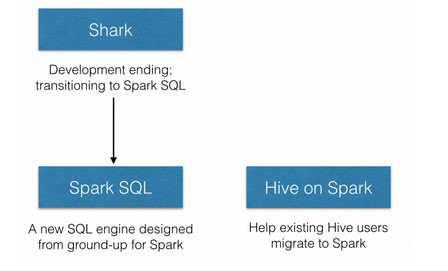
Shark将停止开发,而Spark SQL将取代并兼容Shark 0.9的所有功能,并提供额外的功能。
- 性能不佳;
- 为了执行交互查询,需要部署昂贵且私有的数据仓库,且这些数据仓库(EDWs )需要严格而冗长的ETL处理。
前世今生:Hive、Shark、spark SQL的更多相关文章
- Hive、Spark SQL、Impala比较
Hive.Spark SQL.Impala比较 Hive.Spark SQL和Impala三种分布式SQL查询引擎都是SQL-on-Hadoop解决方案,但又各有特点.前面已经讨论了Hi ...
- Spark SQL读取hive数据时报找不到mysql驱动
Exception: Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "BoneC ...
- spark SQL概述
Spark SQL是什么? 何为结构化数据 sparkSQL与spark Core的关系 Spark SQL的前世今生:由Shark发展而来 Spark SQL的前世今生:可以追溯到Hive Spar ...
- Spark SQL概念学习系列之Spark SQL概述
很多人一个误区,Spark SQL重点不是在SQL啊,而是在结构化数据处理! Spark SQL结构化数据处理 概要: 01 Spark SQL概述 02 Spark SQL基本原理 03 Spark ...
- Spark SQL官方文档阅读--待完善
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
- Spark SQL | 目前Spark社区最活跃的组件之一
Spark SQL是一个用来处理结构化数据的Spark组件,前身是shark,但是shark过多的依赖于hive如采用hive的语法解析器.查询优化器等,制约了Spark各个组件之间的相互集成,因此S ...
- Spark SQL 之 Data Sources
#Spark SQL 之 Data Sources 转载请注明出处:http://www.cnblogs.com/BYRans/ 数据源(Data Source) Spark SQL的DataFram ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL 之 Migration Guide
Spark SQL 之 Migration Guide 支持的Hive功能 转载请注明出处:http://www.cnblogs.com/BYRans/ Migration Guide 与Hive的兼 ...
随机推荐
- Docker 容器数据卷(Data Volume)与数据管理
卷(Volume)是容器中的一个数据挂载点,卷可以绕过联合文件系统,从而为Docker 提供持久数据,所提供的数据还可以在宿主机-容器或多个容器之间共享.通过卷,我们可以可以使修改数据直接生效,而不必 ...
- mint-ui下拉加载min和上拉刷新(demo实例)
<template> <div class="share"> <div class="header"> <div cl ...
- Qt常用的登录界面设计
记录一下Qt常用的登录界面的设计 方便以后使用! 1.QpushButton改变一个按钮的颜色,当鼠标放上去和移开时显示不同的颜色.QPushButton { background-color: rg ...
- windows 下Nginx 入门
验证配置是否正确: nginx -t 查看Nginx的版本号:nginx -V 启动Nginx:start nginx 快速停止或关闭Nginx:nginx -s stop 正常停止或关闭Nginx: ...
- odoo标识符
class Book(models.Model): _name = "library.book" _description = "Book" _order = ...
- 网络初级篇之STP(实验验证)
一.根桥的选举. 1.优先级相等时. (图1-1) (图1-2) 在上面1-1图中,已经标出桥的mac地址,桥的优先级为默认优先级(缺省:32768).任意一端口抓包,查看STP数据包内包含的信息,根 ...
- Java 通过Math.random() 生成6位随机数
public static void main(String[] args) { String sjs=""; for (int i = 0; i < 6; i++) { i ...
- STM32WB 信息块之OTP
1.OTP Area范围:0x1FFF 7000 - 0x1FFF 73FF 大小1 K 2.OTP描述 1 KB (128 double words) OTP (one-time programma ...
- PhotoShop更改图片背景色
PhotoShop更改图片背景色 操作步骤如下所示: 打开图片==>图像/调整/替换颜色==>选择颜色==>选择油漆桶工具==>点击需要被替换的图片背景色 注:不知道什么原因 ...
- 5.NIO_ Selector选择器
1.阻塞与非阻塞 传统的 IO 流都是阻塞式的.也就是说,当一个线程调用 read() 或 write() 时,该线程被阻塞,直到有一些数据被读取或写入, 该线程在此期间不能执行其他任务因此,在完成网 ...