Deep Learning系统实训之一:深度学习基础知识
K-近邻与交叉验证
1 选取超参数的正确方法是:将原始训练集分为训练集和验证集,我们在验证集上尝试不同的超参数,最后保留表现最好的那个。
2 如果训练数据量不够,使用交叉验证法,它能帮助我们在选取最优超参数的时候减少噪音。
3 一旦找到最优的超参数,就让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法。
4 最近邻分类器能够在CIFAR-10上得到将近40%的准确率。该算法简单易实现,但需要存储所有训练数据,并且在测试时过于消耗计算能力。
5 最后,我们知道了仅仅使用L1和L2范数来进行像素比较是不够的,图像更多的是按照背景和颜色被分类,而不是语义主体本身。
1 预处理你的数据:对你数据中的特征进行归一化(normalize),让其具有零平均值(zero mean)和单位方差(unit variance)。
2 如果数据是高维数据,考虑使用降维方法。如PCA。
3 将数据随机分入训练集和验证集。按照一般规律,70%-90%数据作为训练集。
4 在验证集上调优,尝试足够多的K值,尝试L1和L2两种范数计算方式。
超参数(曼哈顿距离与欧氏距离):

损失函数:
任何一个算法都会有一个损失函数。
我们希望损失为零,为什么呢?损失越多说明我们错的越多,损失为零说明我们没做错啊。o(* ̄︶ ̄*)o

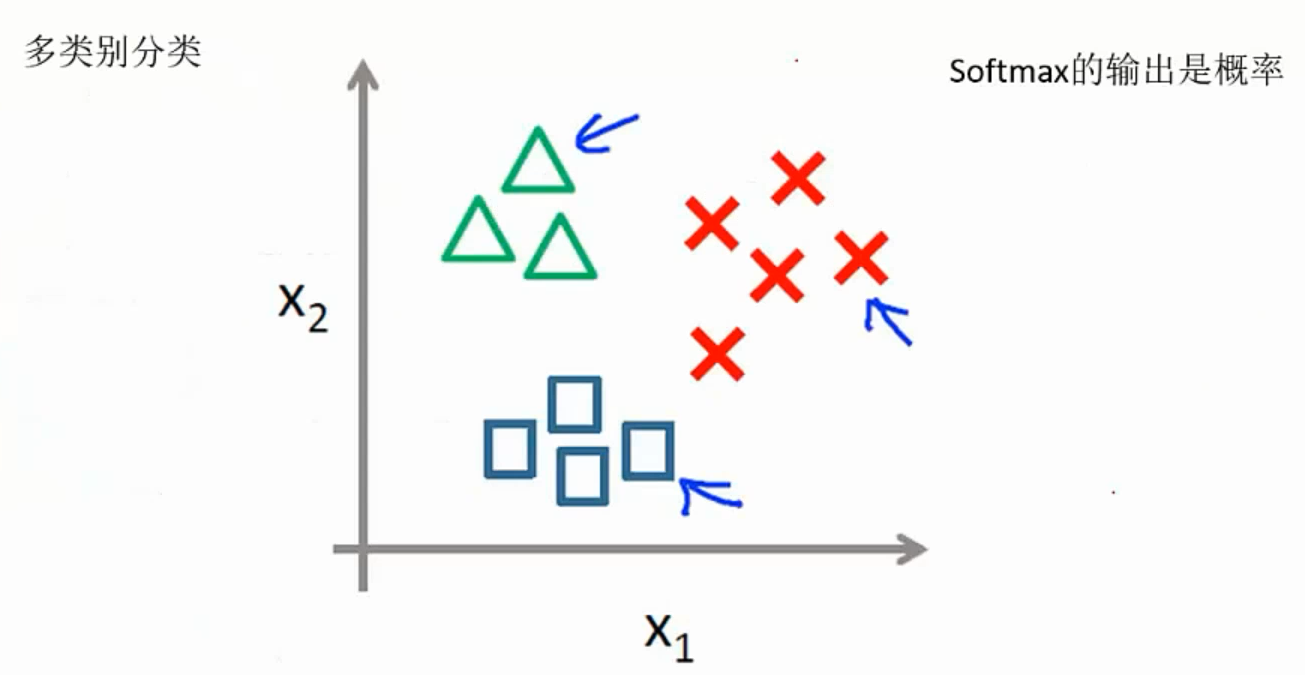
Softmax分类器:
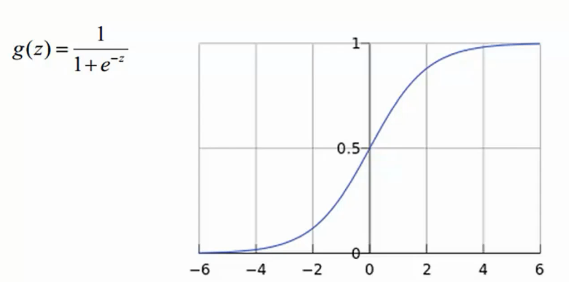
Sigmoid函数:

softmax实例:

Deep Learning系统实训之一:深度学习基础知识的更多相关文章
- Deep Learning系统实训之三:卷积神经网络
边界填充(padding):卷积过程中,越靠近图片中间位置的像素点越容易被卷积计算多次,越靠近边缘的像素点被卷积计算的次数越少,填充就是为了使原来边缘像素点的位置变得相对靠近中部,而我们又不想让填充的 ...
- Deep Learning系统实训之二:梯度下降原理
基本概念理解: 一个epoch:当前所有数据都跑(迭代)了一遍: 那么两个epoch,就是把所有数据跑了两遍,三个epoch就是把所有数据跑了三遍,以此类推. batch_size:每次迭代多少个数据 ...
- 吴恩达《深度学习》-课后测验-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-Week 1 - Practical aspects of deep learning(第一周测验 - 深度学习的实践)
Week 1 Quiz - Practical aspects of deep learning(第一周测验 - 深度学习的实践) \1. If you have 10,000,000 example ...
- Predicting effects of noncoding variants with deep learning–based sequence model | 基于深度学习的序列模型预测非编码区变异的影响
Predicting effects of noncoding variants with deep learning–based sequence model PDF Interpreting no ...
- deep learning framework(不同的深度学习框架)
常用的deep learning frameworks 基本转自:http://www.codeceo.com/article/10-open-source-framework.html 1. Caf ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
- 算法工程师<深度学习基础>
<深度学习基础> 卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构, ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
随机推荐
- C#.Net 持久化对象为XML文件
</pre><pre code_snippet_id="613717" snippet_file_name="blog_20150307_1_57950 ...
- String转换为Map
Map<String,Integer> rulsMap = new Gson().fromJson(cachedobj.toString(),new TypeToken<Map< ...
- Kafka工作原理解析以及主要配置详解
Kafka工作原理解析以及主要配置详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zookeeper集群保 ...
- 离线方式部署Ambari2.6.0.0
Hadoop生态圈-离线方式部署Ambari2.6.0.0 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我现在所在的公司用的是CDH管理Hadoop集群,前端时间去面试时发现很多 ...
- Windows环境墙内搭建Go语言集成开发环境
1 安装go环境 太简单略 2 安装vs code 找到微软的官方网站,下载Visual Studio Code,官网地址https://code.visualstudio.com/ 安装完成后进入V ...
- js 格式化时间、字符串指定长度、随机字符串
格式化字符串长度 方法 function formatWidth(str, width){ str += '' if(str.length<width) '+str, width) else r ...
- 20155215 2016-2017-2 《Java程序设计》第9周学习总结
20155215 2016-2017-2 <Java程序设计>第9周学习总结 教材学习内容总结 第十六章 JDBC入门 - JDBC(Java DataBase Connectivity) ...
- SEO之robots.txt
[关键词:robot.txt,sitemap,User-Agent,Disallow,Allow][声明:摘自Wikipedia] 1. 定义:robots.txt(统一小写)是一种存放于网站根目录下 ...
- 【洛谷P1896【SCOI2005】】互不侵犯King
题目描述 在N×N的棋盘里面放K个国王,使他们互不攻击,共有多少种摆放方案.国王能攻击到它上下左右,以及左上左下右上右下八个方向上附近的各一个格子,共8个格子. 输入输出格式 输入格式: 只有一行,包 ...
- 【文件】java生成PDF文件
package test; import java.awt.Color; import java.io.FileOutputStream; import org.junit.Test; import ...