中文多分类 BERT
直接把自己的工作文档导入的,由于是在外企工作,所以都是英文写的
Steps:
- git clone https://github.com/google-research/bert
- prepare data, download pre-trained models
- modify code in run_classifier.py
- add a new processor

- add the processor in main function

Train and predict
- train
python run_classifier.py \
--task_name=multiclass \
--do_train=true \
--do_eval=true \
--data_dir=/home/wxl/bertProject/bertTextClassification/data\
--vocab_file=/home/wxl/bertProject/chinese_L-12_H-768_A-12/vocab.txt \
--bert_config_file=/home/wxl/bertProject/chinese_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=/home/wxl/bertProject/chinese_L-12_H-768_A-12/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=16 \
--learning_rate=2e-5 \
--num_train_epochs=100.0 \
--output_dir=/home/wxl/bertProject/bertTextClassification/outputThree/
you would get the following result if success:
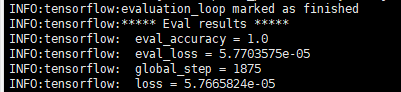
- predict
python run_classifier.py \
--task_name=multiclass \
--do_predict=true \
--data_dir=/home/wxl/bertProject/bertTextClassification/data\
--vocab_file=/home/wxl/bertProject/chinese_L-12_H-768_A-12/vocab.txt \
--bert_config_file=/home/wxl/bertProject/chinese_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=/home/wxl/bertProject/bertTextClassification/outputThreeV1 \
--max_seq_length=128 \
--output_dir=/home/wxl/bertProject/bertTextClassification/mulitiPredictThreeV1/
中文多分类 BERT的更多相关文章
- colab上基于tensorflow2.0的BERT中文多分类
bert模型在tensorflow1.x版本时,也是先发布的命令行版本,随后又发布了bert-tensorflow包,本质上就是把相关bert实现封装起来了. tensorflow2.0刚刚在2019 ...
- 利用CNN进行中文文本分类(数据集是复旦中文语料)
利用TfidfVectorizer进行中文文本分类(数据集是复旦中文语料) 利用RNN进行中文文本分类(数据集是复旦中文语料) 上一节我们利用了RNN(GRU)对中文文本进行了分类,本节我们将继续使用 ...
- Chinese-Text-Classification,用卷积神经网络基于 Tensorflow 实现的中文文本分类。
用卷积神经网络基于 Tensorflow 实现的中文文本分类 项目地址: https://github.com/fendouai/Chinese-Text-Classification 欢迎提问:ht ...
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 基于Text-CNN模型的中文文本分类实战
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 利用RNN进行中文文本分类(数据集是复旦中文语料)
利用TfidfVectorizer进行中文文本分类(数据集是复旦中文语料) 1.训练词向量 数据预处理参考利用TfidfVectorizer进行中文文本分类(数据集是复旦中文语料) ,现在我们有了分词 ...
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- CNN在中文文本分类的应用
深度学习近一段时间以来在图像处理和NLP任务上都取得了不俗的成绩.通常,图像处理的任务是借助CNN来完成的,其特有的卷积.池化结构能够提取图像中各种不同程度的纹理.结构,并最终结合全连接网络实现信息的 ...
- hugging face-基于pytorch-bert的中文文本分类
1.安装hugging face的transformers pip install transformers 2.下载相关文件 字表: wget http://52.216.242.246/model ...
随机推荐
- babel的使用及babel与gulp结合工作流
Babel 通过语法转换器支持最新版本的 JavaScript . 它有非常多的插件,这些插件能够允许我们立刻使用新语法,无需等待浏览器支持. 那我们怎么使用babel呢? 首先我们来了解babel基 ...
- 求n(n>=2)以内的质数/判断一个数是否质数——方法+细节优化
#include <stdio.h> #include <stdlib.h> //判断i是否质数,需要判断i能否被(long)sqrt(i)以内的数整除 //若i能被其中一个质 ...
- 洛谷 P1020 导弹拦截(dp+最长上升子序列变形)
传送门:Problem 1020 https://www.cnblogs.com/violet-acmer/p/9852294.html 讲解此题前,先谈谈何为最长上升子序列,以及求法: 一.相关概念 ...
- 基于pycaffe的网络训练和结果分析(mnist数据集)
该工作的主要目的是为了练习运用pycaffe来进行神经网络一站式训练,并从多个角度来分析对应的结果. 目标: python的运用训练 pycaffe的接口熟悉 卷积网络(CNN)和全连接网络(DNN) ...
- struts下载
struts下载地址:http://struts.apache.org/download.cgi
- vue资源
Vue中文官网:https://cn.vuejs.org/ Vue源码:https://github.com/vuejs/vue Vue官方工具:https://github.com/vuejs vu ...
- SQL记录-Oracle重命名表名例子
rename table_1 to table_2
- 转--Python语言特性
1 Python的函数参数传递 看两个例子: a = 1 def fun(a): a = 2 fun(a) print a # 1 a = [] def fun(a): a.append(1) fun ...
- Linux下安装mysql(示例mysql5.6安装)
1.首先检查你的linux上是否已经安装了mysql rpm -qa|grep mysql 2.如果mysql的版本不是想要的版本.需要把mysql卸载 yum remove mysql mysql- ...
- webuploader 百度上传,一个页面多个上传按钮
需求:列表里每条数据需加文件上传 html: <div> <ul class="SR_wrap_pic"></ul> <button ty ...