强化学习策略梯度方法之: REINFORCE 算法(从原理到代码实现)
强化学习策略梯度方法之: REINFORCE 算法 (从原理到代码实现)
2018-04-01 15:15:42
最近在看policy gradient algorithm, 其中一种比较经典的算法当属:REINFORCE 算法,已经广泛的应用于各种计算机视觉任务当中。
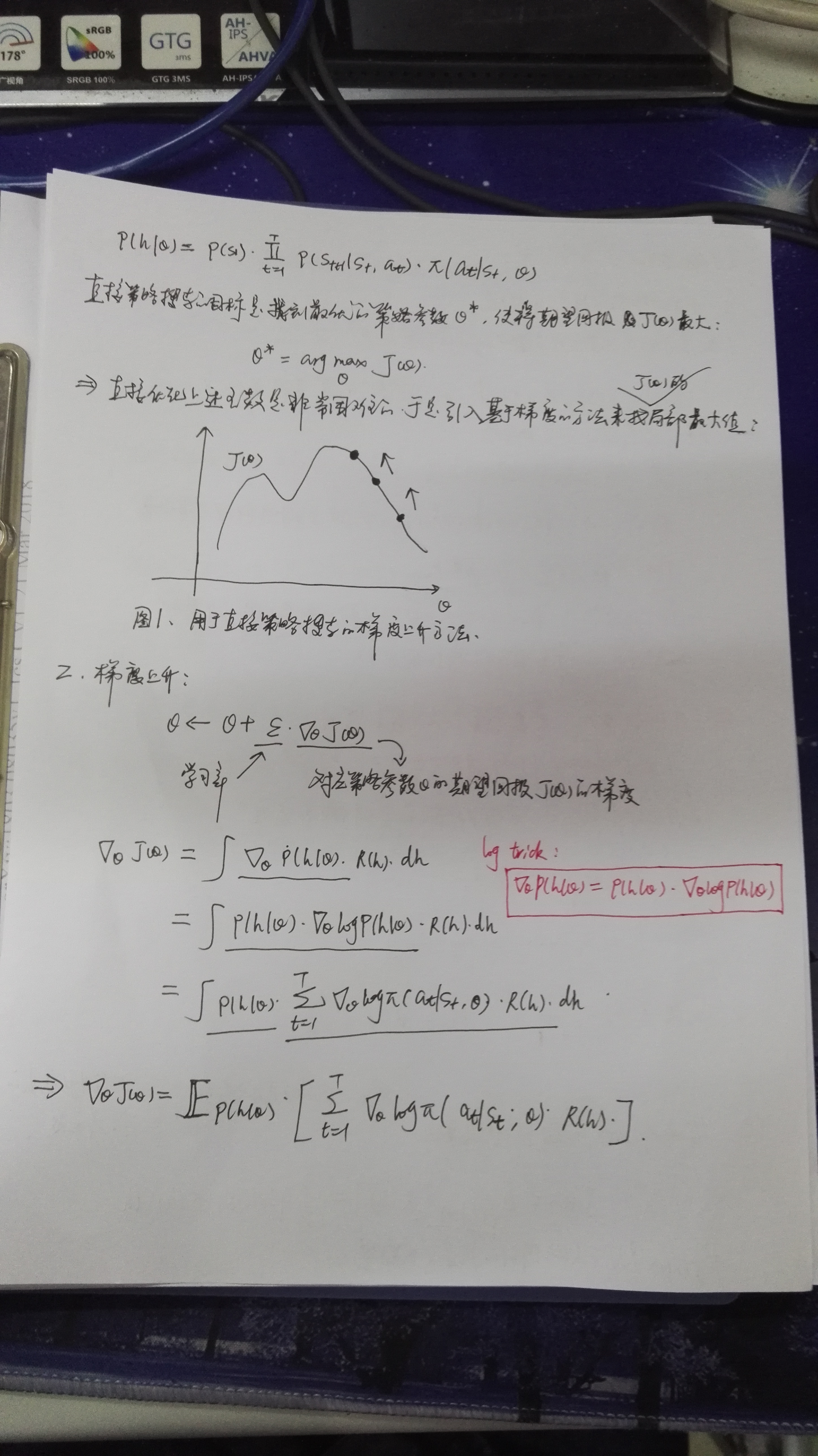
【REINFORCE 算法原理推导】



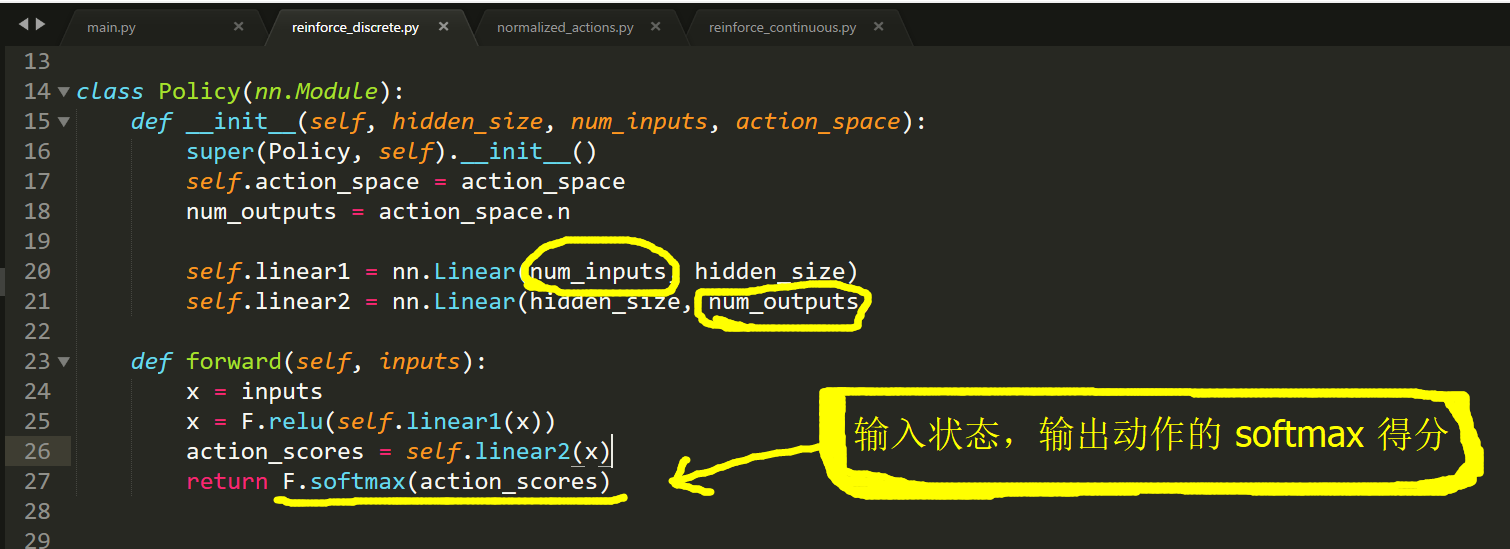
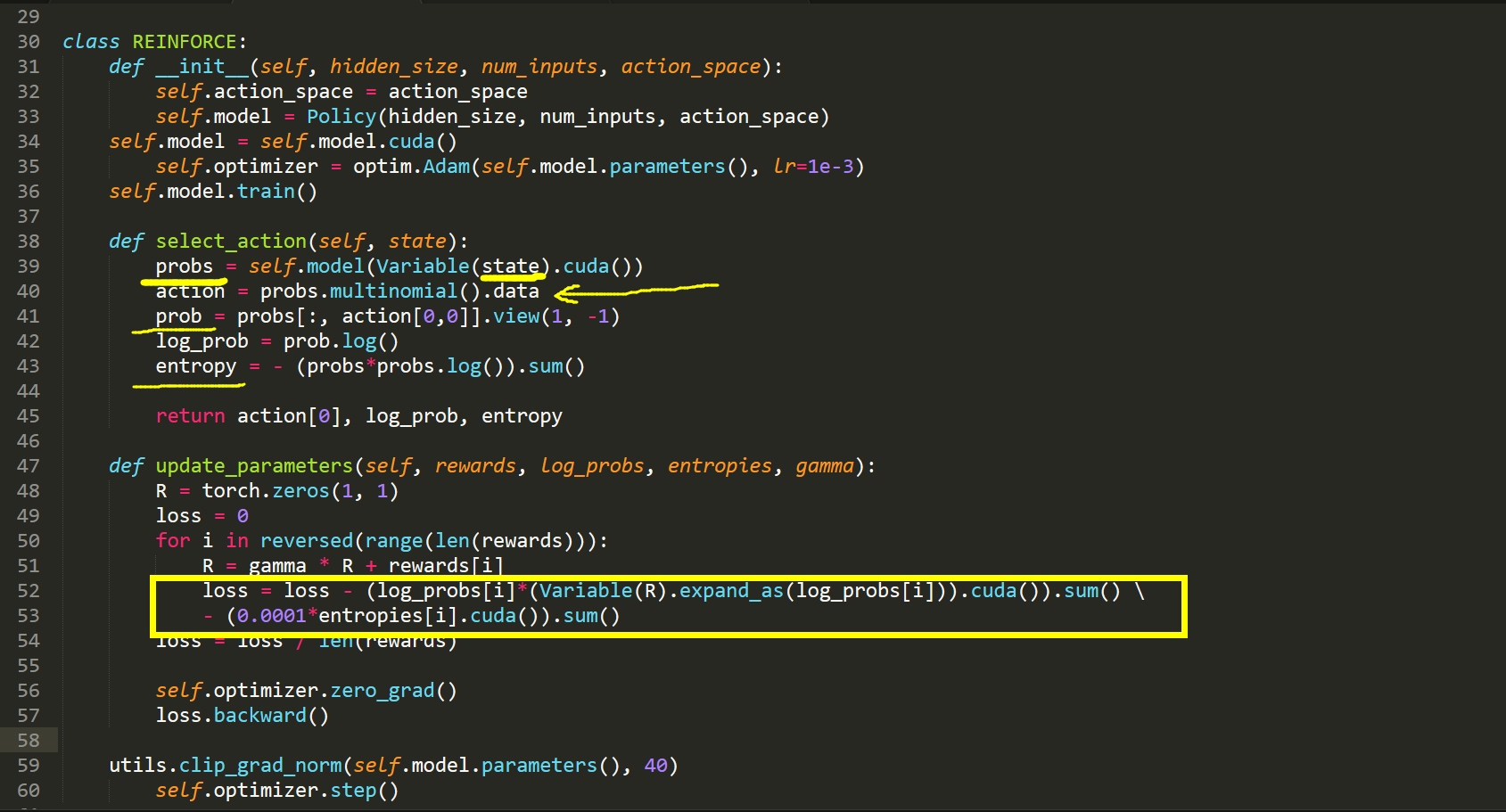
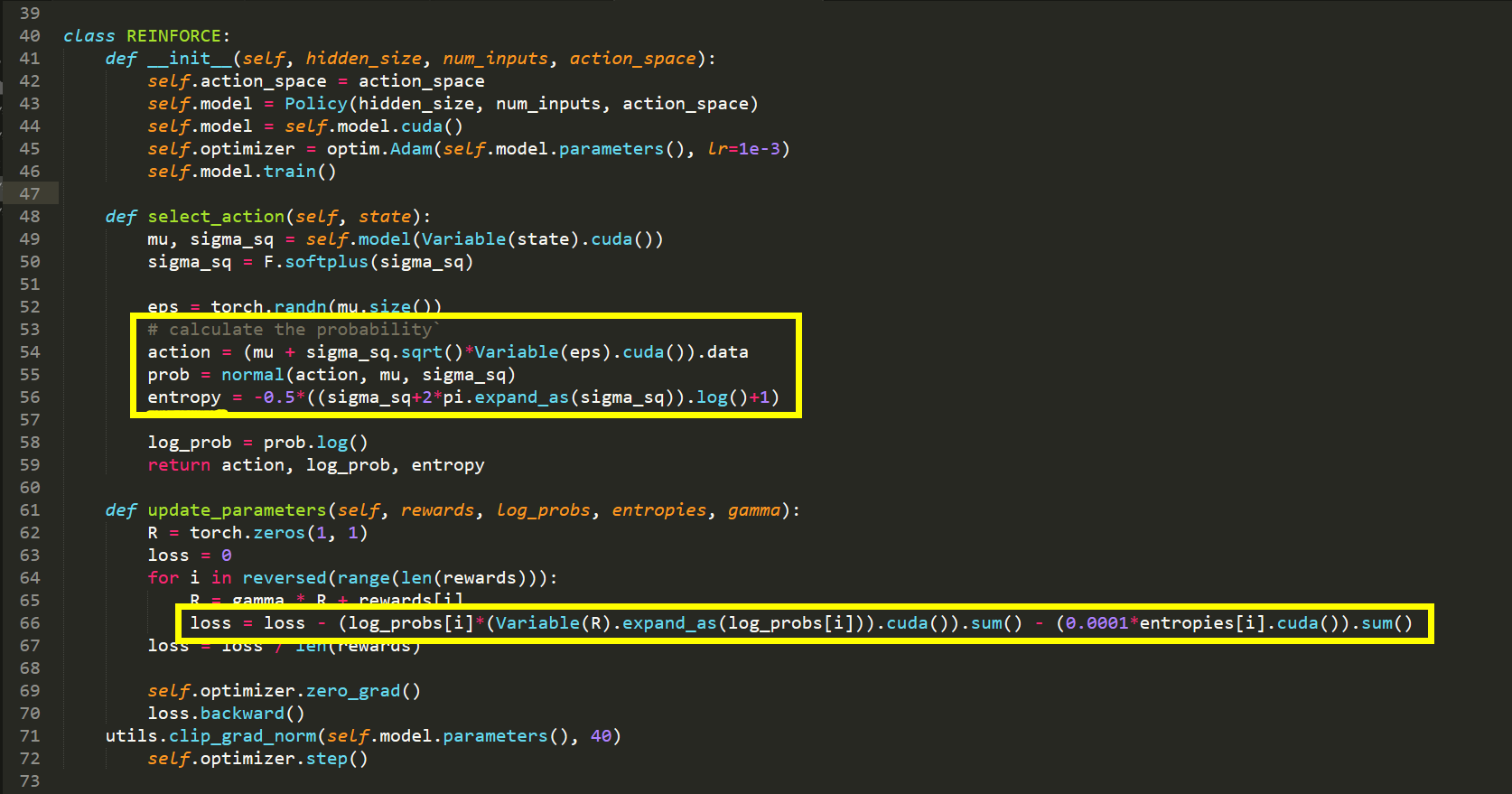
【Pytorch 代码实现】

该图像来自于:https://github.com/JamesChuanggg/pytorch-REINFORCE/blob/master/assets/algo.png
{kind=link}

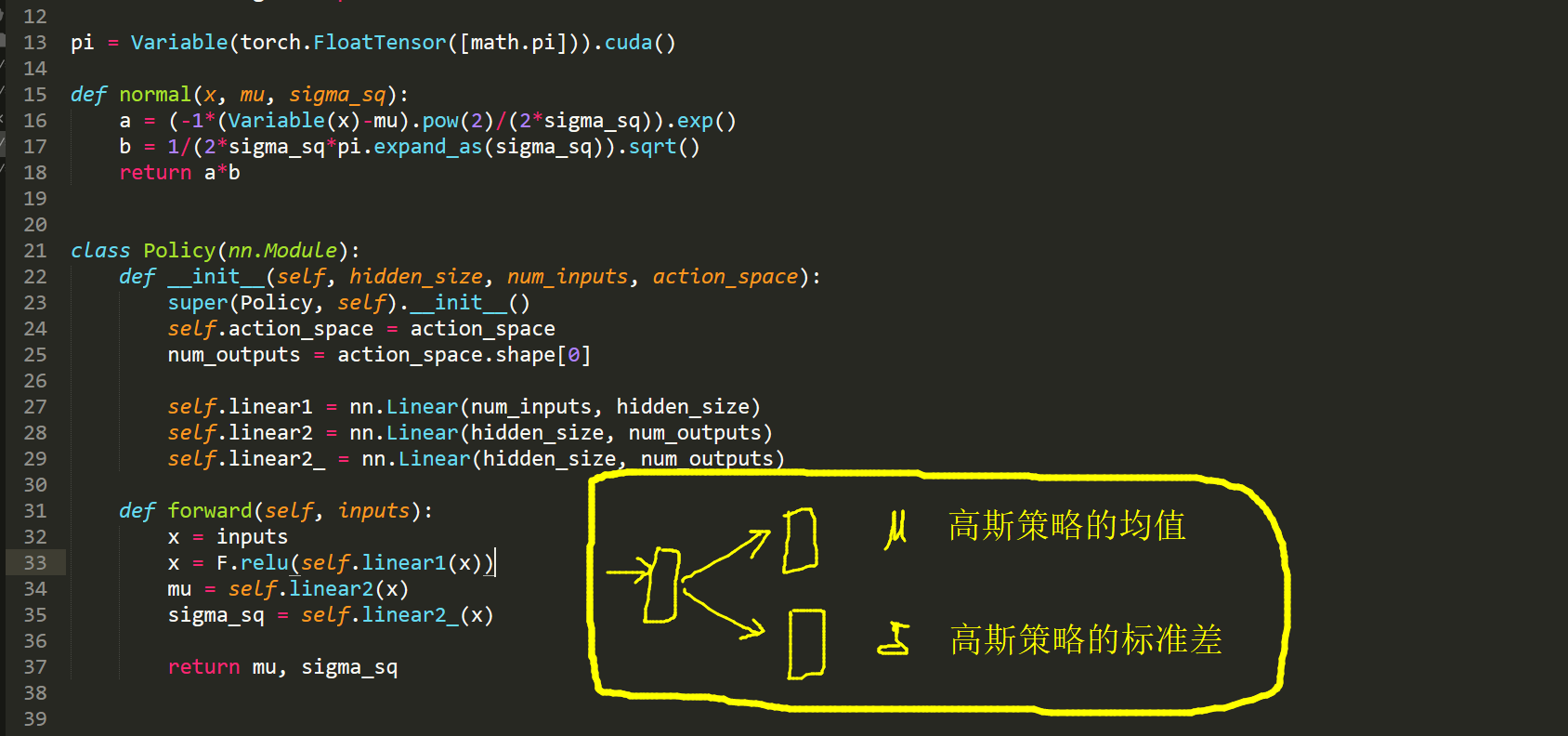
上面函数是 离散情况下的,那么,连续领域是什么情况呢?
-------------------------------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------------------------------
Reference:
1. 参考博文:http://www.tuananhle.co.uk/notes/reinforce.html
2. 参考博文:http://www.scholarpedia.org/article/Policy_gradient_methods
3. 代码实现(Pytorch version)https://github.com/JamesChuanggg/pytorch-REINFORCE
4. REINFORCE 文章链接:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.129.8871&rep=rep1&type=pdf
5. 书籍:Statistical_Reinforcement_Learning
强化学习策略梯度方法之: REINFORCE 算法(从原理到代码实现)的更多相关文章
- js学习笔记之排序算法的原理及代码
冒泡排序 比较任何两个相邻的项,如果第一个比第二个大,则交换它们 重复这样的操作,直到排序完成,具体代码如下: let arr = [67,23,11,89,45,76,56,99] function ...
- BP算法从原理到python实现
BP算法从原理到实践 反向传播算法Backpropagation的python实现 觉得有用的话,欢迎一起讨论相互学习~Follow Me 博主接触深度学习已经一段时间,近期在与别人进行讨论时,发现自 ...
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
- DRL之:策略梯度方法 (Policy Gradient Methods)
DRL 教材 Chpater 11 --- 策略梯度方法(Policy Gradient Methods) 前面介绍了很多关于 state or state-action pairs 方面的知识,为了 ...
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- 强化学习中REIINFORCE算法和AC算法在算法理论和实际代码设计中的区别
背景就不介绍了,REINFORCE算法和AC算法是强化学习中基于策略这类的基础算法,这两个算法的算法描述(伪代码)参见Sutton的reinforcement introduction(2nd). A ...
- 蜂窝网络TDOA定位方法的Fang算法研究及仿真纠错
科学论文为我们提供科学方法,在解决实际问题中,能极大提高生产效率.但论文中一些失误则可能让使用者浪费大量时间.自己全部再推导那真不容易,怀疑的成本特别高,通常不会选择这条路.而如果真是它的问题,其它所 ...
随机推荐
- php aes128加密
//[加密数据]AES 128 ECB模式 public function aesEncrypt($str){ $screct_key = Yii::$app->params['encryptK ...
- Python 1.安装
Python是一种开源语言,有很多第三方库. 1. Python3 及相关组件下载及安装 a. Python3下载:https://www.python.org/downloads/->点击以下 ...
- 20155228 实验五 Android开发基础
20155228 实验五 Android开发基础 实验内容 1.掌握Socket程序的编写: 2.掌握密码技术的使用: 3.设计安全传输系统. 实验要求 1.没有Linux基础的同学建议先学习< ...
- Ngine X 完全开发指南 读书笔记-前言
一开始接触的编程语言是VF,那是一种可视化编程语言,所谓的可视化,就是运行结果能直接看得到的,非常直观,便于调试,适合刚刚接触编程的新人学习.当时学得懵懂,半知半解,就是感觉程序非常神奇,常常几句代码 ...
- highchart 柱状图,单个样例
var chart = Highcharts.chart('container', { chart: { type: 'column' }, title: { text: '月平均气温' }, sub ...
- Vue2.0,Express实现的简单跨域
https://www.cnblogs.com/kevin-zjy-blog/p/7357220.html 1. 通过jsonp跨域2. document.domain + iframe跨域3. lo ...
- 那些年 Qzone
那些年转在Qzone里的: 不喊痛,不一定没感觉.不要求,不一定没期待.不落泪,不一定没伤痕.不说话,不一定没心声.沉默,不代表自己没话说.离开,不代表自己很潇洒.快乐,不代表自己没伤心.幸福,不代表 ...
- [转载]FlipClock.js时钟,计数,3D翻转插件
1.FlipClock.js能够自动定义计数,时钟的翻牌效果,调用简单,下面简单记录下用法 2.官网地址:http://www.flipclockjs.com/ 3.调用2个文件 <link h ...
- Java Eclipse和MyEclipse快捷键
摘自:http://www.cnblogs.com/lsy131479/p/8487379.html 首先: 常用快捷键 alt+/ - - 万能快捷键 Ctrl+1 - - 快速修复 Eclip ...
- ASCII字符代码表