DRL之:策略梯度方法 (Policy Gradient Methods)
DRL 教材 Chpater 11 --- 策略梯度方法(Policy Gradient Methods)
前面介绍了很多关于 state or state-action pairs 方面的知识,为了将其用于控制,我们学习 state-action pairs 的值,并且将这些值函数直接用于执行策略和选择动作.这种形式的方法称为:action-value methods.
下面要介绍的方法也是计算这些 action (or state) values,但是并非直接用于选择 action, 而是直接表示该策略,其权重不依赖于任何值函数.
1.1 Actor-Critic Methods.
Actor-critic methods 是一种时序查分方法(TD),有一个独立的记忆结构来显示的表示策略,而与 value function 无关.该策略结构称为:actor,因为其用于选择动作,预测的值函数被称为:critic,因为其用于批判 actor 执行的动作.学习是on-policy的: the critic must learn about and critique whatever policy is currently being followed by the actor. The critique takes the form of a TD error. 尺度信号是单纯的 critic 的输出,并且引导 actor and critic 的学习,像下图所示:
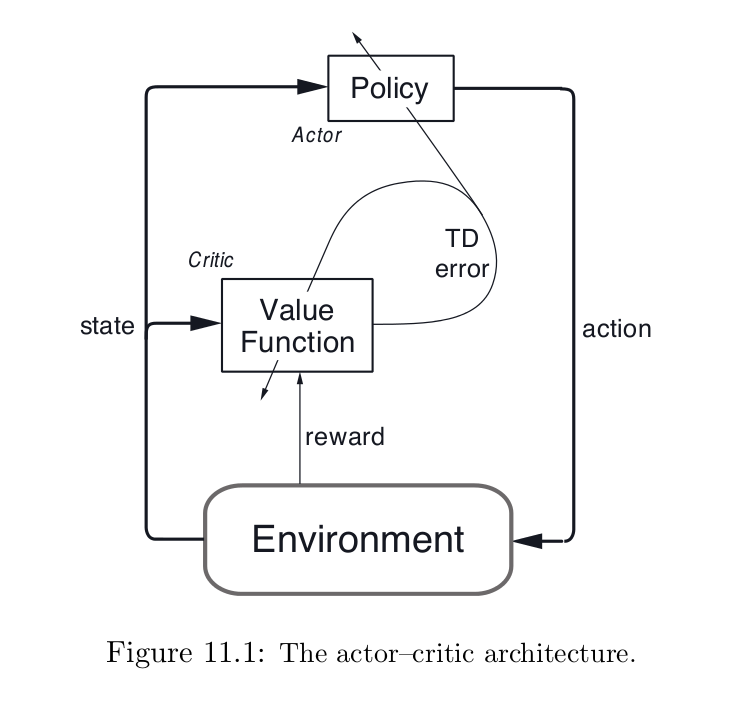
Actor-critic methods 是 gradient-bandit methods自然的拓展到 TD-learning和全部的 RL 学习问题. 通常情况下, the critic 是状态-值函数.再一次的动作选择之后,the critic 评价新的策略来检测是否事情朝着期望的方向发展.评价通常是根据 TD error 得到的:

其中,$V_t$是第 t 时刻 the critic 执行的值函数,TD error可以被用来评价刚刚选择的 action,在状态$S_t$下选择的动作$A_t$.是否TD error是 positive的,这表明若是,则会在将来加强选择该动作的趋势,若是负的,则会降低选择该动作的优先级.假设动作是由 the Gibbs softmax method 产生的:

其中,$H_t(s, a)$是在第 t 时刻由策略参数可改变的 actor 的值,表示在时刻 t 状态 s 下选择每一个动作 a 的趋势(preference).通过增加或者减少 $H_t(S_t, A_t)$ 来调整上述选择,即:

其中 $\beta$是另一个正的步长参数.
这仅仅是 actor-critic method 的案例,另一个变种用另一种方式来选择动作,或者 eligibility traces.另一个共同的地方,像强化对比方法,是为了包括额外的因子来改变证据的量(is to include additional factors varying the amount of credit assigned to the action taken, $A_t$).比如,一个通用的像这样的因子是和选择动作$A_t$相反的关系,得到如下的更新法则:

许多最早的强化学习系统利用的TD方法是 actor-critic methods. 然后,更多的注意力被放在学习动作-值函数(action-value functions) 和 从估计的值来充分的决定一个策略(例如:Sarsa and Q-learning).这个分化也许仅仅是一个历史的偶尔.例如:你可能会想到中间的结构,an action-value function 和 an independent policy 将会被学到.在任何事件当中,actor-critic methods 是为了保持当前的兴趣,由于两个特别明显的优势:
1.他们需要最小的计算量来达到选择动作的目的.考虑一种情况,有许多有限的可能的选择---例如,一个 continuous-valued action.任何方法仅仅学习动作值(action values)必须搜索这个有限的结合,从而实现选择 action 的目的.如果该policy是显示的存储的,接着,对于每一个动作选择可能不需要如此的计算量.
2.他们可以学习一个显示的随机策略;即,他们可以学习选择不同 actions 的最优概率.这个能力被证明在竞争和non-Markov cases 是非常有效的.
此外,在 actor-critic methods 不同的 actor 会使得他们在一些领域更有吸引力,如:生物模型.在一些领域中,可能也更加简单的在允许的策略结合上进行特定领域的约束.
11.2 Eligibility Traces for Actor-Critic Methods
DRL之:策略梯度方法 (Policy Gradient Methods)的更多相关文章
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- Ⅶ. Policy Gradient Methods
Dictum: Life is just a series of trying to make up your mind. -- T. Fuller 不同于近似价值函数并以此计算确定性的策略的基于价 ...
- [Reinforcement Learning] Policy Gradient Methods
上一篇博文的内容整理了我们如何去近似价值函数或者是动作价值函数的方法: \[ V_{\theta}(s)\approx V^{\pi}(s) \\ Q_{\theta}(s)\approx Q^{\p ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
- 强化学习七 - Policy Gradient Methods
一.前言 之前我们讨论的所有问题都是先学习action value,再根据action value 来选择action(无论是根据greedy policy选择使得action value 最大的ac ...
- 强化学习(十三) 策略梯度(Policy Gradient)
在前面讲到的DQN系列强化学习算法中,我们主要对价值函数进行了近似表示,基于价值来学习.这种Value Based强化学习方法在很多领域都得到比较好的应用,但是Value Based强化学习方法也有很 ...
- Policy Gradient Algorithms
Policy Gradient Algorithms 2019-10-02 17:37:47 This blog is from: https://lilianweng.github.io/lil-l ...
- (转)RL — Policy Gradient Explained
RL — Policy Gradient Explained 2019-05-02 21:12:57 This blog is copied from: https://medium.com/@jon ...
- 深度学习-深度强化学习(DRL)-Policy Gradient与PPO笔记
Policy Gradient 初始学习李宏毅讲的强化学习,听台湾的口音真是费了九牛二虎之力,后来看到有热心博客整理的很细致,于是转载来看,当作笔记留待复习用,原文链接在文末.看完笔记再去听一听李宏毅 ...
随机推荐
- 记录一些容易忘记的属性 -- UIButton
//设置按钮文字字体(这个只在自定义button时有效) btn1.titleLabel.font = [UIFont systemFontOfSize:30]; showsTouchWhenH ...
- 指针属性直接赋值 最好先retain 否则内存释放导致crash
//先释放之前的 YK_RELEASE_SAFELY(_selectedDate); //retain新的 _selectedDate = [aDate retain]; NSString 属性的好像 ...
- (转)Eclipse “cannot be resolved to a type” error
原:http://www.cnblogs.com/xuxm2007/archive/2011/10/20/2219104.html Eclipse “cannot be resolved to a t ...
- ERP部门的添加(十一)
功能需求: 1.有部门管理权限的人员进行添加部门基本信息. 2.有部门权限管理的人员查询部门基本信息. 3.有部门权限管理的人员进行修改部门基本信息. 4.在一个页面中实现,使用弹出对话框方式 存储过 ...
- Android之Activity与Service通信
一.当Acitivity和Service处于同一个Application和进程时,通过继承Binder类来实现. 当一个Activity绑定到一个Service上时,它负责维护Service实例的引用 ...
- UITableView详解(2)
承接上文,再续本文 一,首先我们对上次的代码进行改进,需要知道的一点是,滚动视图的时候,我们要创建几个视图,如果一个视图显示一个图片占据整个屏幕,对于滚动视图我们只需要创建三个视图就可以显示几千给图片 ...
- 浏览器关闭使session失效的问题多种解决方式
直接关闭浏览器(或者强制关闭浏览器进程.死机等),服务器无法处理用户退出网站的请求,此举将会导致session失效,下面整理了一些解决方法,感兴趣的朋友可以参考下哈 如果用户不点击网站的“退出”链 ...
- HDU 5086
http://acm.hdu.edu.cn/showproblem.php?pid=5086 求所有连续区间的数字和 本质是一个乘法原理,当前位置的数字出现次数=这个数之前的数字个数*这个数之后的数字 ...
- HDU 4462
http://acm.hdu.edu.cn/showproblem.php?pid=4462 一道题意不清的水题 题意:给一个n*n的格子,在上面放草人,每个草人有恐惧范围,问最少选择几个草人可以覆盖 ...
- 1.NSThread
前言 每个iOS应用程序都有个专门用来更新显示UI界面.处理用户触摸事件的主线程,因此不能将其他太耗时的操作放在主线程中执行,不然会造成主线程堵塞(出现卡机现象),带来极坏的用户体验.一般的解决方案就 ...